

通过例子详细介绍windows下如何往neo4j中导入数据(Load_csv、import)
发布于2019-08-07 11:55 阅读(2711) 评论(0) 点赞(2) 收藏(1)
前言
- 针对人群
初步接触neo4j的小白 - 操作系统
Windows - 数据导入方法
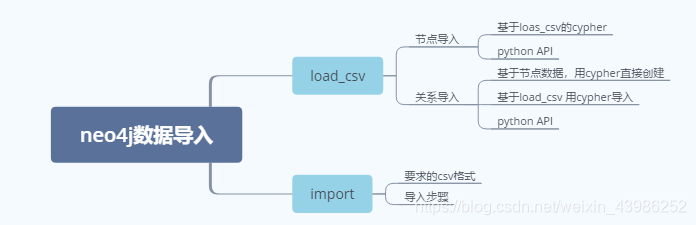
1) load_csv 语句,适合初始化导入或增量更新;
优点:可以实时插入,可加载本地、远程csv ;缺点:速度慢,不能动态传label,relationship
2) neo4j-import,适合海量数据的初始化;
优点:速度快;缺点:需要停止neo4j服务器,清库。 - 本文思维导图
一、数据
1.1 原始数据
import pandas as pd
path="D:\\ProgramData\\Neo4j\\neo4j-community-3.4.8\\import\\"# neo4j 数据导入的根目录
data=pd.read_csv(path+"data.csv")
- 1
- 2
- 3
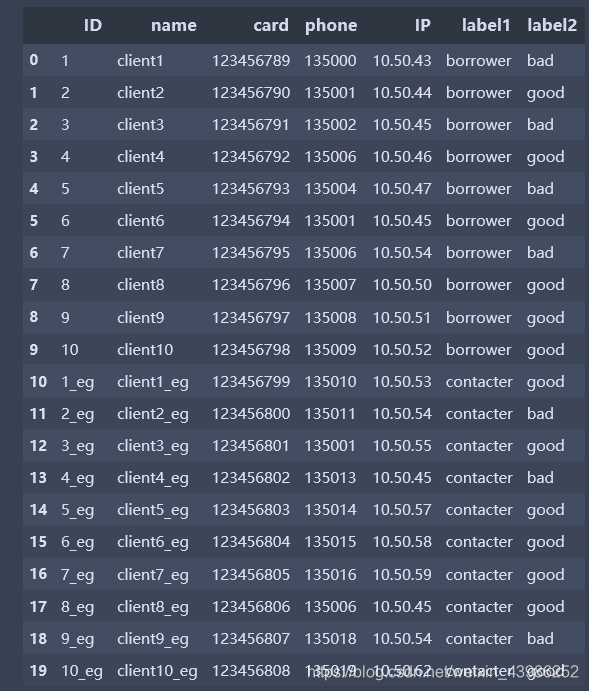
1.2 根据数据内容进行节点设计
- 节点:以人为节点,节点/人;
- 节点属性:name, card, phone, IP ,…
- 节点标签:节点标签可以设置一个或多个,这里每个节点有两个标签 label1 和label2 (例如label为借款人或联系人,label2
为黑名单标签,good或bad) - 关系:为了简单些,直接按照属性是否相等建立关系属性
,如name_equal,card_equal,phone_equal,IP_equal,可以根据数据和业务需求建立 - 关系属性:可以为关系添加属性,比如IP_equal关系下添加共同的IP
二、 load_csv方法
2.1 节点导入
2.1.1 节点数据
因为load_csb不能动态传入节点和关系的标签,故需要按照节点标签、关系标签来分成不同csv.
# 按照节点标签建立对应csv,并保存
data_label=[]
list_label=[("borrower","good"),("borrower","bad"),("contacter","good"),("contacter","bad")]
for label1,label2 in list_label:
data_label.append(data[data["label1"]==label1][data[data["label1"]==label1]["label2"]==label2])
# 保存data_label
i=1
for data_label in data_label:
data_label.to_csv(path+"data"+str(i)+"_label.csv",index=False)
i+=1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

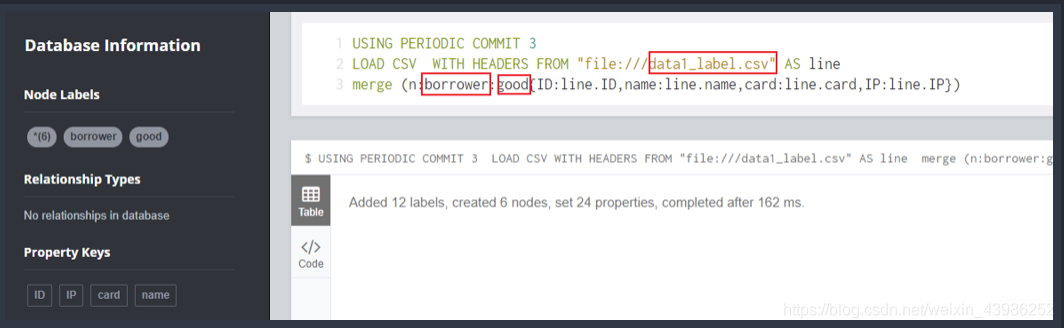
2.1.2 直接在neo4j browser导入
依次导入按节点标签分开的csv,语句及导入后的效果见下图,红框内为每次导入需要修改的地方:
- 导入成功显示:
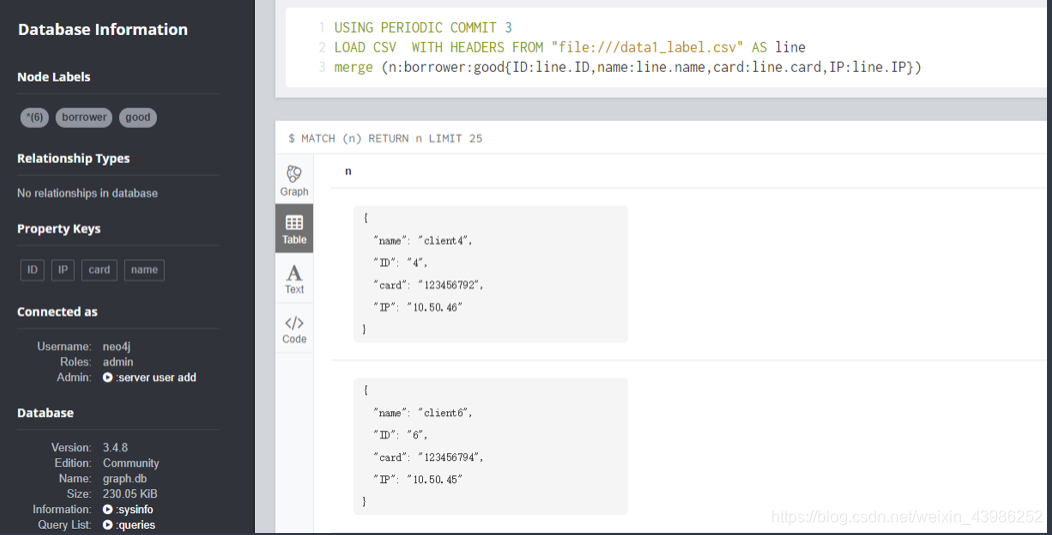
- 查看graph

- 查看属性
2.1.3 用python API
# 导入模块
from py2neo import Graph,Node,Relationship,NodeSelector
# 连接Neo4j图形数据库,保证neo4j服务器处于start状态
graph = Graph("http://**.**.***.***:7474",
username="****", #neo4j用户名
password='****'#neo4j密码
)
print("succeed to link Neo4j data")
#读取节点csv
import os
dirs=os.listdir(path)
files_node_csv = list(filter(lambda x: x[-10:]=='_label.csv' , dirs))
print("the csv files under path1:\n",files_node_csv)
##输出内容***************************************************************************
succeed to link Neo4j data
the csv files under path1:
['data1_label.csv', 'data2_label.csv', 'data3_label.csv', 'data4_label.csv']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
def LoacCsvNodes(num,files_csv,list_label):
'''
num: 每次导入的行数,用来防止内存溢出,str类型
files_csv: csv文件名列表
list_label: 节点标签列表,和file_csv同长度
'''
for i in range(len(files_csv)):
# graph.run ()中为cypher 语句
graph.run('USING PERIODIC COMMIT '+num+' \
LOAD CSV WITH HEADERS FROM "file:///'+files_csv[i]+'" AS line \
merge (n:'+list_label[i][0]+ ':'+list_label[i][1]+ \
'{ID:line.ID,name:line.name,card:line.card,IP:line.IP})')
LoacCsvNodes("3",files_node_csv,list_label)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
导入后查看:
和前面直接用cypher在neo4j browser导入效果一样,用API会更方便一些,因为可以用动态变量嘛
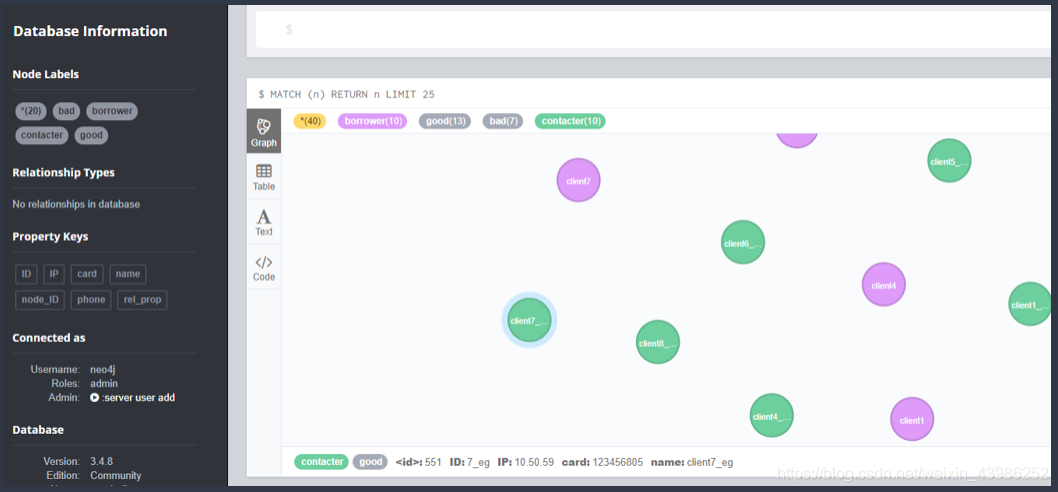
2.2 关系导入
2.2.1 关系数据
def RelFile(data,file_name,col,rel_label,str1=""):
'''
data:原始数据集
file_name:保存的文件名
col:字段名(列),str类型
str_rel:关系标签,str类型
str1:联系人时的ID和贷款人的ID字段差别,str类型
'''
import csv
file_rel=open(path+file_name+"_rel.csv","w",newline='',encoding='utf-8')
w=csv.writer(file_rel)
w.writerow((":START_ID","rel_prop",":END_ID",":TYPE"))# import需要的header格式,load_csv可以不带
for i in range(len(data)):
data_other=data[i+1:len(data)]
data_same=data_other[data_other[col]==data[col][i]+str1].reset_index(drop=True)
if len(data_same)>0:
for j in range(len(data_same)):
w.writerow((data["ID"][i],data[col][i],data_same["ID"][j],rel_label))
file_rel.close()
RelFile(data,"contact","ID","紧急联系人",str1="_eg")
RelFile(data,"IP","IP","IP_equal")
data["phone"]=data["phone"].astype("str")
RelFile(data,"phone","phone","phone_equal")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
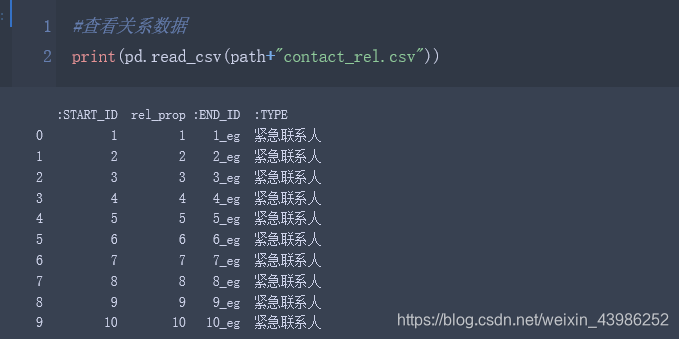
2.2.2 直接在neo4j browser中用cypher语句
- 联系人关系
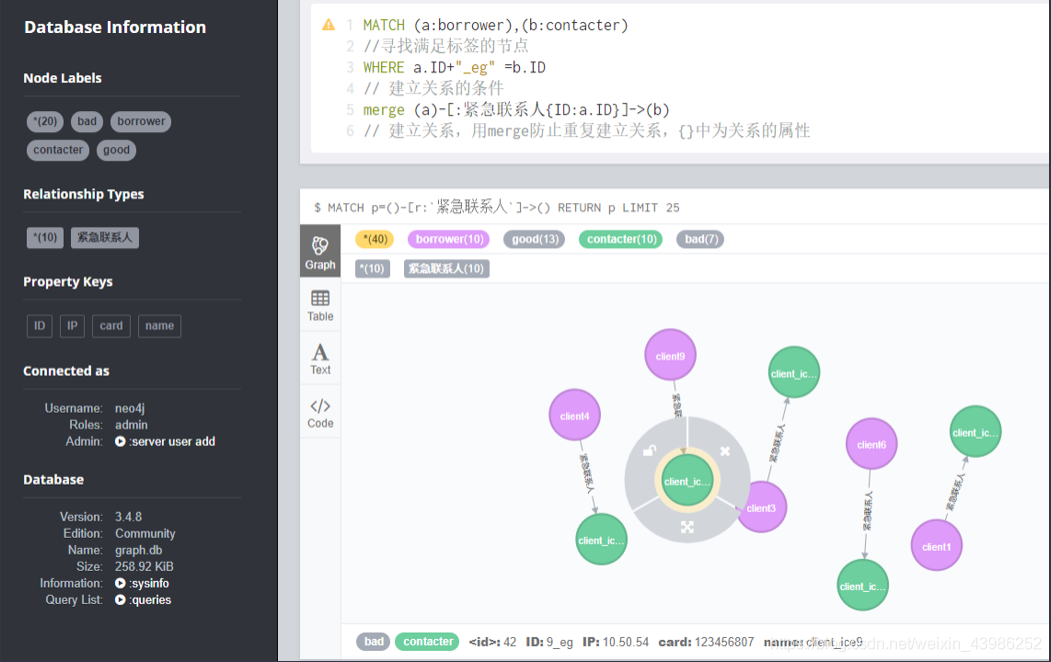
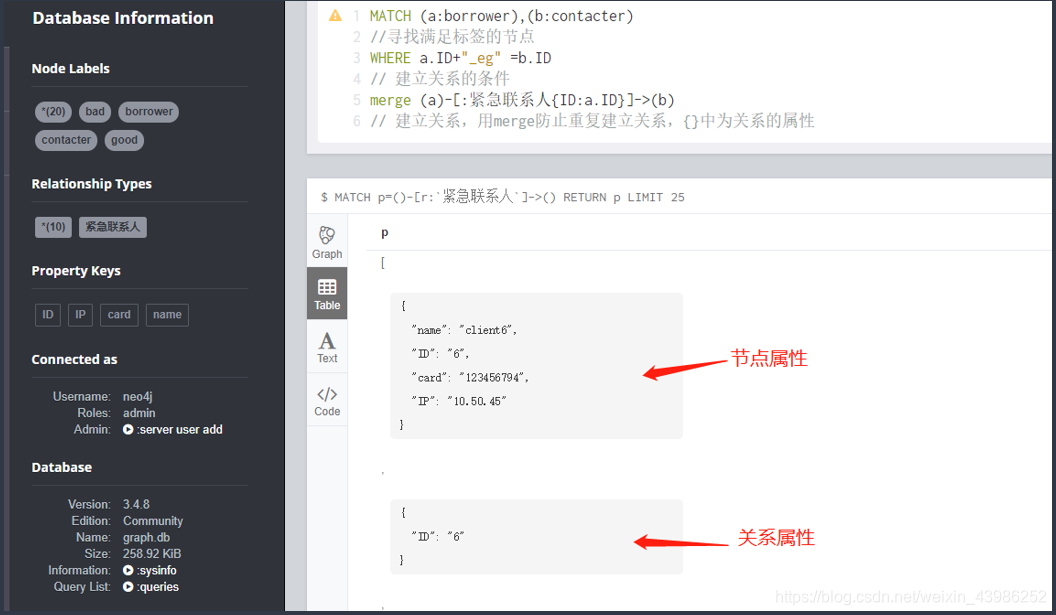
2. IP相等关系
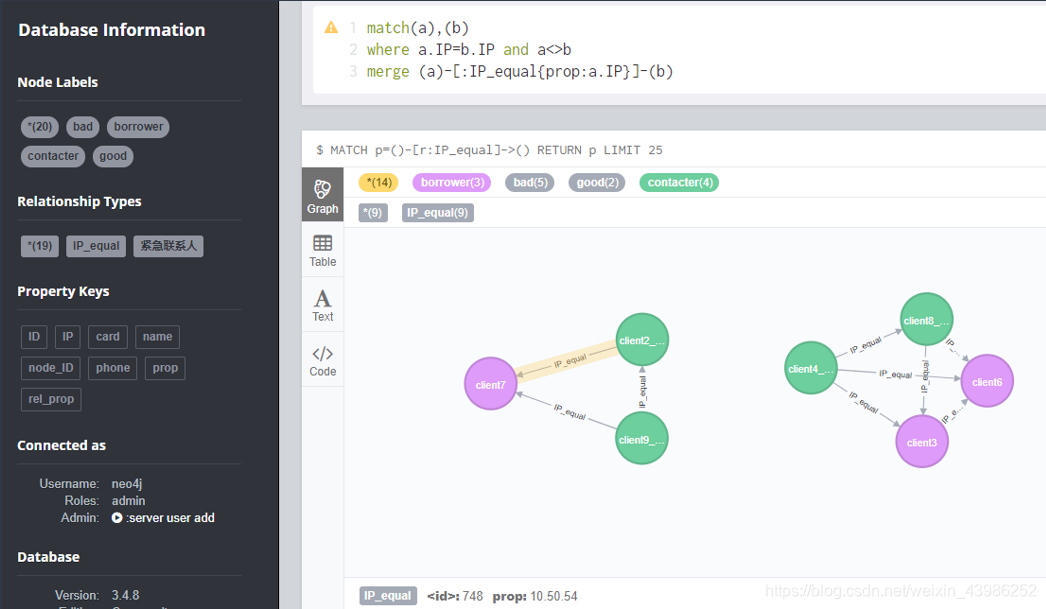
其他关系依次建立,这样建立关系比较适合小数据集,因为match(n)是在全节点中搜索,如果没有标签限制,还没加索引,那速度是可以想象的
2.2.3 直接在neo4j browser中用load_csv
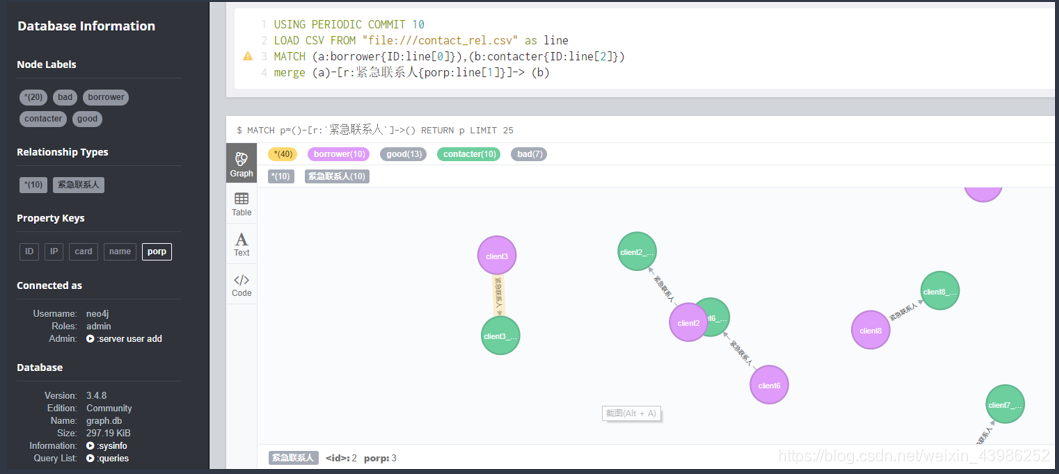
依次导入每个关系csv即可
2.2.4 python API
# 读取关系数据
files_rel_csv = list(filter(lambda x: x[-8:]=='_rel.csv' , dirs))
print("the csv files under path1:\n",files_rel_csv)
# 导入关系数据函数
def LoadCsvRel(num,files_csv,list_rel_label,node_label1="",node_label2=""):
'''
num: 每次导入的行数,防止内存溢出,str类型
files_csv:文件名列表
list_label: 节点标签列表,和file_csv同长度
'''
for i in range(len(files_csv)):
graph.run('USING PERIODIC COMMIT '+num+' \
LOAD CSV FROM "file:///'+files_csv[i]+'" AS line \
MATCH (a'+node_label1+'{ID:line[0]}),(b'+node_label2+'{ID:line[2]}) \
merge (a)-[r:'+list_rel_label[i]+'{prop:line[1]}]-> (b) '
)
list_rel_label=["contacter","IP_equal","phone_equal"]# 和file_rel_csv 对应
LoadCsvRel("3",files_rel_csv,list_rel_label)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
查看:
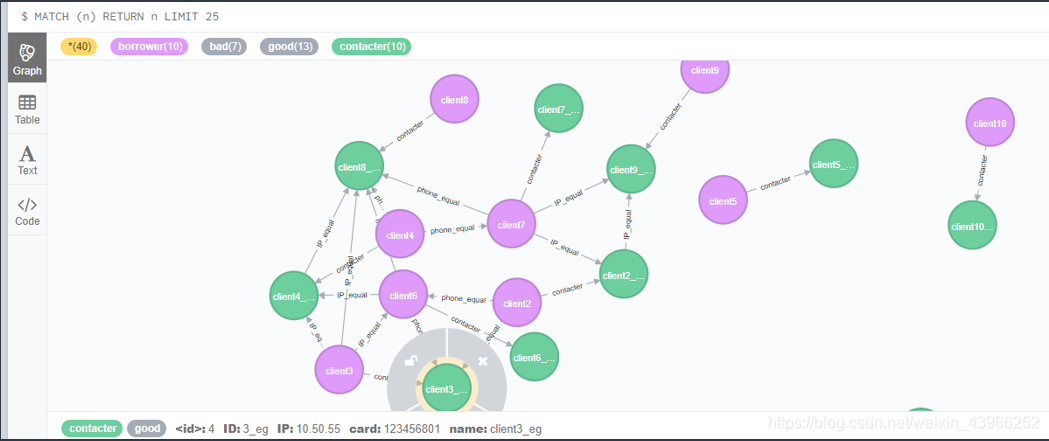
三、 import 方法
导入时需停止neo4j 服务器,清空graph.db下的所有文件(即清库)
3.1 步骤
3.1.1 cmd 打开命令窗口,进入neo4j根目录,停止neo4j服务器
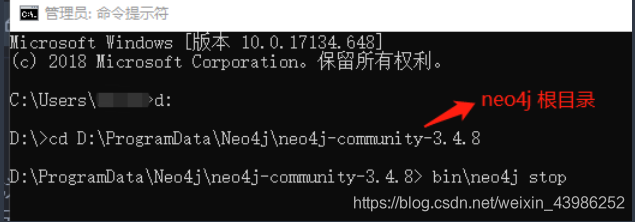
3.1.2 然后删除neo4j下 data/databases/graph.db下的所有文件 (清库)
3.1.3 admin import导入数据
admin import 对导入的文件有一定的要求:
3.1.3.1 节点文件
data[":Label"]=data["label1"]+";"+data["label2"]
data=data.drop(columns=["label1","label2"])
# import对列名有要求,冒号后面的字段时必须有的,且保持一致
data.columns=["node_ID:ID","name","card","phone","IP",":LABEL"]
data.head()
- 1
- 2
- 3
- 4
- 5
- 6
结果:
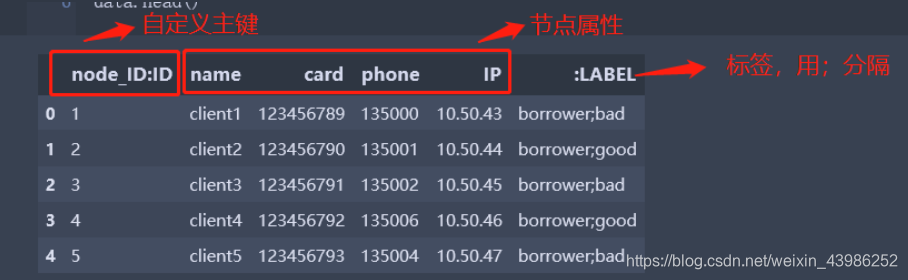
3.1.3.2 关系文件
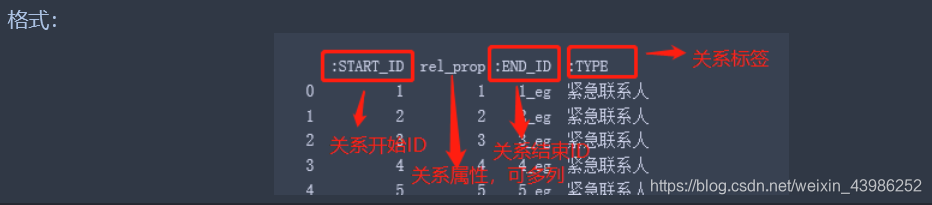
load_csv中我们已经处理好了关系文件,可以直接用啦
3.1.3.3 import
在命令窗口中输入,记得在noe4j的根目录下哦:
bin\neo4j-admin import --nodes import\nodes.csv --relationships import\IP_rel.csv --relationships import\phone_rel.csv --relationships import\contact_rel.csv
- 1
如果数据较大的话,可以把列名单独存csv,数据分几个csv保存,按照下图csv命名规范保存即可。

导入成功后,会显示节点、关系数和属性数及运行时间:
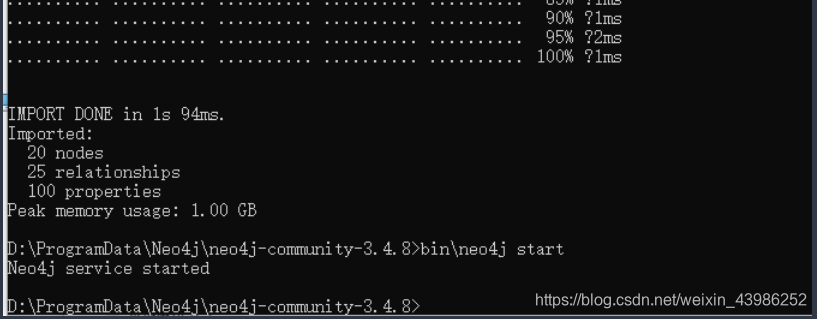
3.1.4 重启服务器(参考上图)
3.1.5 打开neo4j browser 查看结果
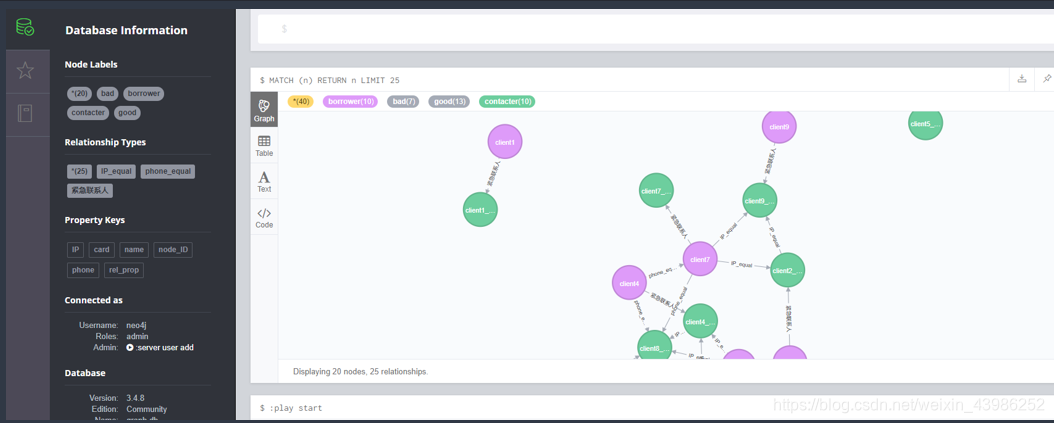
和load_csv一样的结果,必然的啦,因为一样的数据嘛,哈哈,皮一下~
四、 总结
- 在练习cypher语句,测试数据,或数据量较少(小于10w)时,或实时增加数据时,用load_csv还是不错的,快速且不用停止服务。
- 但在海量数据(上亿)时,用import效率很快,由于需要停止服务器这个缺点,一般适用于初始neo4j时存量数据的导入,后期用其他方法实现实时的增量更新
参考文档:
http://weikeqin.cn/2017/04/11/neo4j-load-csv/
https://neo4j.com/docs/operations-manual/current/tutorial/import-tool/
所属网站分类: 技术文章 > 博客
作者:大王叫我来巡山了
链接:https://www.pythonheidong.com/blog/article/10523/2ea22681619ec2115a0f/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力