

python面试题----持续更新中
发布于2019-07-30 10:24 阅读(3230) 评论(0) 点赞(13) 收藏(9)
写在开头:
学习python已经好几个月了,从来没有认认真真写过一篇博客,目前正在准备面试,决定将wusir博客里关于python的315+面试题来做个python学习的一个总结
附:wusir博客园地址:https://www.cnblogs.com/wupeiqi/
第一部分 Python基础篇(80题)
-
为什么学习Python?
-
通过什么途径学习的Python?
-
Python和Java、PHP、C、C#、C++等其他语言的对比?
python 解释型语言,语法简洁优雅。 C C++ 编译型语言,先编译后运行,偏底层。 -
简述解释型和编译型编程语言?
编译型: c / c++ 运行速度快,开发效率低,不可跨平台 解释型:python / java / php 运行速度低,开发效率高,可跨平台 -
Python解释器种类以及特点?
解释器: 将python语法解释成二进制 CPython C语言写的 IPython 把CPython包装了一下 PyPy Python写的 采用JIT技术 一大块一大块编译 显著提高Python代码得执行速度 JPython Java写的 IronPython .NET写的
-
位和字节的关系? 1字节 = 8位
-
b、B、KB、MB、GB 的关系?
1B = 1Byte(字节) = 8bit(比特/位) 1GB = 1024MB 1MB = 1024KB 1KB = 1024B
-
请至少列举5个 PEP8 规范(越多越好)。
 PEP8规范
PEP8规范PEP8 Python 编码规范 一 代码编排 1 缩进。4个空格的缩进(编辑器都可以完成此功能),不使用Tap,更不能混合使用Tap和空格。 2 每行最大长度79,换行可以使用反斜杠,最好使用圆括号。换行点要在操作符的后边敲回车。 3 类和top-level函数定义之间空两行;类中的方法定义之间空一行;函数内逻辑无关段落之间空一行;其他地方尽量不要再空行。 二 文档编排 1 模块内容的顺序:模块说明和docstring—import—globals&constants—其他定义。其中import部分,又按标准、三方和自己编写顺序依次排放,之间空一行。 2 不要在一句import中多个库,比如import os, sys不推荐。 3 如果采用from XX import XX引用库,可以省略‘module.’,都是可能出现命名冲突,这时就要采用import XX。 三 空格的使用 总体原则,避免不必要的空格。 1 各种右括号前不要加空格。 2 逗号、冒号、分号前不要加空格。 3 函数的左括号前不要加空格。如Func(1)。 4 序列的左括号前不要加空格。如list[2]。 5 操作符左右各加一个空格,不要为了对齐增加空格。 6 函数默认参数使用的赋值符左右省略空格。 7 不要将多句语句写在同一行,尽管使用‘;’允许。 8 if/for/while语句中,即使执行语句只有一句,也必须另起一行。 四 注释 总体原则,错误的注释不如没有注释。所以当一段代码发生变化时,第一件事就是要修改注释! 注释必须使用英文,最好是完整的句子,首字母大写,句后要有结束符,结束符后跟两个空格,开始下一句。如果是短语,可以省略结束符。 1 块注释,在一段代码前增加的注释。在‘#’后加一空格。段落之间以只有‘#’的行间隔。比如: # Description : Module config. # # Input : None # # Output : None 2 行注释,在一句代码后加注释。比如:x = x + 1 # Increment x 但是这种方式尽量少使用。 3 避免无谓的注释。 五 文档描述 1 为所有的共有模块、函数、类、方法写docstrings;非共有的没有必要,但是可以写注释(在def的下一行)。 2 如果docstring要换行,参考如下例子,详见PEP 257 """Return a foobang Optional plotz says to frobnicate the bizbaz first. """ 六 命名规范 总体原则,新编代码必须按下面命名风格进行,现有库的编码尽量保持风格。 1 尽量单独使用小写字母‘l’,大写字母‘O’等容易混淆的字母。 2 模块命名尽量短小,使用全部小写的方式,可以使用下划线。 3 包命名尽量短小,使用全部小写的方式,不可以使用下划线。 4 类的命名使用CapWords的方式,模块内部使用的类采用_CapWords的方式。 5 异常命名使用CapWords+Error后缀的方式。 6 全局变量尽量只在模块内有效,类似C语言中的static。实现方法有两种,一是__all__机制;二是前缀一个下划线。 7 函数命名使用全部小写的方式,可以使用下划线。 8 常量命名使用全部大写的方式,可以使用下划线。 9 类的属性(方法和变量)命名使用全部小写的方式,可以使用下划线。 9 类的属性有3种作用域public、non-public和subclass API,可以理解成C++中的public、private、protected,non-public属性前,前缀一条下划线。 11 类的属性若与关键字名字冲突,后缀一下划线,尽量不要使用缩略等其他方式。 12 为避免与子类属性命名冲突,在类的一些属性前,前缀两条下划线。比如:类Foo中声明__a,访问时,只能通过Foo._Foo__a,避免歧义。如果子类也叫Foo,那就无能为力了。 13 类的方法第一个参数必须是self,而静态方法第一个参数必须是cls。 七 编码建议 1 编码中考虑到其他python实现的效率等问题,比如运算符‘+’在CPython(Python)中效率很高,都是Jython中却非常低,所以应该采用.join()的方式。 2 尽可能使用‘is’‘is not’取代‘==’,比如if x is not None 要优于if x。 3 使用基于类的异常,每个模块或包都有自己的异常类,此异常类继承自Exception。 4 异常中不要使用裸露的except,except后跟具体的exceptions。 5 异常中try的代码尽可能少。比如: try: value = collection[key] except KeyError: return key_not_found(key) else: return handle_value(value) 要优于 try: # Too broad! return handle_value(collection[key]) except KeyError: # Will also catch KeyError raised by handle_value() return key_not_found(key) 6 使用startswith() and endswith()代替切片进行序列前缀或后缀的检查。比如: Yes: if foo.startswith('bar'):优于 No: if foo[:3] == 'bar': 7 使用isinstance()比较对象的类型。比如 Yes: if isinstance(obj, int): 优于 No: if type(obj) is type(1): 8 判断序列空或不空,有如下规则 Yes: if not seq: if seq: 优于 No: if len(seq) if not len(seq) 9 字符串不要以空格收尾。 10 二进制数据判断使用 if boolvalue的方式。
- 通过代码实现如下转换:
二进制转换成十进制:v = “0b1111011”
十进制转换成二进制:v = 18
八进制转换成十进制:v = “011”
十进制转换成八进制:v = 30
十六进制转换成十进制:v = “0x12”
十进制转换成十六进制:v = 87v = "0b1111011" >>> int("0b1111011",2) v = 18 >>> bin(18) '0b10010' v = "011" >>> int("011",8) v = 30 >>> oct(30) '0o36' v = "0x12" >>> int("0x12",16) v = 87 >>> hex(87) '0x57' -
请编写一个函数实现将IP地址转换成一个整数。
如 10.3.9.12 转换规则为:
10 00001010
3 00000011
9 00001001
12 00001100
再将以上二进制拼接起来计算十进制结果:00001010 00000011 00001001 00001100 = ?def func(str_ip): arr = str_ip.split(".") temp = [] for i in arr: t = bin(int(i))[2:] s = t.rjust(8,'0') temp.append(s) str_temp = "".join(temp) print(int(str_temp,2)) # 167971084 func("10.3.9.12")
-
python递归的最大层数? 1000
>>> import sys >>> sys.getrecursionlimit() 1000
- 求结果:
v1 = 1 or 3
v2 = 1 and 3
v3 = 0 and 2 and 1
v4 = 0 and 2 or 1
v5 = 0 and 2 or 1 or 4
v6 = 0 or Flase and 1v1 = 1 or 3 # 1 从左到右扫描,返回第一个为真的表达式值,无真值则返回最后一个表达式值 v2 = 1 and 3 # 3 从左到右扫描,返回第一个为假的表达式值,无假值则返回最后一个表达式值。 v3 = 0 and 2 and 1 # 0 v4 = 0 and 2 or 1 # 1 v5 = 0 and 2 or 1 or 4 #1 v6 = 0 or Flase and 1 # False -
ascii、unicode、utf-8、gbk 区别?
utf-8 占3个字节 中文 gbk 占2个字节 中文 unicode 占2个字节 ascii: 占1个字节,一套电脑编码系统,最多只能只能表示256个字符,主要用于显示英语字符和其他西欧语言。 显然ascii无法将世界上的各种文字和符号全部表示,所以就出现了一种可以代替所有字符和符号的编码,即 unicode Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码,占2个字节。 UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存(中文,占3个自己)
-
字节码和机器码的区别?
C语言,代码编译之后得到机器码: 机器码在处理器上直接执行,每一条指令控制cpu工作。 python语言,代码编译得到字节码,虚拟机上执行字节码并转换成机器码之后再到处理器上执行。 执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。 ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
-
三元运算规则以及应用场景?
result = 值1 if 条件 else 值2
ambda 表达式 temp = lambda x,y:x+y print(temp(4,10)) # 14 可替代: def foo(x,y): return x+y print(foo(4,10)) # 14 -
列举 Python2和Python3的区别?
python3 & python2的区别主要体现在以下几个方面: 1.python3中print是一个内置函数,有多个参数,而python2中print是一个语法结构; 2.Python2打印时可以不加括号:print 'hello world', Python3则需要加括号 print("hello world") 3.Python2中,input要求输入的字符串必须要加引号,为了避免读取非字符串类型发生的一些行为,不得不使用raw_input()代替input() 下面通过以下几点给大家介绍Python2与Python3的不同点,具体内容如下所述: 1、规范性 1)、在大的环境下,Python2含有PHP、Java、C等语言的规范陋习。(Python是一门开源的语言,任何人都可以贡献代码,但是每个人上传的代码规范都不相同。) 2)、Python2里面重复的代码特别多。 3)、Python3编码规范、清晰、简单,符合Python的宗旨。 2、编码 1)、Python2默认编码是ASCII,只能显示英文,显示中文会报错。想让Python2显示中文,就需在首行添加“# -*- encoding:utf-8 -*-”。 2)、Python3的默认编码就是utf-8,中文和英文都能支持。 3、语法 1)、用户交互:Python2的语法是“ raw_input”,而Python3的语法是“input”。 4、数据类型 1)、Python2里既有 int 类型又有 long int 类型,而Python3里只有 int 类型。 Python2中input的坑 ? 1 2 3 print ("what do you like") a = input("Enter any content:") print ("i like",a) 输入字符串时会报错,而在python3中很好地解决了这个问题。
-
用一行代码实现数值交换:
a = 1
b = 2a, b = b, a
-
Python3和Python2中 int 和 long的区别?

-
xrange和range的区别?
都在循环时使用,xrange内存性能更好,xrange用法与range完全相同,range一个生成list对象,xrange是生成器 要生成很大的数字序列的时候,用xrange会比range性能优很多,因为不需要一上来就开辟一块很大的内存空间。 在python2中: range([start,] stop[, step]),根据start与stop指定的范围以及step设定的步长,生成一个序列 例子 xrange用法与range完全相同,所不同的是生成的不是一个数组,而是一个生成器。 例子 由上面的示例可以知道:要生成很大的数字序列的时候,用xrange会比range性能优很多,因为不需要一上来就开辟一块很大的内存空间,这两个基本上都是在循环的时候用。 在 Python 3 中,range() 是像 xrange() 那样实现,xrange()被抛弃。 -
文件操作时:xreadlines和readlines的区别?
readlines 返回一个列表 xreadlines 返回一个生成器 -
列举布尔值为False的常见值?
0, '', {}, [], set() -
字符串、列表、元组、字典每个常用的5个方法?
1 caplitalize 2 upper 3 lower 4 find 5 rfind 6 center 7 ljust 8 rjust 9 format 10 index 11 strip 12 lstrip() 13 rstrip() 14 15 append 16 insert 17 extend 18 count 19 pop 20 sort 21 reverse 22 remove 23 li[2:5] = [1, 2, 3] = ['HELLO', 1, 3] 24 li[0:6:2] = ['HELLO', 1, 3] 25 26 .get 27 keys 28 values 29 items 30 pop 31 update
-
lambda表达式格式以及应用场景?
匿名函数: 为了解决那些功能很简单的需求而设计的一句话函数 匿名 = lambda 参数: 返回值 # 参数可以有多个,用逗号隔开 # 匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值 # 返回值和正常的函数一样可以是任意数据类型
-
pass的作用?
Python pass是空语句,是为了保持程序结构的完整性。 pass 不做任何事情,一般用做占位语句。
-
*arg和**kwarg作用
*args: 代表位置参数, 他会接受任意多个参数并把这些参数作为元祖传递给函数. **kwargs代表的关键字参数, 返回的是字典,位置参数一定要放在关键字前面
-
is和==的区别
python对象包含3要素 id type value id 用来唯一标识一个对象,type标识对象的类型,value是对象的值 is 判断的是 a对象是否是b对象, 是通过id来判断的。 == 判断的是 a对象的值是否是b对象的值,是通过的value来判断的。
-
简述Python的深浅拷贝以及应用场景?
浅拷贝只是增加了一个指针指向一个存在的地址 而深拷贝是增加一个指针并且开辟了新的内存,这个增加的指针指向这个新的内存,采用浅拷贝的情况,释放内存,会释放同一块内存,深拷贝就不会出现释放 一层的情况: import copy # 浅拷贝 li1 = [1, 2, 3] li2 = li1.copy() li1.append(4) print(li1, li2) # [1, 2, 3, 4] [1, 2, 3] # 深拷贝 li1 = [1, 2, 3] li2 = copy.deepcopy(li1) li1.append(4) print(li1, li2) # [1, 2, 3, 4] [1, 2, 3] 多层的情况: import copy # 浅拷贝 指向共有的地址 li1 = [1, 2, 3,[4,5],6] li2 = li1.copy() li1[3].append(7) print(li1, li2) # [1, 2, 3, [4, 5, 7], 6] [1, 2, 3, [4, 5, 7], 6] # 深拷贝 重指向 li1 = [1, 2, 3,[4,5],6] li2 = copy.deepcopy(li1) li1[3].append(7) print(li1, li2) # [1, 2, 3, [4, 5, 7], 6] [1, 2, 3, [4, 5], 6]
-
Python垃圾回收机制?
引用计数 标记清除 分代回收
GIL全局解释器锁 -
Python的可变类型和不可变类型?
可变数据类型: 列表,字典,可变集合 不可变数据类型: 数字,字符串,元祖, 不可变集合
- 求结果:
v = dict.fromkeys(['k1','k2'],[])
v[‘k1’].append(666)
print(v)
v[‘k1’] = 777
print(v)
View Codev = dict.fromkeys(['k1', 'k2'], []) v['k1'].append(666) print(v) v['k1'] = 777 print(v) 结果: {'k1': [666], 'k2': [666]} {'k1': 777, 'k2': [666]} 解释: Python 字典(Dictionary) fromkeys() 函数用于创建一个新字典,以序列seq中元素做字典的键,value为字典所有键对应的初始值,默认为None。 v1 = dict.fromkeys(['k1', 'k2']) print(v1) # {'k1': None, 'k2': None} v2 = dict.fromkeys(['k1', 'k2'], []) print(v2) # {'k1': [], 'k2': []}
- 求结果:
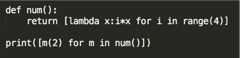
#解释: 函数返回值为一个列表表达式,经过4次循环结果为包含四个lambda函数的列表, 由于函数未被调用,循环中的i值未被写入函数,经过多次替代,循环结束后i值为3, 故结果为:6,6,6,6
-
列举常见的内置函数?
-
filter、map、reduce的作用?
-
一行代码实现9*9乘法表
-
如何安装第三方模块?以及用过哪些第三方模块?
-
至少列举8个常用模块都有那些?
-
re的match和search区别?
-
什么是正则的贪婪匹配?
-
求结果: a. [ i % 2 for i in range(10) ] b. ( i % 2 for i in range(10) )
-
求结果: a. 1 or 2 b. 1 and 2 c. 1 < (2==2) d. 1 < 2 == 2
-
def func(a,b=[]) 这种写法有什么坑?
-
如何实现 “1,2,3” 变成 [‘1’,’2’,’3’] ?
-
如何实现[‘1’,’2’,’3’]变成[1,2,3] ?
-
比较: a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的区别?
-
如何用一行代码生成[1,4,9,16,25,36,49,64,81,100] ?
-
一行代码实现删除列表中重复的值 ?
-
如何在函数中设置一个全局变量 ?
-
logging模块的作用?以及应用场景?
-
请用代码简答实现stack 。
-
常用字符串格式化哪几种?
-
简述 生成器、迭代器、可迭代对象 以及应用场景?
-
用Python实现一个二分查找的函数。
-
谈谈你对闭包的理解?
-
os和sys模块的作用?
-
如何生成一个随机数?
-
如何使用python删除一个文件?
-
谈谈你对面向对象的理解?
-
Python面向对象中的继承有什么特点?
-
面向对象深度优先和广度优先是什么?
-
面向对象中super的作用?
-
是否使用过functools中的函数?其作用是什么?
-
列举面向对象中带爽下划线的特殊方法,如:__new__、__init__
-
如何判断是函数还是方法?
-
静态方法和类方法区别?
-
列举面向对象中的特殊成员以及应用场景
-
1、2、3、4、5 能组成多少个互不相同且无重复的三位数
-
什么是反射?以及应用场景?
-
metaclass作用?以及应用场景?
-
用尽量多的方法实现单例模式。
-
装饰器的写法以及应用场景。
-
异常处理写法以及如何主动跑出异常(应用场景)
-
什么是面向对象的mro
-
isinstance作用以及应用场景?
- 写代码并实现:
Given an array of integers, return indices of the two numbers such that they add up to a specific target.You may assume that each input would
have exactly one solution, and you may not use the same element twice.
Example:
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1] -
json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
-
json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办?
-
什么是断言?应用场景?
-
有用过with statement吗?它的好处是什么?
-
使用代码实现查看列举目录下的所有文件。
-
简述 yield和yield from关键字。

所属网站分类: 技术文章 > 博客
作者:hello树先生
链接:https://www.pythonheidong.com/blog/article/2296/9b00d303bdad4431cea2/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力