

python3爬取梨视频,并下载到本地
发布于2019-09-11 16:57 阅读(852) 评论(0) 点赞(25) 收藏(1)
导入相关库
- """
- -*- coding:utf-8 -*-
- author:Air
- datetime:2019/7/26 22:26
- software: PyCharm
- 学习交流qq群:916696436
- """
- import requests
- import re
- import os
- import time
- from parsel import Selector
分析网页
数据是ajax请求的

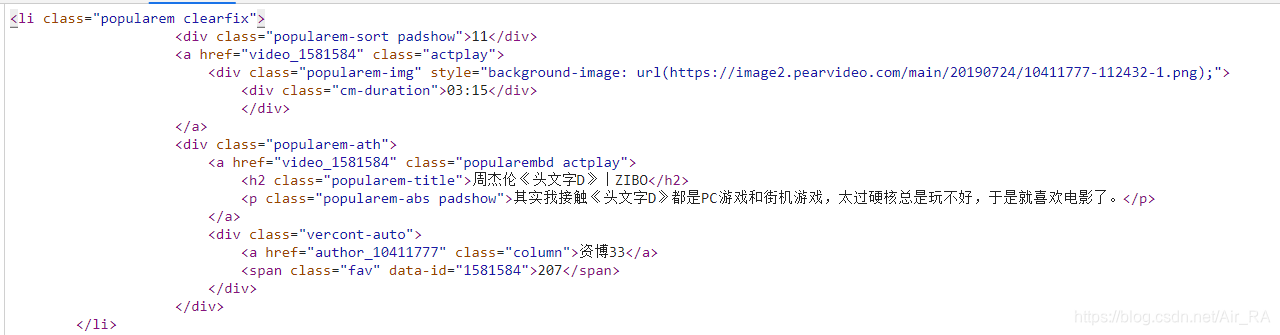
视频在详情页中
1.获取详情页url
- url='https://www.pearvideo.com/popular_loading.jsp'
- data={
- 'reqType':1,
- 'categoryId':59,
- 'start':num
- }
- res=requests.get(url,headers=headers,params=data)
- s=Selector(text=res.content.decode())
- li_list=['https://www.pearvideo.com/{}'.format(i) for i in s.xpath('//li/a[@class="actplay"]/@href').getall()]
2.获取视频url和名字

通过正则获取视频url
- def get_mp4(url):
- res=requests.get(url,headers=headers)
- s=Selector(text=res.content.decode())
- name=s.xpath('//h1[@class="video-tt"]/text()').get()
- pattern=re.compile(r'srcUrl="(.*?)"',re.S)
- mp4_url=pattern.findall(res.text)[0]
3.下载视频
- def dowm_mp4(name,url):
- if not os.path.exists(root):
- os.makedirs(root)
- res=requests.get(url,headers=headers)
- path=root+name+'.mp4'
- with open(path,'wb') as f:
- f.write(res.content)
- print('下载成功')
4.结果(下载了一部)
5.统筹调用
(1)爬取十页
(2)设置休眠时间
- def start():
- for i in range(10): #爬取十页
- urls=get_url(i)
- for url in urls:
- get_mp4(url)
- time.sleep(2)
源码
- """
- -*- coding:utf-8 -*-
- author:Air
- datetime:2019/7/26 22:26
- software: PyCharm
- 学习交流qq群:916696436
- """
- import requests
- import re
- import os
- import time
- from parsel import Selector
- root='./mp4/'
- from fake_useragent import UserAgent
-
- # 生成对象
- useragent = UserAgent()
- headers = {
- 'User-Agent': useragent.random
- }
- def get_url(num):
- url='https://www.pearvideo.com/popular_loading.jsp'
- data={
- 'reqType':1,
- 'categoryId':59,
- 'start':num
- }
- res=requests.get(url,headers=headers,params=data)
- s=Selector(text=res.content.decode())
- li_list=['https://www.pearvideo.com/{}'.format(i) for i in s.xpath('//li/a[@class="actplay"]/@href').getall()]
- return li_list
- def get_mp4(url):
- res=requests.get(url,headers=headers)
- s=Selector(text=res.content.decode())
- name=s.xpath('//h1[@class="video-tt"]/text()').get()
- pattern=re.compile(r'srcUrl="(.*?)"',re.S)
- mp4_url=pattern.findall(res.text)[0]
- print(name)
- dowm_mp4(name,mp4_url)
- def dowm_mp4(name,url):
- if not os.path.exists(root):
- os.makedirs(root)
- res=requests.get(url,headers=headers)
- path=root+name+'.mp4'
- with open(path,'wb') as f:
- f.write(res.content)
- print('下载成功')
- def start():
- for i in range(10): #爬取十页
- urls=get_url(i)
- for url in urls:
- get_mp4(url)
- time.sleep(2)
- start()
所属网站分类: 技术文章 > 博客
作者:gg
链接:https://www.pythonheidong.com/blog/article/107686/992f9a9c723e6ba450bb/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力