本站消息


Python:爬取疫情每日数据
发布于2020-02-17 21:33 阅读(2201) 评论(0) 点赞(22) 收藏(5)
前言
有部分同学留言说为什么412,这是因为我代码里全国的cookies需要你自己打开浏览器更新好后替换,而且这个cookies大概只能持续20秒左右!
另外全国卫健委的数据格式一直在变,也有可能会导致爬取失败!
我现在已根据2月14日最新通报稿的格式修正了!
目前每天各大平台,如腾讯、今日头条都会更新疫情每日数据,他们的数据源都是一样的,主要都是通过各地的卫健委官网通报。
为什么已经有大量平台做了每日跟踪了,我还要爬数据呢?
这是因为各大平台为了统一各省市数据的格式,会有意无意地忽略一些不是特别关键的数据,同时即使是卫健委官网的数据里,也隐含了一些不容易发现的数据。
1、以上海卫健委的数据为例,缺少了“当日新增疑似数”,只有“当前累计疑似数”,这就需要我们根据“累计排除疑似数”、“累计确诊数”和“当前累计疑似数”三者相加后,与前一天三者之和相减来获得。
2、又比如在一开始,国家卫健委的数据里是没有湖北当日新增数的(后来加进去了),这也使得我们只有把2个卫健委的数据都获得后简单计算才能获得。
3、再比如我最后有张表格,是四率:重症率、死亡率、治愈率和确诊率,这些都是比较有用的数据。
以全国、湖北和上海为例,分别为以下三个网站:
国家卫健委官网:http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml
湖北卫健委官网:http://wjw.hubei.gov.cn/bmdt/ztzl/fkxxgzbdgrfyyq/xxfb/
上海卫健委官网:http://wsjkw.sh.gov.cn/xwfb/index.html
其中上海的卫健委官网数据比较好爬,虽然需要使用cookies,但是用chrome登录后即可自动获取。
国家卫健委使用的反爬技术比较高,首先网站是shtml,cookies一直在变,我实测基本在20秒不到就会变化一次;另外做了selenium检测,所以selenium爬虫是无用的。
网上有反反爬的技术,只是暂时我还没有时间研究,等以后再看吧。
另:今天早上在测试代码的时候,上海的数据经常会出现无响应的情况,原因不知。
代码
import requests
from bs4 import BeautifulSoup
import datetime
import re
from selenium import webdriver
import time
import xlwings as xw
def get_sh_data(url):
'''获得上海卫健委的数据'''
r = requests.get(url=url, headers=sh_headers)
sh_dict = {}
soup = BeautifulSoup(r.text, 'lxml')
# print(soup)
ivs_content = soup.find(name='div', attrs={'id':'ivs_content', 'class':'Article_content'})
new_text = ivs_content.get_text()
# print(new_text)
sh_dict['累计排除疑似'] = re.search('已累计排除疑似病例(\d+)例', new_text).group(1)
sh_dict['累计确诊'] = re.search('发现确诊病例(\d+)例', new_text).group(1)
style2 = '(\d+)例病情危重,(\d+)例重症,(\d+)例治愈出院,(\d+)例死亡'
sh_dict['累计重症'] = int(re.search(style2, new_text).group(1)) + int(re.search(style2, new_text).group(2))
sh_dict['累计治愈'] = re.search(style2, new_text).group(3)
sh_dict['累计死亡'] = re.search(style2, new_text).group(4)
sh_dict['累计疑似'] = re.search('尚有(\d+)例疑似病例正在排查中', new_text).group(1)
return sh_dict
def get_sh_today_news():
'''获得上海卫健委的新闻'''
url = r'http://wsjkw.sh.gov.cn/xwfb/index.html'
r = requests.get(url=url, headers=sh_headers)
soup = BeautifulSoup(r.text, 'lxml')
# print(soup)
today_format = datetime.datetime.today().strftime('%Y-%m-%d')
today_sh_news = soup.find_all(name='span', text=today_format)
today_counts = len(today_sh_news)
for i in range(today_counts-1, -1, -1):
title = today_sh_news[i].find_previous_sibling(name='a').attrs['title'] # 标题
href = 'http://wsjkw.sh.gov.cn' + today_sh_news[i].find_previous_sibling(name='a').attrs['href'] #网址
if title.startswith('上海新增'):
# print(title)
return get_sh_data(href)
def get_all_today_news():
'''获得国家卫健委的新闻'''
url = 'http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml'
r = requests.get(url, headers=quanguo_headers)
soup = BeautifulSoup(r.text, 'lxml')
# print(soup)
today_format = datetime.datetime.today().strftime('%Y-%m-%d')
latest_news_title = soup.find(name='span', text=today_format).find_previous_sibling(name='a').attrs['title']
latest_news_href = 'http://www.nhc.gov.cn' + soup.find(name='span', text=today_format).find_previous_sibling(name='a').attrs['href']
# print(latest_news_href)
return get_all_today_data(latest_news_href)
def get_all_today_data(url):
'''获得国家卫健委的数据'''
r = requests.get(url, headers=quanguo_headers)
all_dict = {}
hubei_dict = {}
soup = BeautifulSoup(r.text, 'lxml')
news = soup.find(name='p').get_text()
# print(news)
all_dict['新增疑似'] = re.search('新增疑似病例(\d+)例', news).group(1)
all_dict['累计疑似'] = re.search('现有疑似病例(\d+)例', news).group(1)
all_dict['累计确诊'] = re.search('累计报告确诊病例(\d+)例', news).group(1)
all_dict['累计重症'] = re.search('其中重症病例(\d+)例', news).group(1)
all_dict['累计死亡'] = re.search('累计死亡病例(\d+)例', news).group(1)
all_dict['累计治愈'] = re.search('累计治愈出院病例(\d+)例', news).group(1)
hubei_dict['新增疑似'] = re.search('新增疑似病例(\d+)例.*?(武汉(\d+)例', news).group(1)
hubei_dict['新增确诊'] = re.search('湖北新增确诊病例(\d+)例.*?(武汉(\d+)例', news).group(1)
hubei_dict['新增死亡'] = re.search('新增死亡病例(\d+)例.*?(武汉(\d+)例', news).group(1)
hubei_dict['新增治愈'] = re.search('新增治愈出院病例(\d+)例(武汉(\d+)例)', news).group(1)
hubei_dict['累计重症'] = re.search('其中重症病例(\d+)例.*?(武汉(\d+)例', news).group(1)
# print(all_dict, hubei_dict)
return all_dict, hubei_dict
def get_cookie(url):
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
cookies = driver.get_cookies()
driver.quit()
items = []
for i in range(len(cookies)):
cookie_value = cookies[i]
item = cookie_value['name'] + '=' + cookie_value['value']
items.append(item)
cookiestr = '; '.join(a for a in items)
return cookiestr
def get_into_excel():
'''把数据贴到excel里'''
app = xw.App(visible=True, add_book=False)
app.display_alerts = False
app.screen_updating = False
wb = app.books.open('新型冠状病毒每日数据.xlsx')
ws = wb.sheets['all']
max_row = ws.api.UsedRange.Rows.count
ws.range('C' + str(max_row)).value = hubei_data['新增确诊']
ws.range('K' + str(max_row)).value = hubei_data['新增死亡']
ws.range('O' + str(max_row)).value = hubei_data['新增治愈']
ws.range('S' + str(max_row)).value = hubei_data['新增疑似']
ws.range('AA' + str(max_row)).value = hubei_data['累计重症']
ws.range('R' + str(max_row)).value = all_data['新增疑似']
ws.range('AL' + str(max_row)).value = all_data['累计疑似']
ws.range('V' + str(max_row)).value = all_data['累计确诊']
ws.range('Z' + str(max_row)).value = all_data['累计重症']
ws.range('AD' + str(max_row)).value = all_data['累计死亡']
ws.range('AH' + str(max_row)).value = all_data['累计治愈']
ws.range('AN' + str(max_row)).value = sh_data['累计排除疑似']
ws.range('Y' + str(max_row)).value = sh_data['累计确诊']
ws.range('AC' + str(max_row)).value = sh_data['累计重症']
ws.range('AK' + str(max_row)).value = sh_data['累计治愈']
ws.range('AG' + str(max_row)).value = sh_data['累计死亡']
ws.range('AM' + str(max_row)).value = sh_data['累计疑似']
wb.save()
wb.close()
app.quit()
if __name__ == "__main__":
sh_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Cookie': get_cookie('http://wsjkw.sh.gov.cn/xwfb/index.html'),
# 'Cookie': 'zh_choose=s; zh_choose=s; _gscu_2010802395=80620430ie0po683; yd_cookie=12f170fc-e368-4a662db5220af2d434160e259b2e31585efb; _ydclearance=2cd0a8873fd311efcda1c1aa-05fc-4001-a108-0e86b80b3fee-1580700296; _gscbrs_2010802395=1; _pk_ref.30.0806=%5B%22%22%2C%22%22%2C1580693101%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DDVUbOETLyMZLC5c_V7RJRbAYPvyqaU3f2PCBi2-E6KC2QEFltdrKWGmhgA5NbC3c%26wd%3D%26eqid%3Df38b30250015e1c5000000045e365a8d%22%5D; _pk_ses.30.0806=*; _pk_id.30.0806=35b481da38abb562.1580620431.6.1580694952.1580693101.; _gscs_2010802395=80693100qds57e17|pv:6; AlteonP=ALa1BGHbHKyWUqcNUGRETw$$',
'Host': 'wsjkw.sh.gov.cn'
}
quanguo_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Cookie': 'oHAcoULcWCQb80S=pxzexGFCvyGV4xDkaMHSyjBmzwXn5O4vfCbxFCgMDfcBaKqsFU9FHstqjFY6wJt9; yfx_c_g_u_id_10006654=_ck20020209283417867964364567575; _gscu_2059686908=81579037nbf5xc58; insert_cookie=67313298; yfx_f_l_v_t_10006654=f_t_1580606914774__r_t_1581643181169__v_t_1581678949269__r_c_14; security_session_verify=a2efd6893c3ad08675db9b0f5c365ecf; oHAcoULcWCQb80T=4Ywh2qE8IiJP44ThdpW0fs7Yqi1Hwlh9RhJHrW2WVl536y4eCIgXxGh9M8IuYUqGUCCtBO5kBc2DB6Kewd3naLK_O2bK5W3w3pcqT.uX3asTXxC2SGBqy9eV2DoGB0ZXb4uTPzPGbXebmT6xIYxbAmGbm_kZVX_nUvBL4nkAuFAVvcGLBmXr8nsdEToXztqZUlYnTjn9niwHMcg3th7XhJvFS_tckqRq5bLpvS_IKPuYn2JLraIIejlErBhA5IQhyHXFekNynv5PYgpzu2PguGccrP3c_bcg1MFViQjKVhgs_B22Nv4NxdHdiIk9GdZDZBjQ',
'Host': 'www.nhc.gov.cn'
}
#一、全国和湖北的数据
all_data, hubei_data, sh_data = {}, {}, {}
try:
all_data, hubei_data = get_all_today_news()
print('全国数据:{}\n'
'湖北数据:{}'.format(all_data, hubei_data))
except:
print('全国数据未更新')
#二、上海的数据
try:
sh_data = get_sh_today_news()
print('上海数据:{}'.format(sh_data))
except:
print('上海数据未更新')
#三、导出到excel里
if sh_data != {} and all_data != {}:
get_into_excel()
print('Excel刷新成功!')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
成果

获得数据后就可以做很多事情了,比如放到excel里,比如直接matplotlib作图,又或者做arima预测。
比如我做了个简单的excel,如下图所示(红色部分是爬取到的数据):
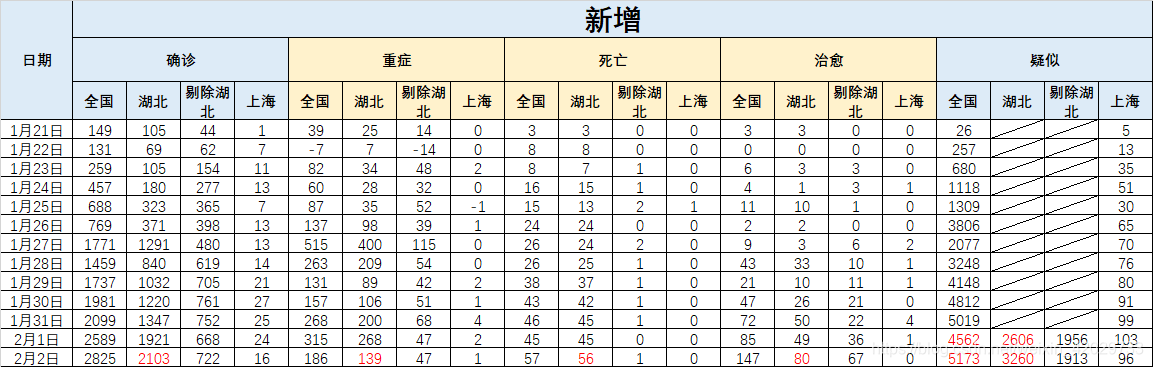
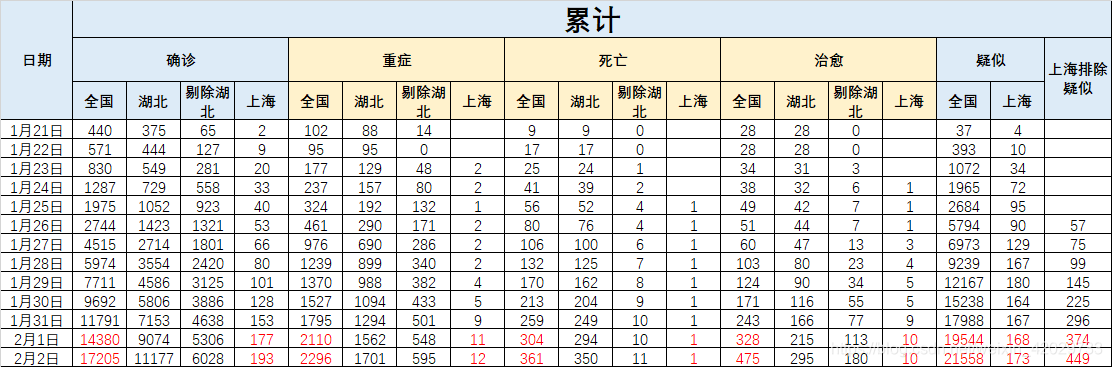
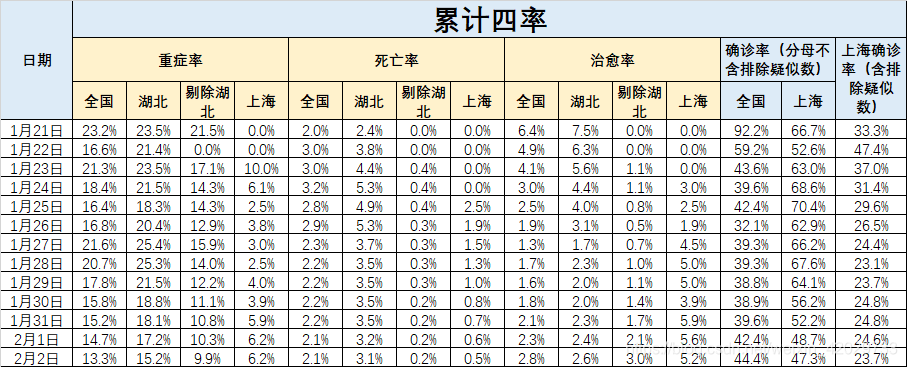

所属网站分类: 技术文章 > 博客
作者:头疼不是病
链接:https://www.pythonheidong.com/blog/article/231683/3e343efef00abed5c724/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
22
0
收藏该文
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力
站长公众号(new)
更多>
pdf(new)
更多>
问答(new)
更多>
游戏(new)
更多>