

爬虫篇| 爬取百度图片(一)
发布于2019-08-07 14:52 阅读(1403) 评论(0) 点赞(1) 收藏(4)
什么是爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。(来源: 百度百科)
爬虫协议
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
robots.txt文件是一个文本文件,使用任何一个常见的文本编辑器,比如Windows系统自带的Notepad,就可以创建和编辑它。robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。(来源: 百度百科)
爬虫百度图片
目标:爬取百度的图片,并保存电脑中
- 能不能爬?
首先数据是否公开?能不能下载?
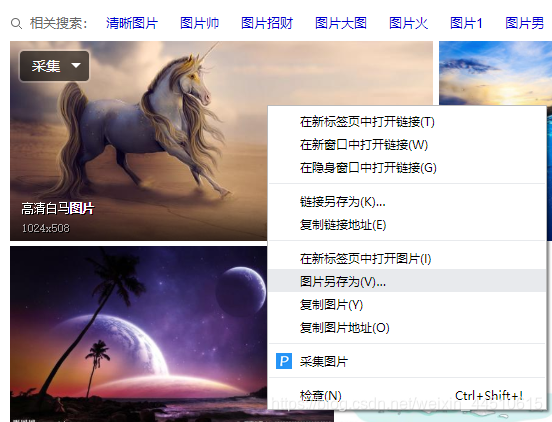
从图中可以看出,百度的图片是完全可以下载,说明了图片可以爬取
- 先爬取一张图片
首先,明白图片是什么?
有形式的事物,我们看到的,是图画、照片、拓片等的统称。图是技术制图中的基础术语,指用点、线、符号、文字和数字等描绘事物几何特征、形态、位置及大小的一种形式。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
然后需要图片在哪里?
图片是在云服务器的数据库中的保存起来的
每张图片都有对应的url,通过requests模块来发起请求,在用文件的wb+方式来保存起来
import requests
r = requests.get('http://pic37.nipic.com/20140113/8800276_184927469000_2.png')
with open('demo.jpg','wb+') as f:
f.write(r.content)
- 1
- 2
- 3
- 4
- 批量爬取
但是有谁为了爬一张图片去写代码,还不如直接去下载 。爬虫是目的就是为了达到批量下载的目的,这才是真正的爬虫
- 网站的分析
首先了解json
JSON(JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。它基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。
json 就是js 的对象,就是来存取数据的东西
JSON字符串
{
“name”: “毛利”,
“age”: 18,
“ feature “ : [‘高’, ‘富’, ‘帅’]
}
- 1
- 2
- 3
- 4
- 5
Python字典
{
‘name’: ‘毛利’,
‘age’: 18
‘feature’ : [‘高’, ‘富’, ‘帅’]
}
- 1
- 2
- 3
- 4
- 5
但是在python中不可以直接通过键值对来取得值,所以不得不谈谈python中的字典
导入python 中json,通过json.loads(s) -->将json数据转换为python的数据(字典)
- ajax 的使用
Ajax 即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),是指一种创建交互式网页应用的网页开发技术。
图片是通过ajax 方法来加载的,也就是当我下拉,图片会自动加载,是因为网站自动发起了请求,
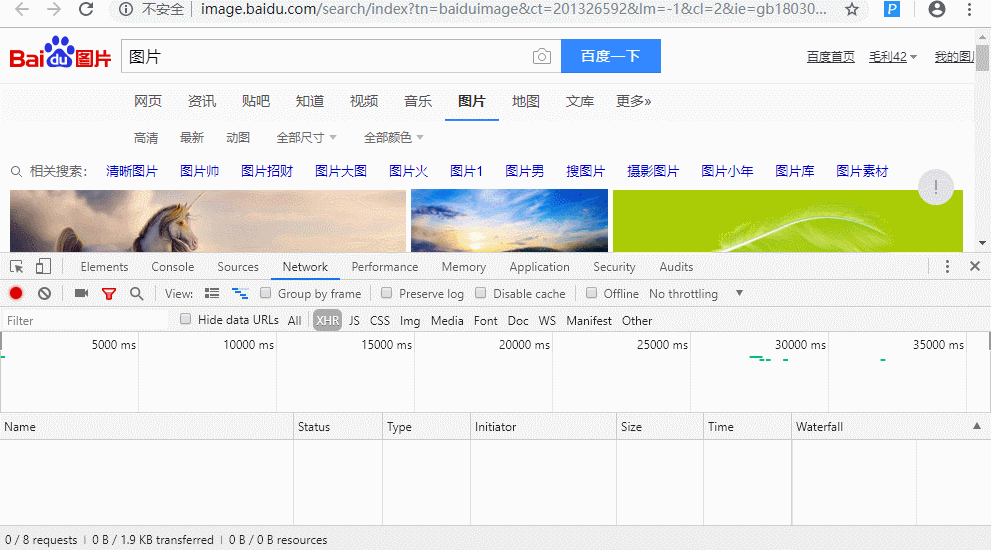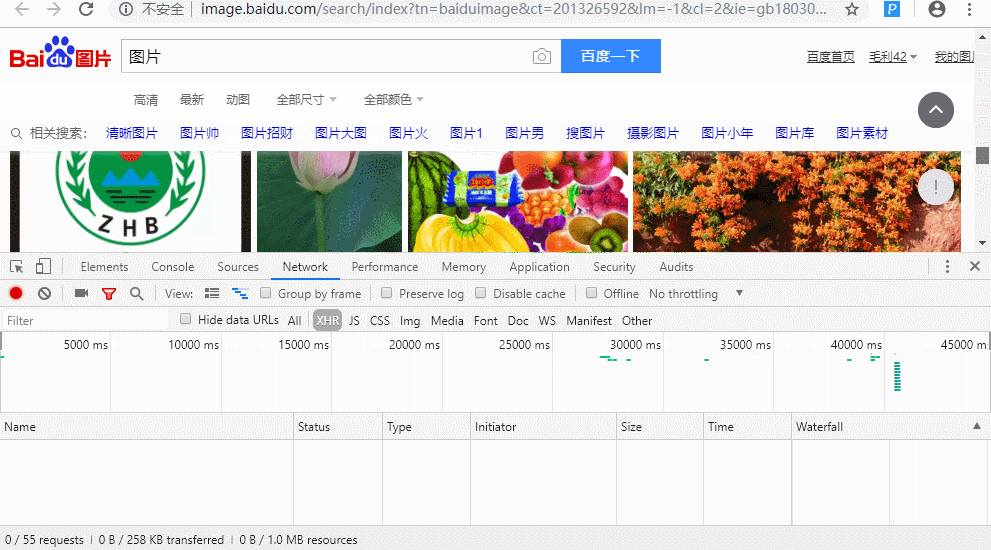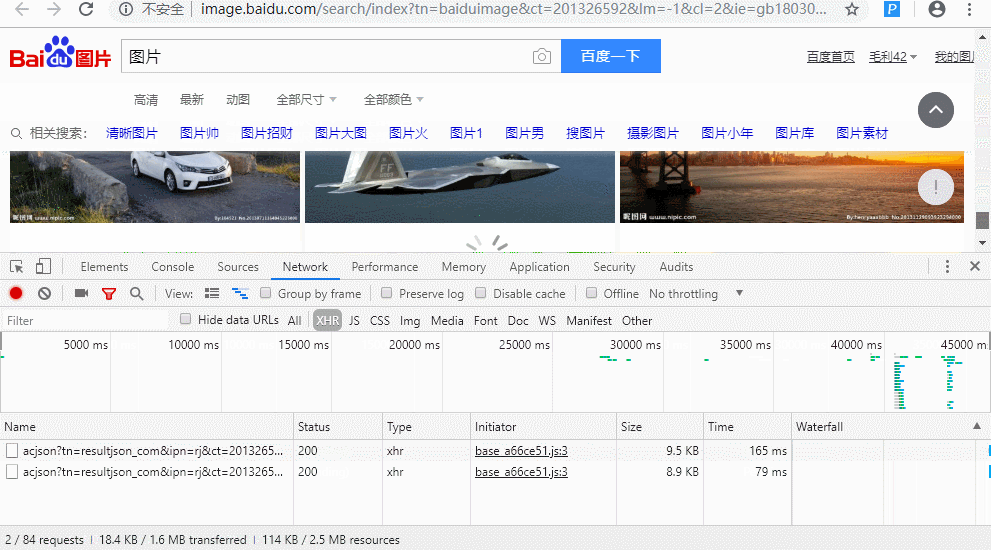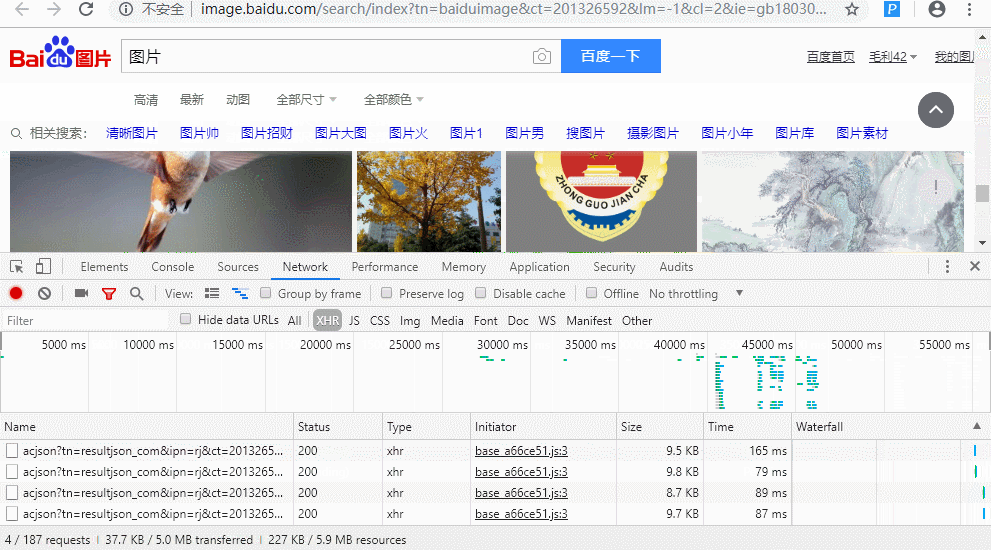
- 分析图片url链接的位置
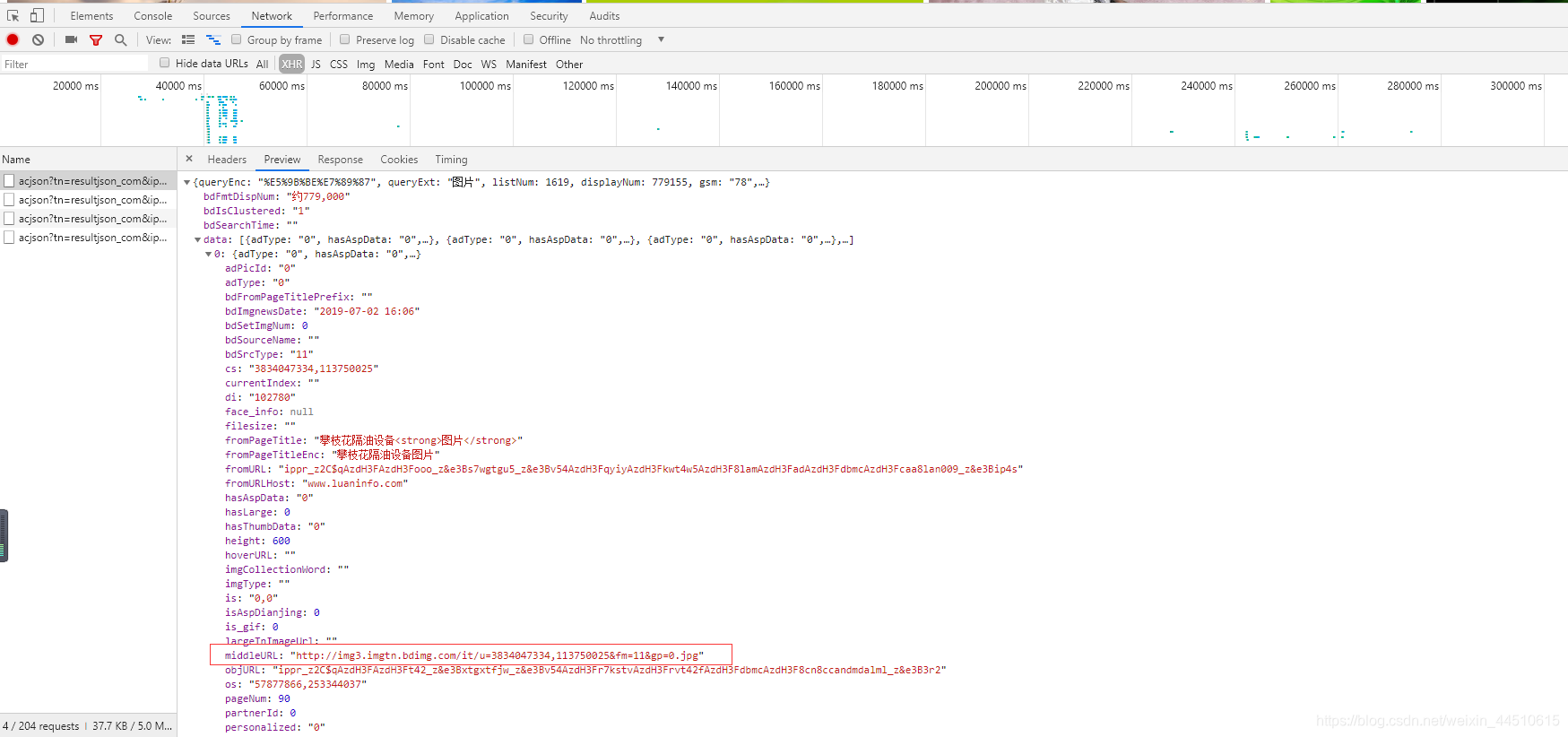
- 同时找到对应ajax的请求的url
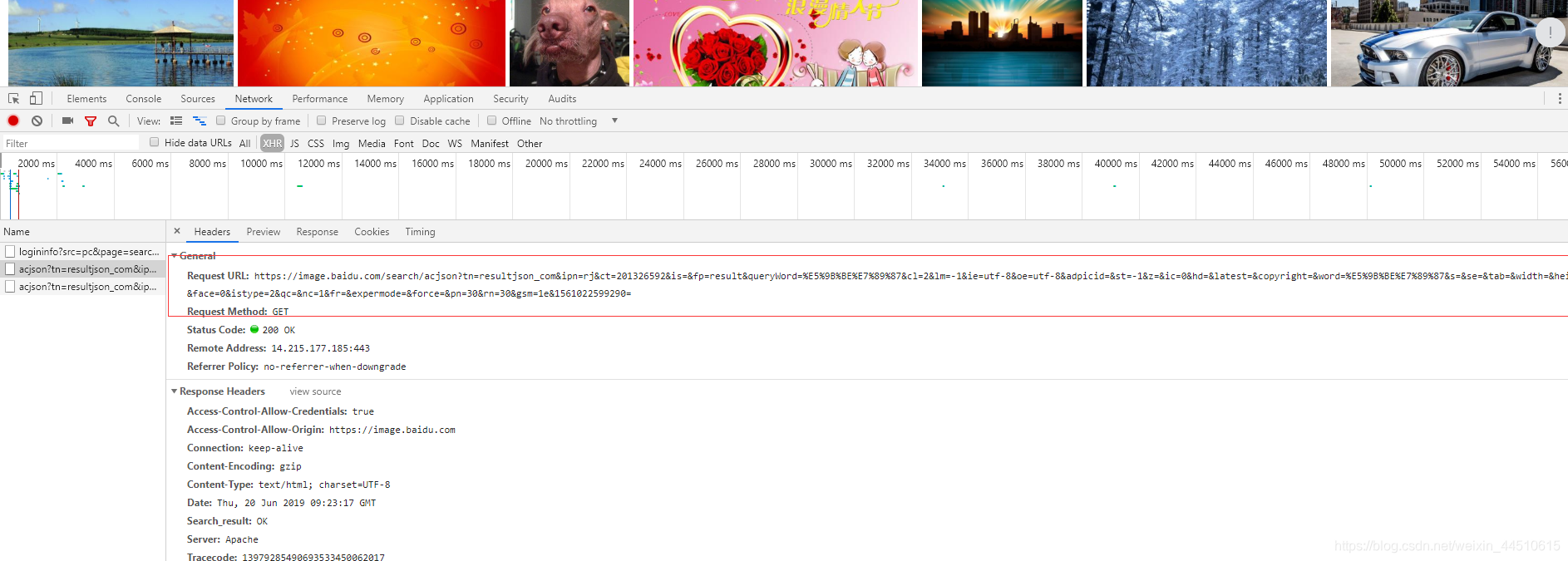
构造ajax的url请求,来将json转化为字典,在通过字典的键值对来取值,得到图片对应的url
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=',headers = headers).text
res = json.loads(r)['data']
for index,i in enumerate(res):
url = i['hoverURL']
print(url)
with open( '{}.jpg'.format(index),'wb+') as f:
f.write(requests.get(url).content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 构造json的url,不断的爬取图片
在一个json 的有30张图片,所以发起一个json的请求,我们可以爬去30张图片,但是还是不够。
首先分析不同的json中发起的请求
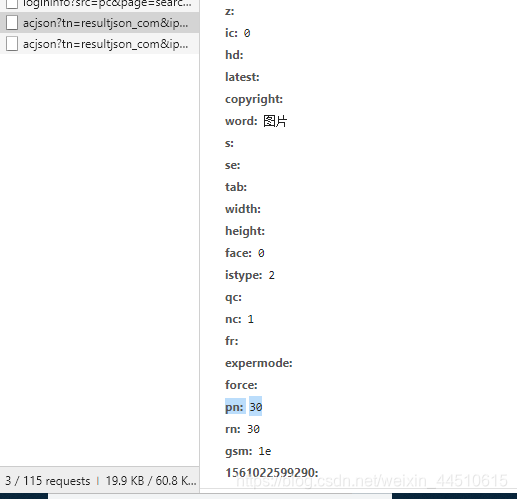
https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=60&rn=30&gsm=3c&1561022599355=
https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=
- 1
- 2
其实可以发现,当再次发起请求时,关键就是那个 pn在不断的变动
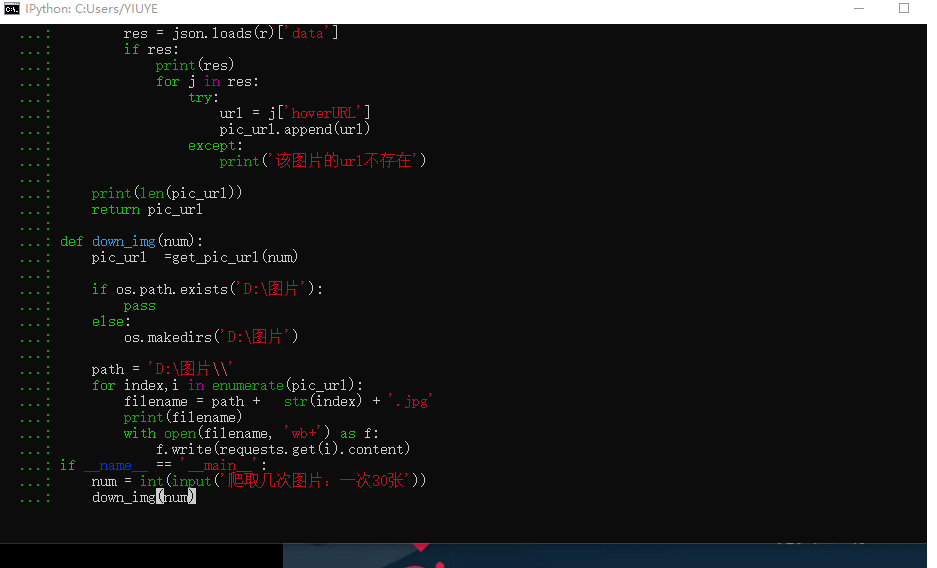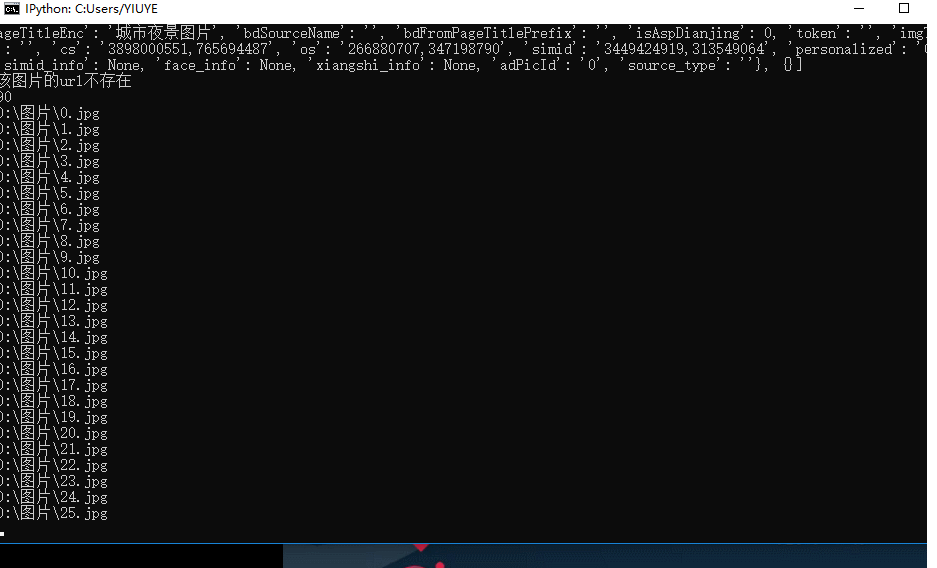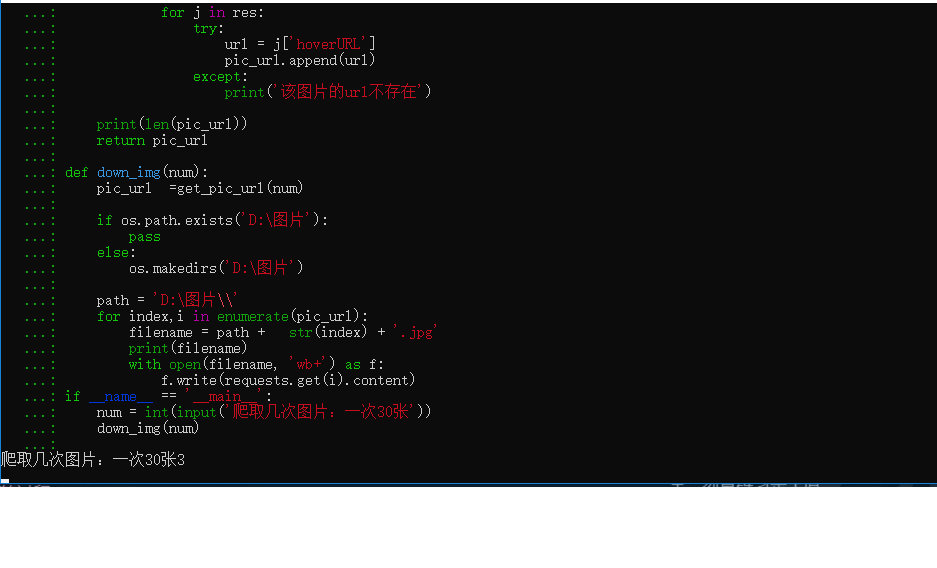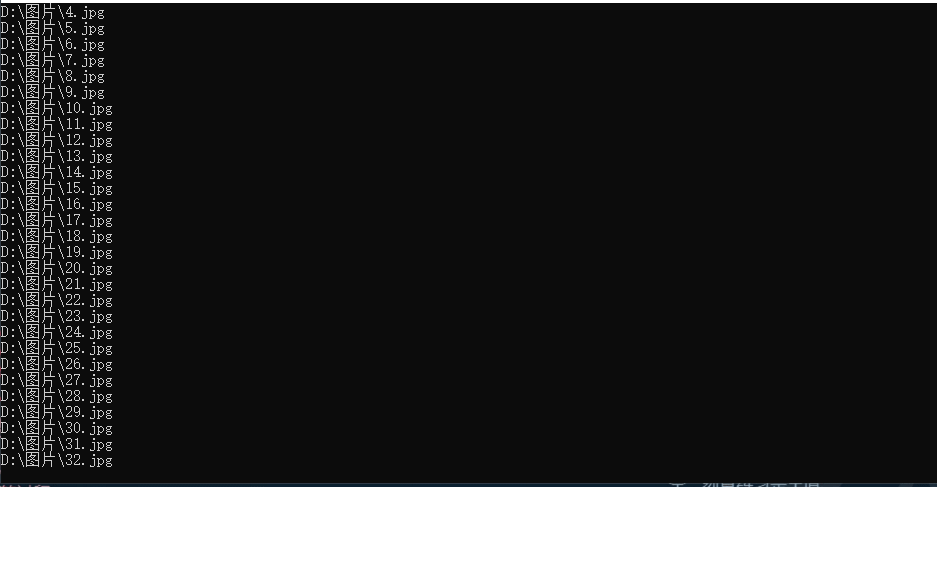
最后封装代码,一个列表来定义生产者来存储不断的生成图片url,另一个列表来定义消费者来保存图片
# -*- coding:utf-8 -*-
# time :2019/6/20 17:07
# author: 毛利
import requests
import json
import os
def get_pic_url(num):
pic_url= []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
for i in range(num):
page_url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=1e&1561022599290='.format(30*i)
r = requests.get(page_url, headers=headers).text
res = json.loads(r)['data']
if res:
print(res)
for j in res:
try:
url = j['hoverURL']
pic_url.append(url)
except:
print('该图片的url不存在')
print(len(pic_url))
return pic_url
def down_img(num):
pic_url =get_pic_url(num)
if os.path.exists('D:\图片'):
pass
else:
os.makedirs('D:\图片')
path = 'D:\图片\\'
for index,i in enumerate(pic_url):
filename = path + str(index) + '.jpg'
print(filename)
with open(filename, 'wb+') as f:
f.write(requests.get(i).content)
if __name__ == '__main__':
num = int(input('爬取几次图片:一次30张'))
down_img(num)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44

欢迎关注公众号

所属网站分类: 技术文章 > 博客
作者:python好学吗
链接:https://www.pythonheidong.com/blog/article/11398/edb3c22a534c9e76215d/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力