本站消息


Python网络爬虫简单教程——第二部
发布于2019-12-14 16:10 阅读(1184) 评论(0) 点赞(17) 收藏(3)
Python网络爬虫简单教程——第二部
感谢,如需转载请注明文章出处:https://blog.csdn.net/weixin_44609873/article/details/103384984
上部呢,我们一起简单了解了爬虫的概念、用处,以及开发前的准备,现在一起来实现它吧 ^_ ^
- python3
我用的是 python3,python2 也是可以的。
爬虫基本流程
只要是浏览器能做的事情,原则上,爬虫都能够做
①获取网页地址
有些网页地址一目了然,但是还有些网址需要我们在浏览器中经过分析得出。
②请求网页
主要是为了获取我们所需求的网址的源码,便于我们从中获取数据,这其中可能需要去利用到 User-Agent, User-Agent 可以隐藏身份,便于访问。具体以后会再讲。
③获取源码中的指定的数据
这就是我们所说的要爬取的数据内容,有些网页数据杂多,甚至会内嵌网页,就需要我们去找到并解析所需的数据内容,一般有三种方法:正则表达式 re 、Xpath 和 Beautiful Soup
④处理数据
爬取下来的数据有时候会包含一些如标签、符号等的我们不需要的数据,这时候处理数据就变得很有必要了。
⑤存储数据
爬虫最后一步,存储我们所爬数据,便于我们浏览使用,数据存储一般有文本、表格、文件夹等形式
小试牛刀
铺垫已做好,开始爬它
爬取百度网页:
首先导入我么所需要的包 qequests 、 beautifulsoup4 和 lxml
打开 cmd 依次输入:
pip install requests 等待安装完成,
pip install beautifulsoup4 等待安装完成
pip install lxml 等待安装完成
这是导入相关 python 库,注意,这里的 lxml 库 Windows 直接 pip 可能不成功 具体解决参考 Windows下如何安装python第三方库lxml
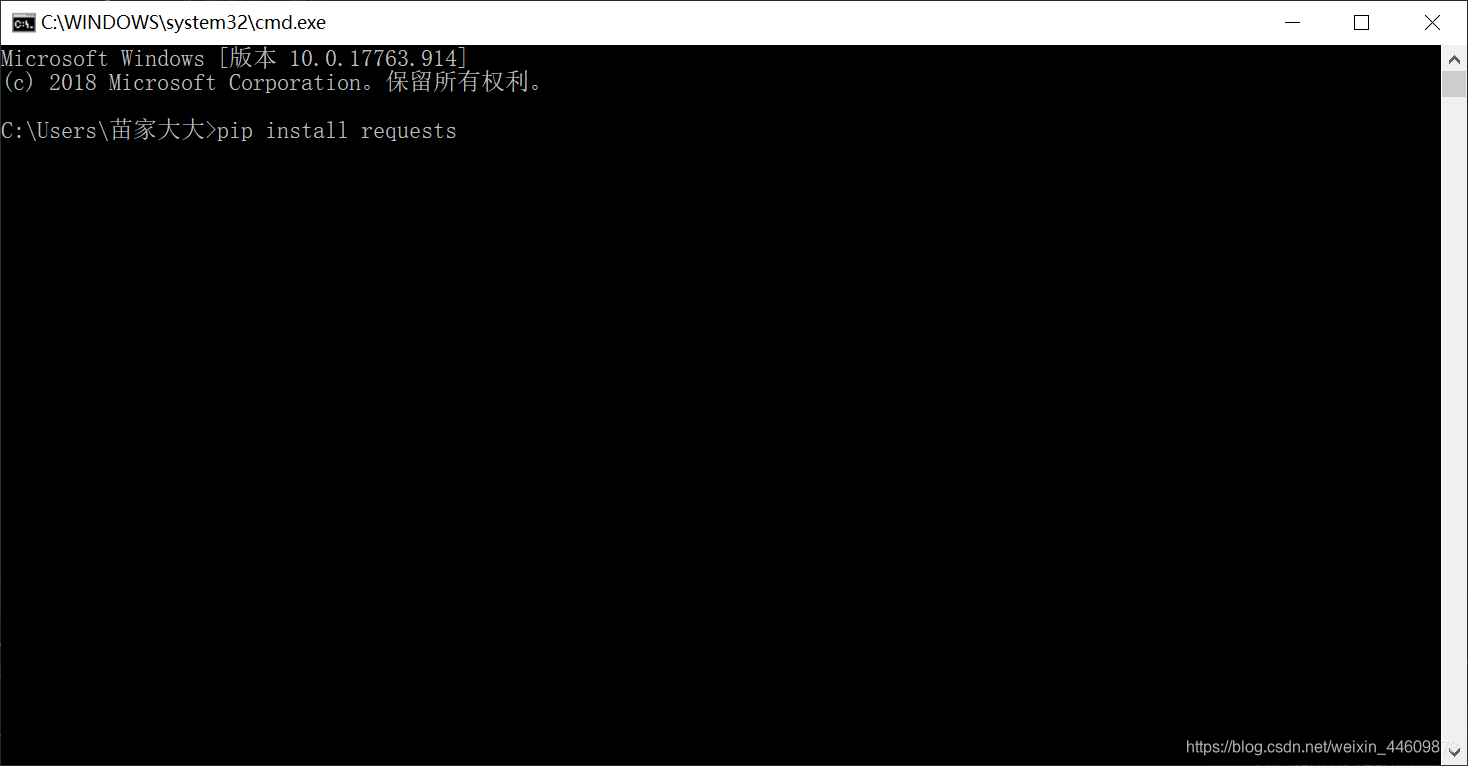
安装过程可能有点慢,耐心等待全部安装完成后,输入 python 进入交互环境
再输入
import qequests
import bs4
import lxml
验证是否正确安装
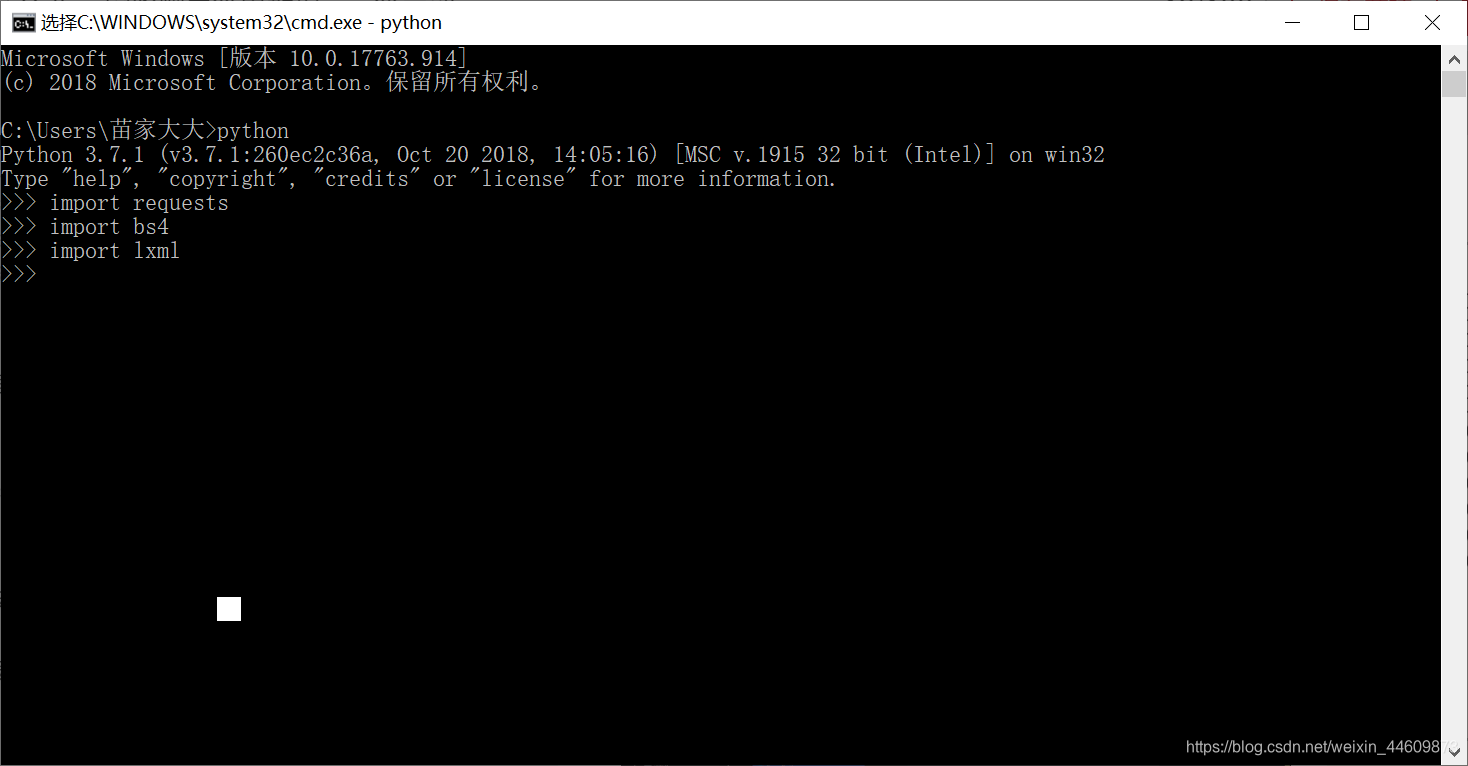
如上图所示,不报错为正确安装。
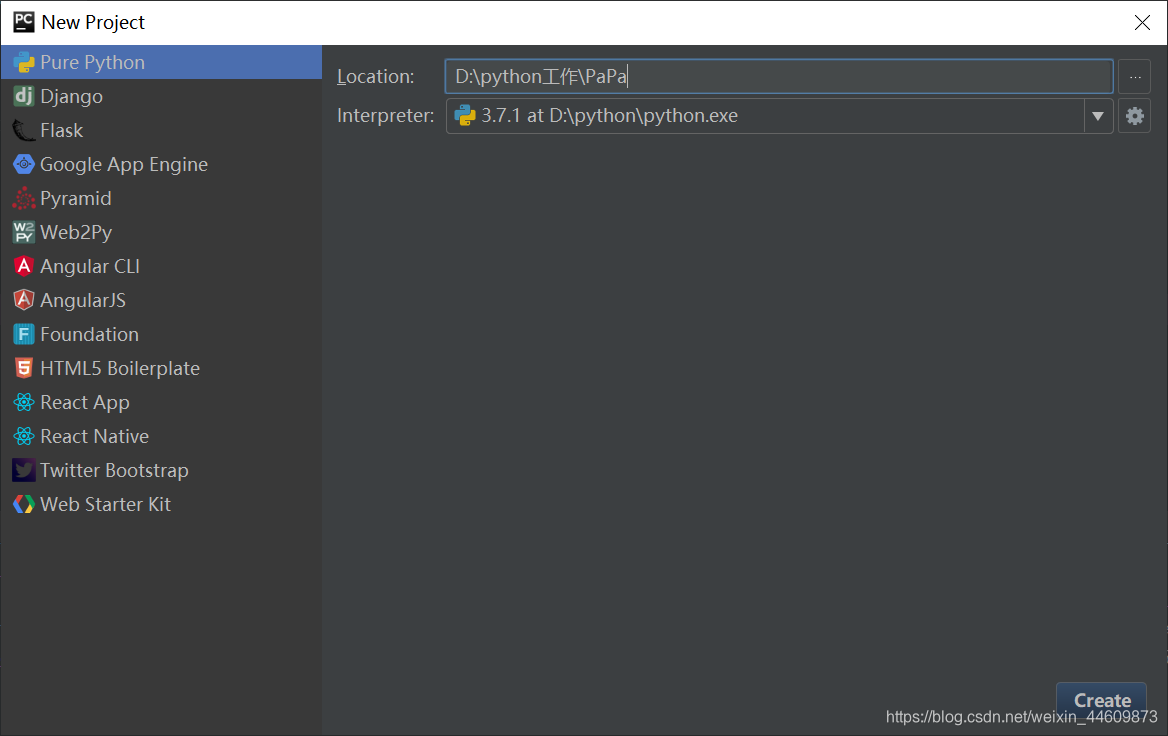
打开 pycharm,新建一个项目,这里就叫做 PaPa 吧!
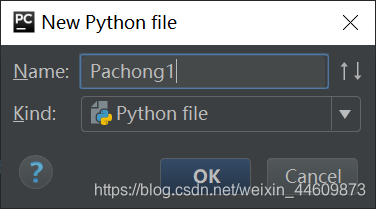
项目下新建一个 python 文件,Pachong1.py 吧
现在开始码代码吧 ,老生常谈,百度为例
import requests
# 爬取网页内容
resp = requests.get('https://www.baidu.com')
print(resp) # 打印请求结果
print(resp.content) # 打印爬取网站
- 1
- 2
- 3
- 4
- 5
- 6
运行一下,结果
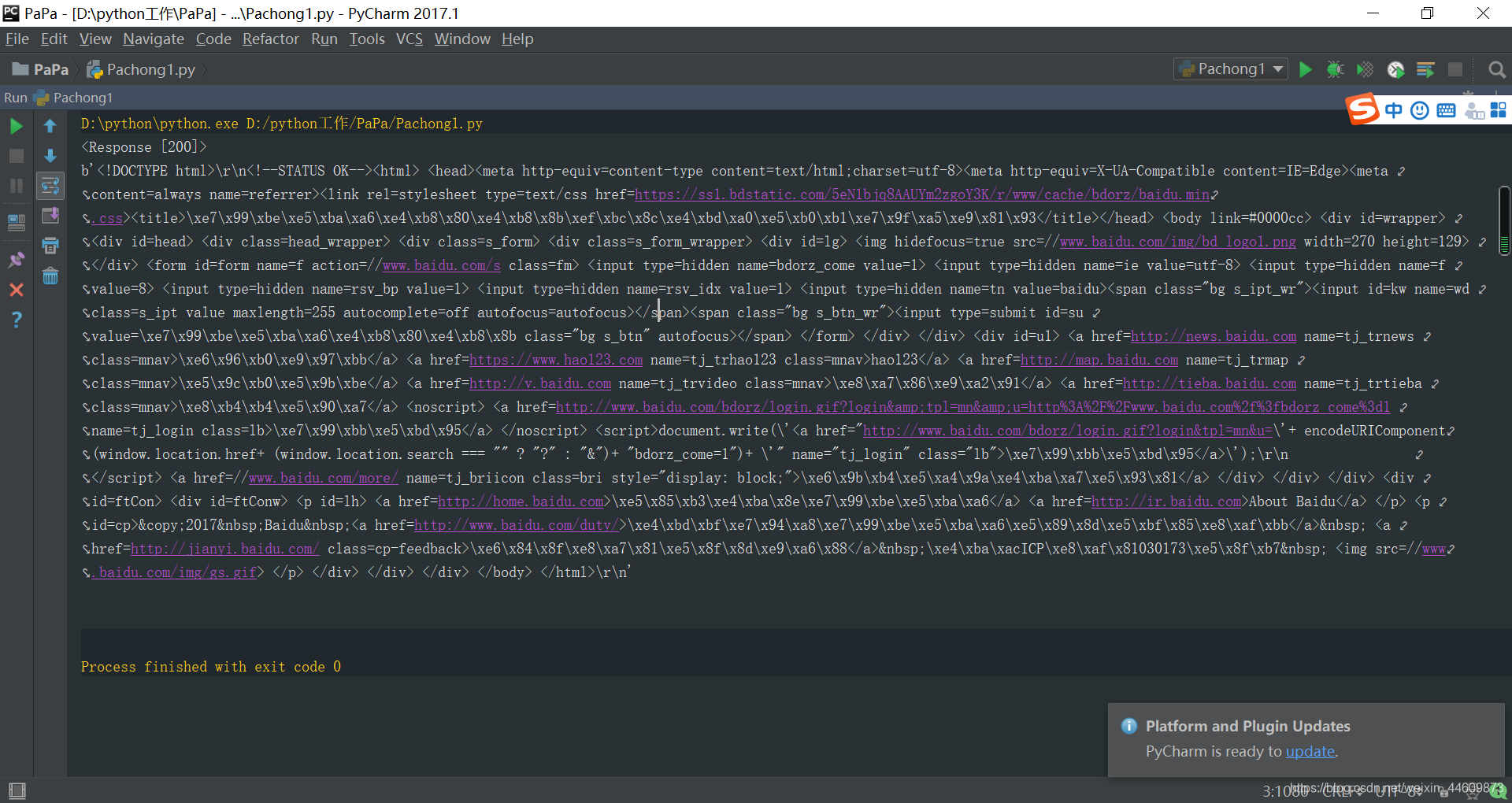
结果分析:< 200 > 说明网页正确响应了,不响应的话会报错 500 404 等等,但是纳尼!这都是源代码啊,不是应该是百度网页内容吗,不慌,小事情,这是因为 requests 请求的是网页源代码,而这些网页源码需要我们去解析自己所需的信息。
那网页源码我们拿到了,接下来就是要解析了。解析什么?解析我们需要的信息,python解析网页源码有很多种方法,比如 BeautifulSoup、re 正则表达式、pyquery、Xpath 等。
这里我使用的是 BeautifulSoup 和 lxml 搭配获取内容,这里的 lxml 是个非常有用的 python 库,它可以灵活高效地解析 xml,与BeautifulSoup、requests 结合,是编写爬虫的标准姿势。
百度不是链接多吗,好,今天就爬你链接,安排!
import requests
from bs4 import BeautifulSoup
# 爬取网页内容(源代码)
resp = requests.get('https://www.baidu.com')
print(resp) # 打印请求结果
print(resp.content) # 打印爬取网站源代码
print("\n")
# 爬取解析所有a标签对象href值
bsobj = BeautifulSoup(resp.content, 'lxml')
# a_list = bsobj.find_all('a')
a_list = bsobj.select('a')
text = ''
for a in a_list:
href = a.get('href')
print(href) # 获取a标签对象的href属性,即这个对象指向的链接地址
text += href + "\n" # 加入 text 中并换行
# 在 D:/新建文件夹text文本中(w方式,没有则自动创建一个)写入上面得到的text数据
with open('D:/新建文件夹/text.txt', 'w') as f:
f.write(text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
获取请求之后,我们用 BeautifulSoup 的 selec() 函数 a_list = bsobj.find_all('a') 、a_list = bsobj.select('a') 两个都可以来选择链接,为什么用 a 呢,因为我们知道链接一般形如
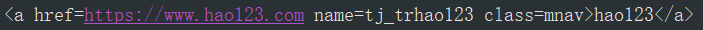
网页内容是包含在标签 a 的 href 里的,于是我们再利用 href = a.get('href') 来获取属性 href 下内容。
运行结果:
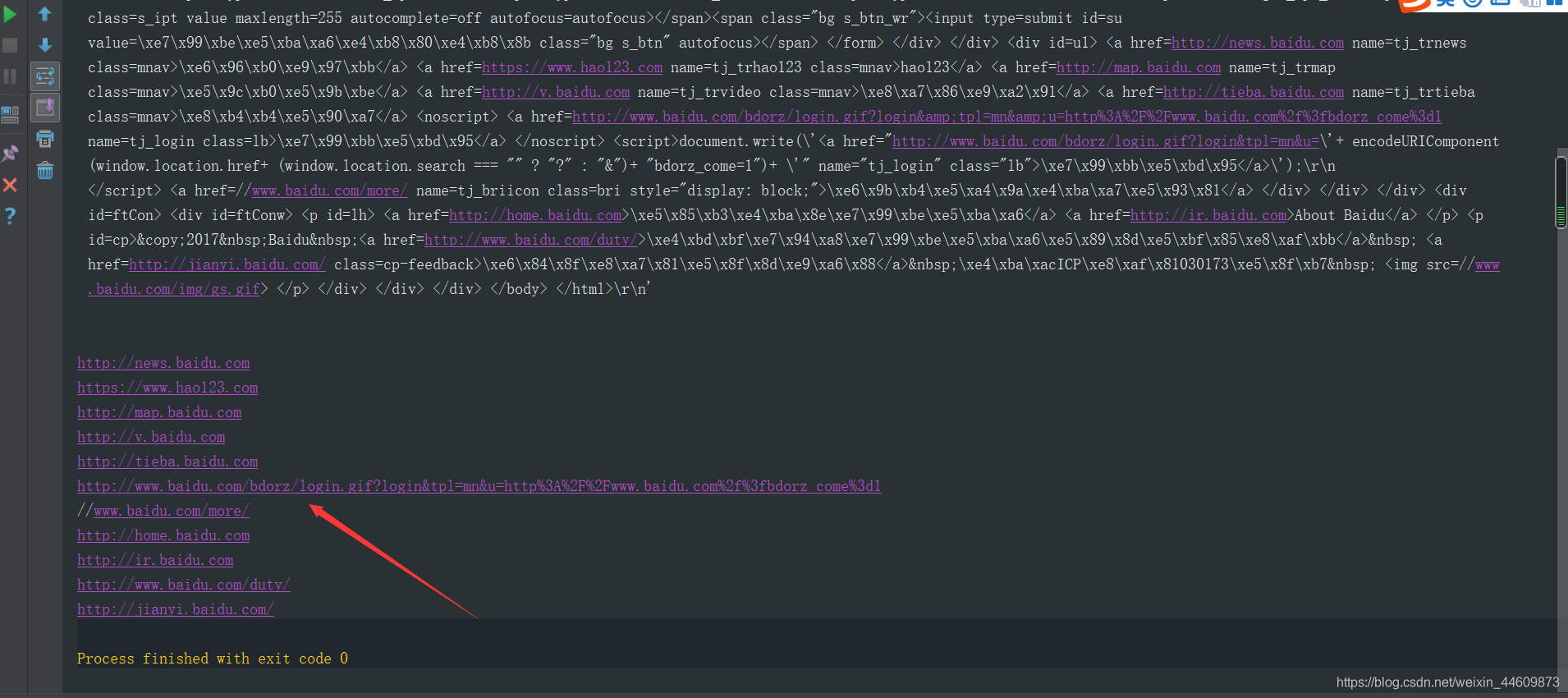
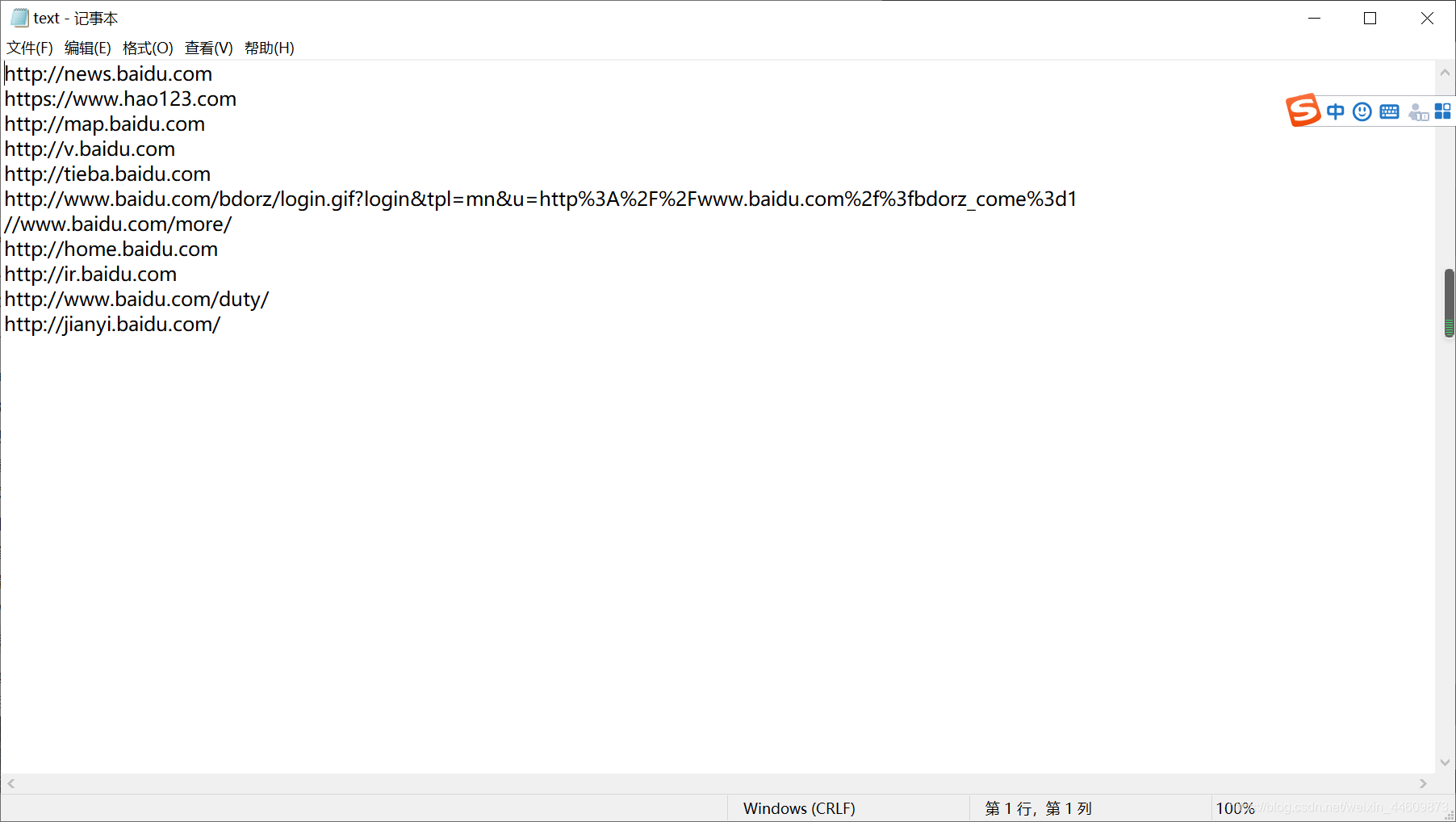
好了最近忙,匆匆忙忙赶写了几天,也学到了很多 ,下次更新爬取网站笑话、图片、视频等(emmmm不知道是几天了),不过,一起加油!!!
谢谢观看!

所属网站分类: 技术文章 > 博客
作者:doit
链接:https://www.pythonheidong.com/blog/article/176407/f00bd5db72f7038ed5f3/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
17
0
收藏该文
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力
站长公众号(new)
更多>
pdf(new)
更多>
问答(new)
更多>
游戏(new)
更多>