本站消息


【新手专属】Python写一个爬取静态网站的爬虫(讲解)
发布于2020-02-24 21:52 阅读(778) 评论(0) 点赞(25) 收藏(3)
"’
前言:
这篇文章是以Python3.8.1为基础的
用的IDE是PyCharm2019.3.3
用的库有BeautifulSoup4 和 requests
没有的可以先用这两行代码在Win+r中输入cmd的界面中下载
pip install beautifulsoup4
pip install requests
- 1
- 2
"’
先随便找一个静态图片网站
比如我这边找了一个表情图片网站:
http://www.17qq.com/bq-jinguanzhang.html
先打开开发者工具
按F5 或者右键鼠标,点击检查(推荐Google浏览器)
然后点击Network界面
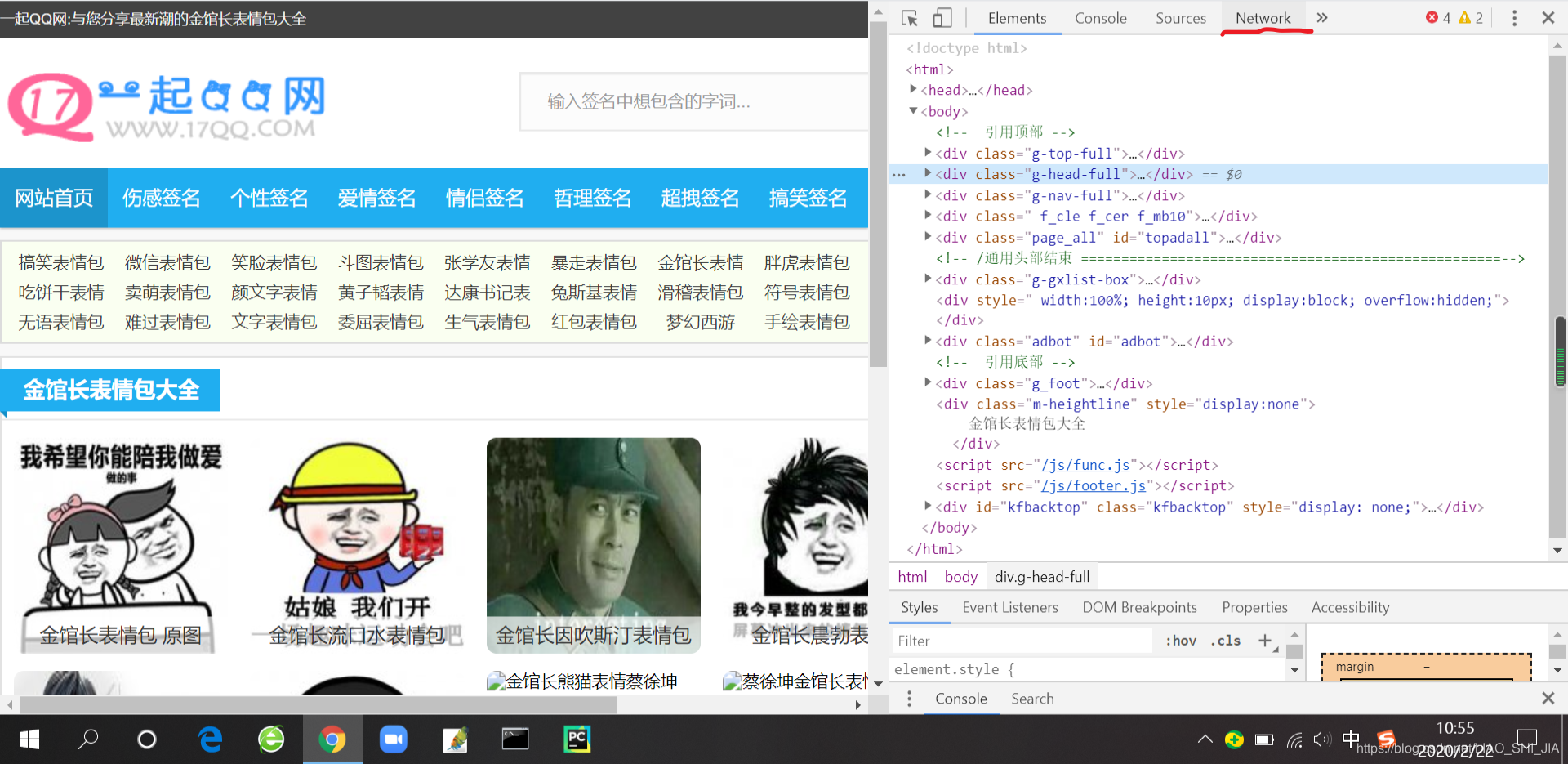
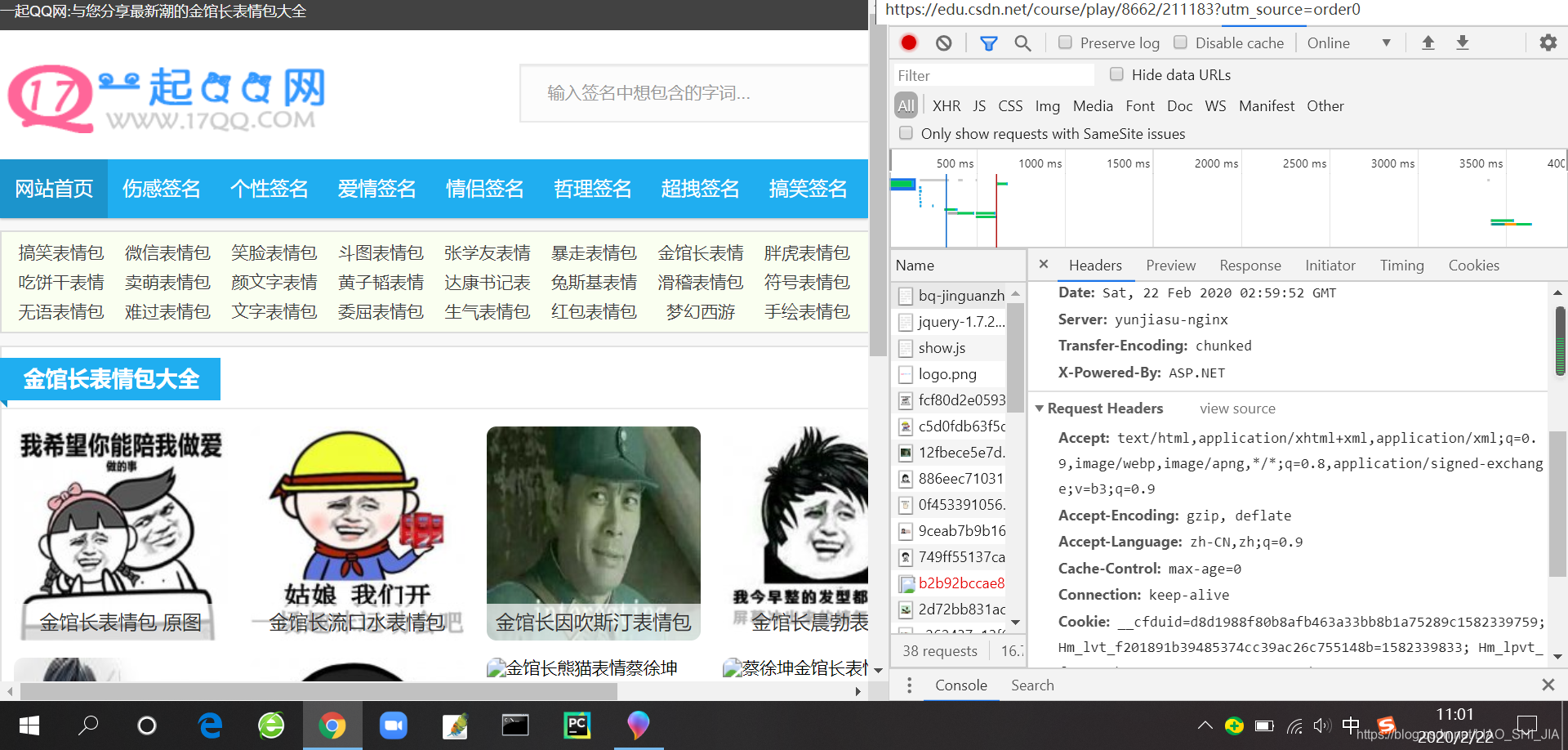
刷新一下,就会有很多想要的信息,比如说headers(请求头),Status Code(状态码)和Cookies等等想要的东西,这是爬虫开发必不可少的。
话不多说了,上代码
# 引用前言说到的库
form bs4 import BeautifulSoup
import requests
- 1
- 2
- 3
找到主网站的网址和要爬的子网址
# 用于补全图片链接
main_url = "http://www.17qq.com"
# 要爬的那个界面Url
url = "http://www.17qq.com/bq-jinguanzhang.html"
- 1
- 2
- 3
- 4
用Network查找用户代理码,这是因人而异的
# 在Network界面获得的Headers请求头
# 每个人是不同的
headers = {"User-Agent": "自己的请求头"}
- 1
- 2
- 3
# 用requests中get方法请求生成一个response对象
response = requests.get(url=url, headers=headers) # 基本用法为requests.get(url= **, headers= **)
# 用BeautifulSoup解析网页生成一个soup对象
soup = BeautifulSoup(response.text, "lxml") # 此处必须要把response对象转换为文本才能解析
# 查找img标签
links = soup.find_all("img")
# 为一些密集恐惧症小朋友设计的简洁名字对象
count = 1 # 此处可以注销掉
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
到了一个很容易出错的地方了,注意看下
# 遍历links对象,查找src标签 并写入一个文件夹中
for link in links:
PNG = link.get("src")
print(PNG)
- 1
- 2
- 3
- 4
此处如果直接输出的话就会出现以下错误
"’
/cache/images/fcf80d2e0593a481.jpg
/cache/images/c5d0fdb63f5d303d.jpg
/cache/images/12fbece5e7d76c2a.jpg
/cache/images/886eec71031e5399.jpg
/cache/images/0f453391056a2891.jpg
"’
发现了什么?这里输出的“链接”只是一堆字符串,我们要怎么改呢?
# 遍历links对象,查找src标签 并写入一个文件夹中
# 将上面代码修改过后的
for link in links:
PNG = main_url + link.get("src")
# 此处用到我们主网站的Url进行字符串拼凑,使其成为完整的链接
print(PNG)
- 1
- 2
- 3
- 4
- 5
- 6
此处要自行现在本文件的路径下自创一个文件夹,名字随意,接在上面的代码下
# 写入文件方法,文件夹名字自己随意
with open("./新建文件夹/{}.png".format(count), "wb") as f_w:
a = requests.get(url=PNG, headers=headers) # 由于进行字符拼凑,要重新get一次
f_w.write(a.content) # 写入文件
count += 1 # 这是为了不让文件重名
- 1
- 2
- 3
- 4
- 5
下面附上完整代码
"'
作者 :LIAO_SHI_JIA
时间:2020.2.22 11:50发布
转载请注明出处!侵权必究!
"'
form bs4 import BeautifulSoup
import requests
# 用于补全图片链接
main_url = "http://www.17qq.com"
# 要爬的那个界面Url
url = "http://www.17qq.com/bq-jinguanzhang.html"
# 在Network界面获得的Headers请求头
# 每个人是不同的
headers = {"User-Agent": "自己的请求头"}
# 用requests中get方法请求生成一个response对象
response = requests.get(url=url, headers=headers) # 基本用法为requests.get(url= **, headers= **)
# 用BeautifulSoup解析网页生成一个soup对象
soup = BeautifulSoup(response.text, "lxml") # 此处必须要把response对象转换为文本才能解析
# 查找img标签,因为很多图片都是以img标签来展示的
links = soup.find_all("img")
# 为一些密集恐惧症小朋友设计的简洁名字对象
count = 1 # 此处可以注销掉
# 遍历links对象,查找src标签,这是链接的意思 并写入一个文件夹中
for link in links:
PNG = main_url + link.get("src")
# 此处用到我们主网站的Url进行字符串拼凑,使其成为完整的链接
print(PNG)
# 写入文件方法,文件夹名字自己随意
with open("./新建文件夹/{}.png".format(count), "wb") as f_w:
a = requests.get(url=PNG, headers=headers) # 由于进行字符拼凑,要重新get一次
f_w.write(a.content) # 写入文件
count += 1 # 这是为了不让文件重名
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
本人是个Python爬虫新手,刚刚才入门,如有BUG请见谅,也请指出来,谢谢支持!
运行结果 PS:由于我编写文章时网不好,有些图片爬不下来,爬虫时要联网
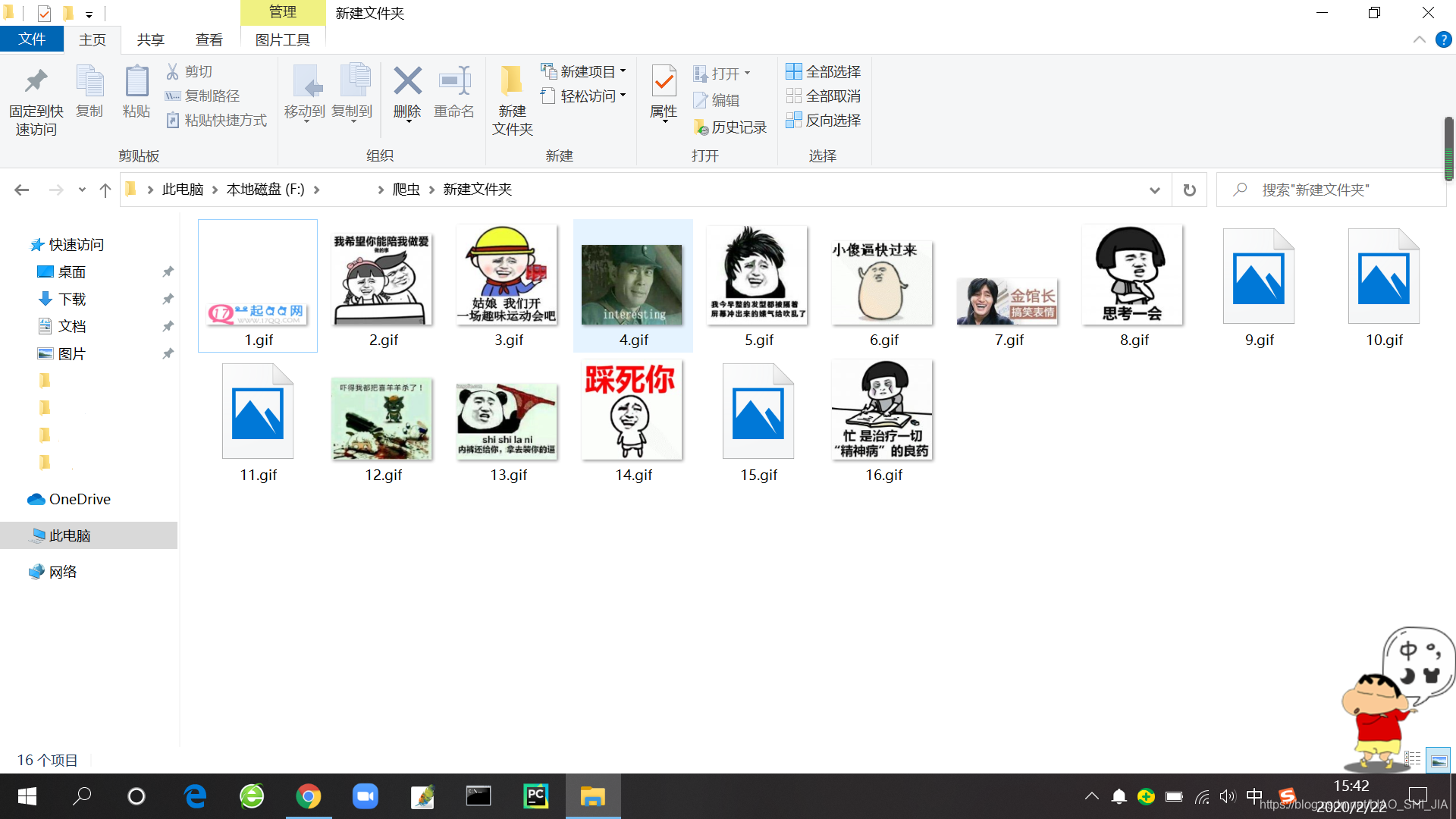
附页:
把Network拉到最下面有一个叫“User-Agent”的东西,那个就是我说的请求头
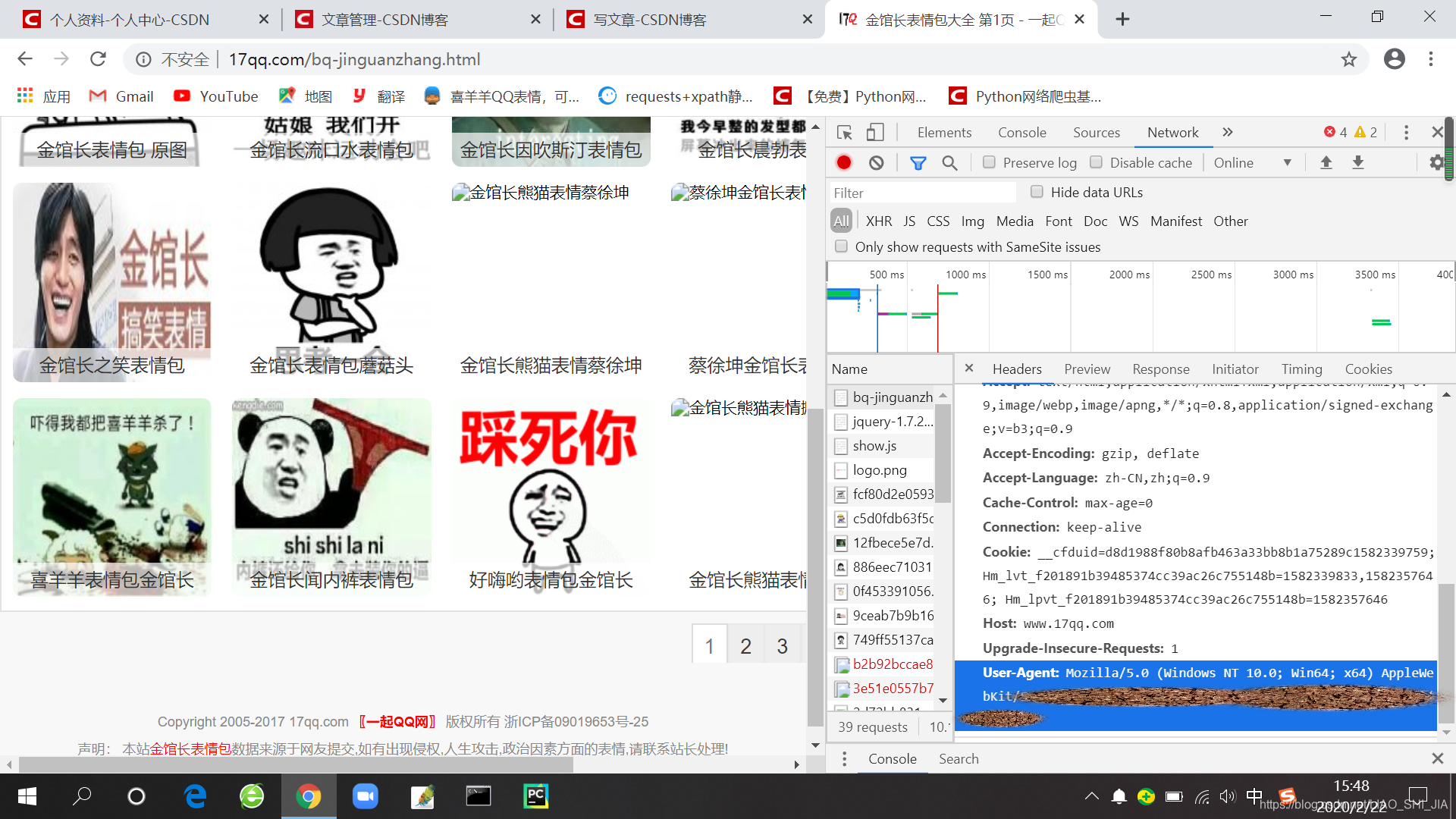
下一次我教大家如何翻页爬取静态网站
谢谢大家支持!有BUG的话请大家指出来,谢谢!
转载请标明出处!侵权必究!

所属网站分类: 技术文章 > 博客
作者:232hdsjdh
链接:https://www.pythonheidong.com/blog/article/232250/cee597ec3d3e0f0f692e/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
25
0
收藏该文
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力
问答(new)
更多>
游戏(new)
更多>