

Python学习日记(八) 函数
发布于2020-01-01 13:42 阅读(1126) 评论(0) 点赞(26) 收藏(1)
函数的结构:

函数的返回值:
1.当函数执行时运到return关键字将不再往下执行

def func(): print("hello world!") print("hello world!") return print("hello world!") func() #hello world! #hello world!
2.当函数不写return或者return后面不写值时它的返回值为None
def func(): print("hello world!") print(func()) # hello world! # None
3.当函数return后面写了一个值就返回该值
4.当函数后面写了多个结果则返回一个元祖,可以通过直接使用元祖来获得多个变量
def func(): return 1,5,6,7 values = func() print(values) #(1, 5, 6, 7)
为什么返回的是一个元祖数据?
当打开python解释器

python自动将逗号分隔的元素组合成一个元祖,元祖、列表、字典可以进行解包
函数的参数:

传参:就是将实际参数传递给形式参数的过程
<1>形式参数:在函数体使用的参数变量
a.位置参数:按照位置从左到右一一对应

b.默认值参数:给函数参数设定一个默认值,例如当我们调用open函数时我们默认的模式就是mode = 'r',我们就可以省去不写
def print_info(name,age,sex = 'male'): print("{} {} {}".format(name, age,sex)) print_info('Jane',age = 15) #Jane male 15
默认值也可以在实际参数中修改:
def print_info(name,age,sex = 'male'): print("{} {} {}".format(name, age,sex)) print_info('Jane',sex = 'female',age = 15) #Jane female 15
陷阱:如果默认参数的值是一个可变数据类型,那么每一次调用函数的时候,如果不传值那么就公用这个数据类型的资源
默认参数为列表:
def func(li = []): li.append(2) print(li) func() #[2] func() #[2, 2] func([]) #[2] func() #[2, 2, 2]
默认参数为字典:
def func(dic = {}): dic['a'] = 'v' print(dic) func() #{'a': 'v'} key是唯一所以每一次都是覆盖 func() #{'a': 'v'} func({}) #{'a': 'v'} func() #{'a': 'v'}
def func(k,dic = {}): dic[k] = 'v' print(dic) func('a') #{'a': 'v'} func('b') #{'a': 'v', 'b': 'v' func('c') #{'a': 'v', 'b': 'v', 'c': 'v'}
c.动态参数:
①动态接收位置参数:*args 接收所有的位置参数,再以元祖的形式赋予args
def sum_data(*args): res = 0 for i in args: res += i return res print(sum_data(1,2,3,4,7,8,-10)) #15
②动态接收关键字参数:**kwargs 接收所有的关键字参数,再以字典的形式赋予kwargs
def print_data(**kwargs): print(kwargs) print_data(name='Jane',sex='female',age=22) #{'name': 'Jane', 'sex': 'female', 'age': 22}
两种不同类型的动态参数可以一起使用,这样会大大提升参数扩展性,也解决了大多数实参一一对应的难题
<2>实际参数:在调用函数时使用的参数变量
a.位置参数:从左到右和形参的位置一一对应
def print_info(name,sex,age): print("{} {} {}".format(name,sex,age)) print_info('Jane','female',15) #Jane female 15
b.关键字参数:当用于繁杂的数据时,不需要记住参数的位置,只需要记住参数的名字即可
def print_info(name,sex,age): print("{} {} {}".format(name, sex, age)) print_info(name='Jane',sex='female',age = 15) #Jane female 15
c.混合参数:就是位置参数和关键字参数可以混合着使用
原则:当使用这种写法就一定要注意位置参数必须要在关键字参数之前
def print_info(name,sex,age): print("{} {} {}".format(name, sex, age)) print_info('Jane','female',age = 15) #Jane female 15
*的用法:
1.函数中分为打散和聚合
a.聚合:
当我们定义一个形参为args时,那么这个形参只能接受一个实参,这个实参也就是位置参数
def func(args): print(args) func('aaad')
当我们在args前加上一个星号,它可以接收多个参数,并返回一个元祖,**kwargs也有着相同的道理,结果返回一个字典,因此*在函数中有着聚合的作用
b.打散:
将具有可迭代性质的实际参数打散,相当于将这些实际参数给拆解成一个一个的组成元素当成位置参数然后传给args,**起到的是打散的作用
s = 'hello world!' li = [1,2,'a'] tu = (10,'p') def func(*args): print(args) func(*s,*li,*tu) #('h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!', 1, 2, 'a', 10, 'p')
2.函数外可以处理剩下的元素
# 之前的赋值 a,b = (1,2) print(a, b) #1 2 # 用*来处理剩下的元素 c,*d = (1, 2, 3, 4,) print(c, d) #1 [2, 3, 4] *rest, e, f = range(5) print(rest, e, f) #[0, 1, 2] 3 4 print([1, 2, *[3, 4, 5]]) # [1, 2, 3, 4, 5]
形参的顺序:
位置参数、*args、默认参数、**kwargs
命名空间:
即存放名字和值得关系。
1.内置命名空间
a.Python解释器已启动就可以使用的名字,例如print、input、list等存储于内置命名空间中
b.内置的名字在启动解释器时就会被加载进内存里
2.全局命名空间(我们写的代码,但不是函数)
即在程序由上至下执行的过程中依次加载进内存,放置了我们设置的所有变量名和函数名
3.局部命名空间(函数)
a.函数内部定义的名字
b.当调用函数的时候,才会产生这个名称空间,随着函数执行的结束,该命名空间就会被回收了
三者之间的关系:
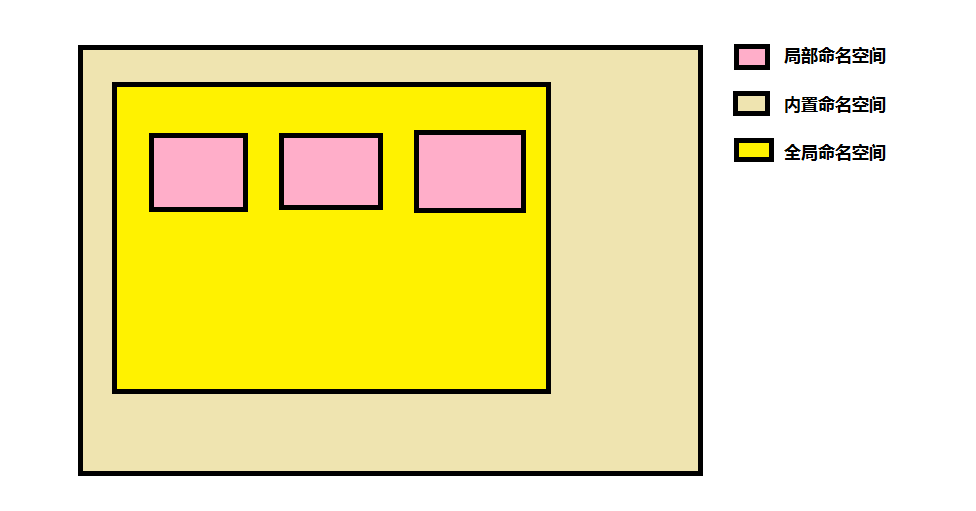
在局部命名空间:可以使用全局和内置命名空间中的名称
在全局命名空间:可以使用内置命名空间的名称,但不能在局部中使用
在内置命名空间:不能使用全局和内置命名空间中的名称
加载顺序:
内置命名空间->全局命名空间->局部命名空间
取值顺序:
局部命名空间->全局命名空间->内置命名空间
当我们在全局命名空间中定义了一个和内置命名空间中名称相同的变量,我们将会使用全局命名空间的变量。
len = 233 def func(): print(len) return func() #233 print(len('aaa')) #当我们再以内置命名空间中函数的方法去调用就会报错 # TypeError: 'int' object is not callable
取值的原则就是当自己有的时候就不会往上一级要,如果自己没有再找上一级要,直到内置命名空间中也没有就会报错。
作用域:
1.全局作用域
作用于全局和内置命名空间,全局和内置命名空间的名称都属于它
2.局部作用域
作用于局部命名空间,局部命名空间(函数)的名称都属于它
global():
对于不可变数据类型,在局部作用域中可以查看全局作用域的变量
a = 1 def func(): print(a) func() #1
如果想要修改这一变量,需要在程序开始添加global声明
a = 1 def func(): global a a += 1 return a print(func()) #2
如果在一个局部作用域(函数)内声明了一个global变量(限于字符串和数字),那么这个变量在局部作用域的所有操作都对这个全局变量有效
nonlocal():
a = 0 def fun1(): a = 1 def fun2(): a = 2 def fun3(): nonlocal a a += 1 fun3() print('this a is ',a) fun2() print('This a is ',a) fun1() print('全局: a =',a)
a,.只能用于局部变量找上一层离当前函数最近一层的局部变量,声明了nonlocal()的内部函数的变量修改会影响到离当前函数最近一层的局部变量
b.Python 3.x新增功能
c.对全局无效
d.对局部也只是对最近一层有影响
内置函数globals、locals:
a.globals():以字典的形式返回全局作用域所有的变量对应关系
a = 1 b = 2 c = 'ass' print(globals()) #{'__name__': '__main__', '__doc__': None, '__package__': None, # '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000000002665390>, #'__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, #'__file__': 'C:/Users/Administrator/PycharmProjects/Python_learn/函数操作/function', # '__cached__': None, 'a': 1, 'b': 2, 'c': 'ass'} print(locals()) #打印内容一样
b.locals():以字典的形式返回当前作用域下所有的变量对应关系
a = 1 b = 2 def func(): c = 3 d = 'css' print(globals()) #{'__name__': '__main__', '__doc__': None, '__package__': None, # '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000000002165390>, # '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, # '__file__': 'C:/Users/Administrator/PycharmProjects/Python_learn/函数操作/function', # '__cached__': None, 'a': 1, 'b': 2, 'func': <function func at 0x00000000028D9730>} print(locals()) #{'c': 3, 'd': 'css'} func()
函数的嵌套:
即函数的内部还含有一个或多个函数
def func1(a,b): return a if a > b else b def func2(a,b,c): d = func1(a,b) return func1(d,c) print(func2(5,4,3)) #5
函数名可以作为函数的返回值和参数:
def print_numbers(): print(456) def func(f): f() return f #函数名作为返回值 func2 = func(print_numbers) #456 函数名作为参数 func2() #456
函数名可以赋值:
def print_int(): print(123456) print_numbers = print_int #进行函数赋值 print_numbers()
函数名可以作为容器类型的元素:
def func1(): print(123) def func2(): print('abc') li = [func1,func2] #将两个函数封装进一个列表 for i in li: i()
闭包:
嵌套函数,内部函数调用外部函数的变量
def func(): a = 1 def get_int(): print(a) print(get_int.__closure__) #(<cell at 0x000000000272C978: int object at 0x000007FEE2ADB350>,) func()
只要出现cell字样就说明该函数是闭包
闭包可以优化掉每一次生成调用变量消耗的时间
闭包改进后:
def func(): a = 1 def get_int(): print(a) return get_int recp = func() recp()
闭包的嵌套:
def func(): a = 1 def get1(): name = 'abc' def get2(): print(a,name) return get2 return get1 recp = func() get_recp = recp() get_recp()
其他:
函数名本质就是一个内存地址
def func():
print('hello world!')
print(func) #<function func at 0x0000000002669730>该函数的内存地址
func() #函数的调用
因此我们如果把函数的内存地址后面加上括号就是在进行函数的调用。
通过函数名找到该函数的内存地址,在通过地址来调用函数内部的代码。
所属网站分类: 技术文章 > 博客
作者:短发越来越短
链接:https://www.pythonheidong.com/blog/article/198807/28a4da9516b48a58083d/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力