

Python 多线程爬取站酷(zcool.com.cn)图片
发布于2019-11-07 09:20 阅读(898) 评论(0) 点赞(23) 收藏(5)
极速爬取下载站酷(https://www.zcool.com.cn/)设计师/用户上传的全部照片/插画等图片。
项目地址:https://github.com/lonsty/scraper
特点:#
- 极速下载:多线程异步下载,可以根据需要设置线程数
- 异常重试:只要重试次数足够多,就没有下载不下来的图片 (^o^)/
- 增量下载:设计师/用户有新的上传,再跑一遍程序就行了 O(∩_∩)O嗯!
- 支持代理:可以配置使用代理
环境:#
python3.6及以上
1. 快速使用#
1) 克隆项目到本地#
git clone https://github.com/lonsty/scraper2) 安装依赖包#
cd scraper
pip install -r requirements.txt3) 快速使用#
通过用户名username下载所有图片到路径path下:
python crawler.py -u <username> -d <path>运行截图
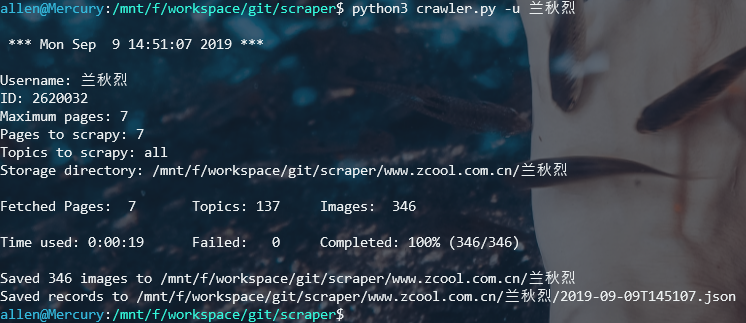
爬取结果
2. 使用帮助#
- 查看所有命令
python crawler.py --helpUsage: crawler.py [OPTIONS]
Use multi-threaded to download images from https://www.zcool.com.cn in
bulk by username or ID.
Options:
-i, --id TEXT User id.
-u, --username TEXT User name.
-d, --directory TEXT Directory to save images.
-p, --max-pages INTEGER Maximum pages to parse.
-t, --max-topics INTEGER Maximum topics per page to parse.
-w, --max-workers INTEGER Maximum thread workers. [default: 20]
-R, --retries INTEGER Repeat download for failed images. [default: 3]
-r, --redownload TEXT Redownload images from failed records.
-o, --override Override existing files. [default: False]
--proxies TEXT Use proxies to access websites.
Example:
'{"http": "user:passwd@www.example.com:port",
"https": "user:passwd@www.example.com:port"}'
--help Show this message and exit.3. 更新历史#
Version 0.1.0 (2019.09.09)#
主要功能:
- 极速下载:多线程异步下载,可以根据需要设置线程数
- 异常重试:只要重试次数足够多,就没有下载不下来的图片 (^o^)/
- 增量下载:设计师/用户有新的上传,再跑一遍程序就行了 O(∩_∩)O嗯!
- 支持代理:可以配置使用代理
所属网站分类: 技术文章 > 博客
作者:23dh
链接:https://www.pythonheidong.com/blog/article/148159/3fd18d78cffdf6520c0f/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力