

机器学习 -- 朴素贝叶斯(案例:预测旧金山犯罪)
发布于2019-10-29 14:26 阅读(2719) 评论(0) 点赞(13) 收藏(3)
一. 下载数据集
下载地址为:https://www.kaggle.com/c/sf-crime/data。

二. 数据集读取
将train.csv放到和python文件的同级目录下,便于使用。
(1)导入需要的模块和包。
- import pandas as pd
- from sklearn import *
(2)读取文件。
train_df = pd.read_csv('train.csv')(3)读取文件内容如下:
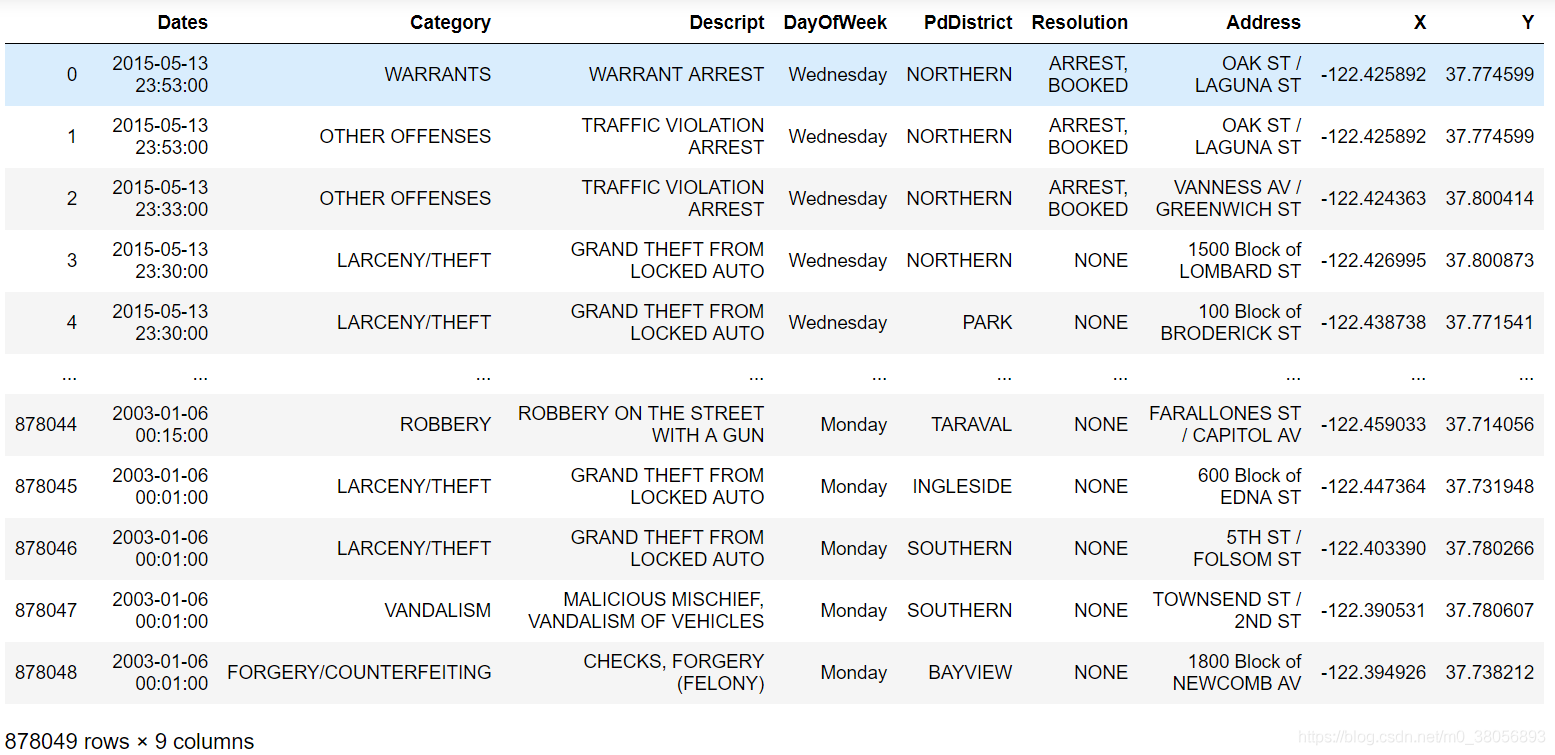
三. 数据集类别和特征的选取
观察上图数据集,有日期、犯罪种类、描述、星期几、解决方案、地址及XY坐标等多列。我们将“犯罪类别”设置为类别,同时这里不将“罪行描述”、“X/Y坐标”、“结果”作为其特征。
四. 选择合适的朴素贝叶斯模型
sklearn提供了三种朴素贝叶斯模型,选择一个最适合的作为旧金山的犯罪预测。
| 模型名称 | 数据分布 | 特征特点 |
|---|---|---|
| GaussianNB(高斯朴素贝叶斯模型) | 连续式数据 | 特征的数据连续 |
| BernoulliNB(伯努利朴素贝叶斯模型) | 离散式数据 | 所有特征必须0或1,表示出现或不出现 |
| MultinomialNB(多项式朴素贝叶斯模型) | 离散式数据 | 适用于文本分类,计算某些词出现的频率 |
分析:
(1)高斯朴素贝叶斯模型适合连续数据,因为样本各特征都是离散特征所以不适合用此模型。
(2)伯努利朴素贝叶斯模型和多项式朴素贝叶斯模型都适合离散式数据,因为旧金山犯罪是个典型的伯努利分布,所以选择伯努利朴素贝叶斯模型。
五. 处理训练集数据的类别和特征
1.处理类别:调用sklearn的preprocessing库,使用LabelEncoder对犯罪类型编码。
- le = preprocessing.LabelEncoder()
- crime_type_encode = le.fit_transform(train_df['Category'])

2. 处理特征:将小时,星期几,所属警区的特征使用pandas库的get_dummies()功能因子化,得到哑变量(dummy_variable)。
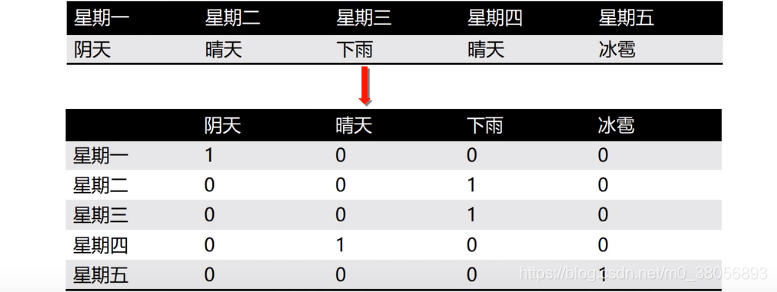
哑变量:将不能定量处理的变量量化,构造只取“0”或“1”的人工变量,适合伯努利朴素贝叶斯模型。
例如将下图天气情况转换成哑变量:
- hour = pd.to_datetime(train_df['Dates']).dt.hour # 从Dates列中抽取小时时间
- # 将小时(0-24),星期(周一-周日) ,所属警区的特征使用pandas库的get_dummies()功能因子化,得到哑变量(dummy_variable)
- hour = pd.get_dummies(hour)
- day = pd.get_dummies(train_df['DayOfWeek'])
- police_district = pd.get_dummies(train_df['PdDistrict'])
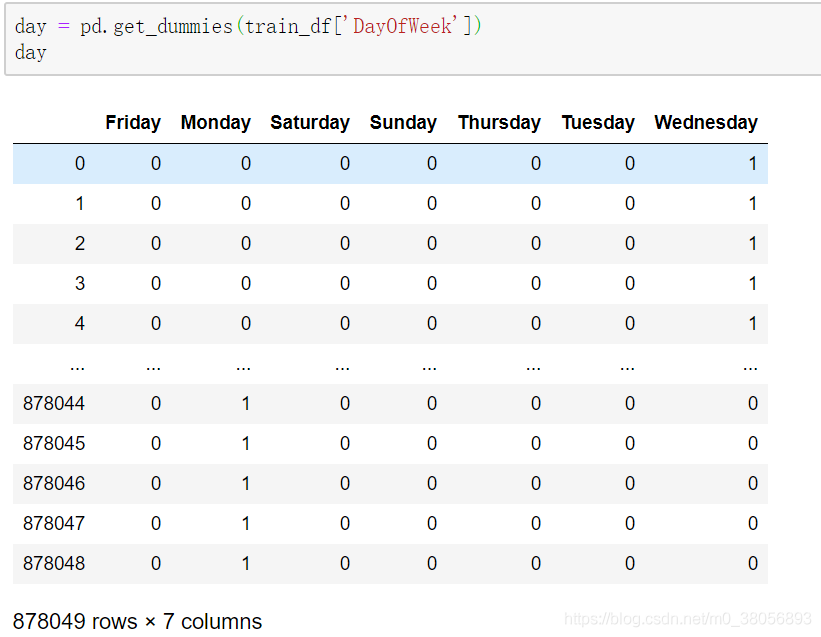
将三个特征功能因子化后如下:
(1)日期:
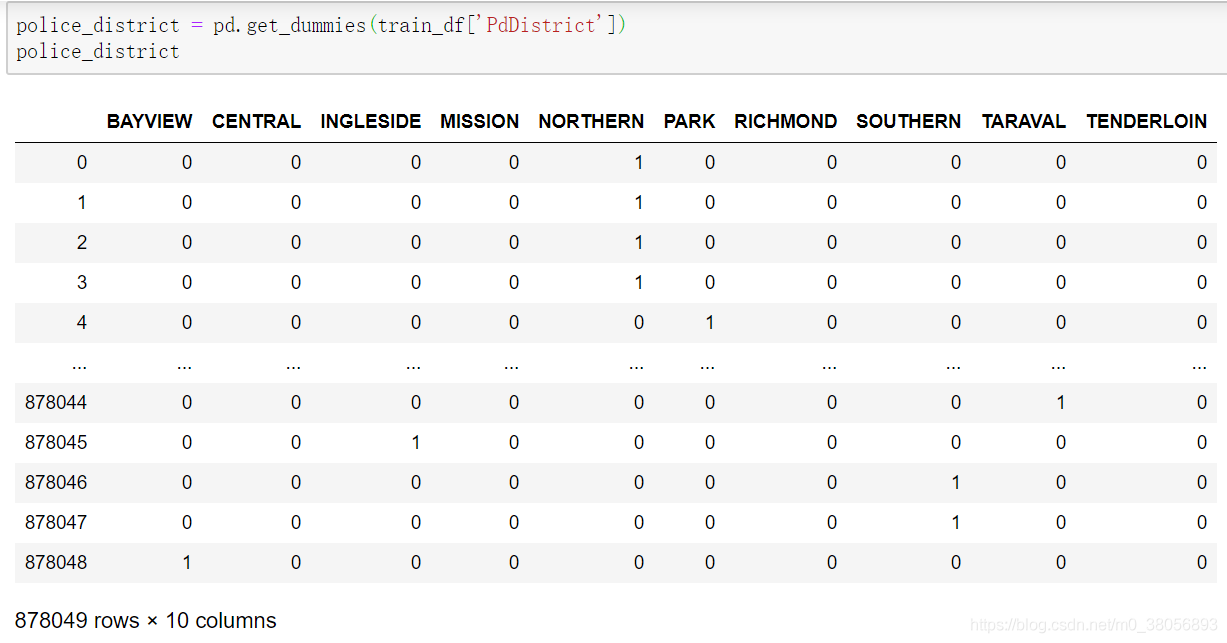
(2)警区:
(3)时间:
六. 合并训练集数据的特征
train_set = pd.concat([hour, day, police_district], axis = 1) # 将特征组合成一个DataFrame合并完如下:
七. 将类别合并到数据集中
train_set['Crime type'] = crime_type_encode # 向特征组成的DataFrame添加新的一列类别合并完如下:
八. 数据集的划分
1. 从训练数据集中分割出训练数据和测试数据
- from sklearn.model_selection import train_test_split
-
- X = train_set.loc[:, train_set.columns != 'Crime type']
- y = train_set['Crime type']
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=1)
数据集的划分如下:

2. 创建训练模型,将X_train,y_train放入模型
- from sklearn.naive_bayes import BernoulliNB
-
- model = BernoulliNB()
- model.fit(X_train, y_train)
3. 将X_test放入刚刚生成的模型进行预测
y_pred = model.predict(X_test)4. 将预测值与实际值进行比对,输出精确度的值
print("model accuracy:", metrics.accuracy_score(y_test, y_pred))model accuracy: 0.22405051181479002最终预测值为22%左右。结果表明:在旧金山,任何一天,任何一小时,任何一片警区,我们知道它会发生39种犯罪类型的哪一种的准确率在22%左右。
所属网站分类: 技术文章 > 博客
作者:骷髅无悔
链接:https://www.pythonheidong.com/blog/article/147503/81473ea10afea2984d31/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力