本站消息


虾米音乐歌单制作词云图
发布于2020-02-24 22:30 阅读(774) 评论(0) 点赞(7) 收藏(5)
先附上自己制作的词云图
自己将虾米音乐《我的收藏》里面的歌名与歌手名字制作为词云图。
本来准备用requests爬取页面再分析的,没想到爬取不下来。应该是ajax异步加载(我不懂这个词的意思),firefox浏览器查看XHR,发现了我想要的信息在一个json文件里,然后手动保存内容为json格式。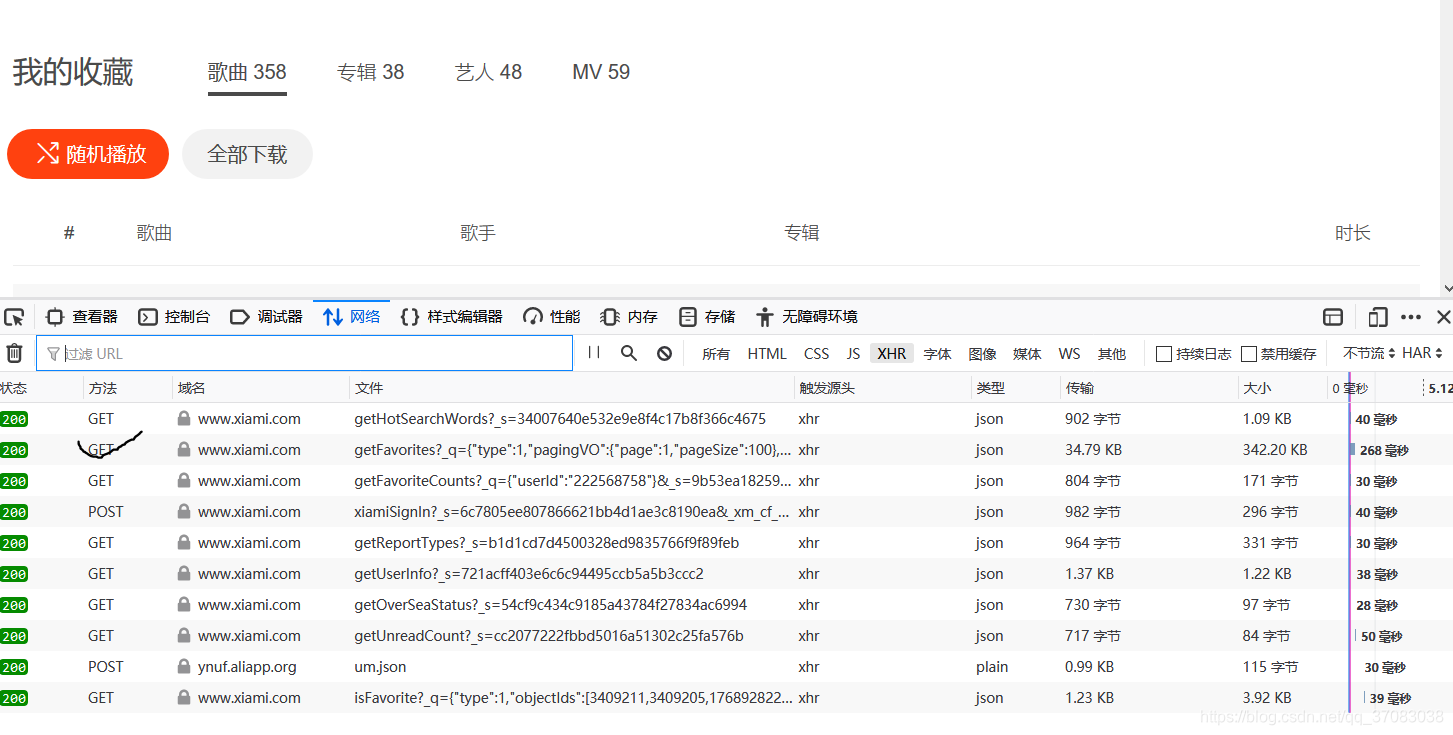
图中画对勾,其响应便是json文件。
firefox分析json比较直观,这是一个字典套字典的格式
自己从json文件中提取出自己要的歌名与歌手名即可。
===================代码==========================
首先便是提取原始json文件中有用的信息。
# -*- coding: utf-8 -*-
"""
Created on Sat Feb 22 17:30:50 2020@author: leslielee
刚刚以为是request库,然后发现没安装,就去安了一个request库,真郁闷。
上个星期在学apdl,突然换过python来,有点难受。
"""
import jsondef get_info(num):
"""
处理json文件 获取自己想要的歌手名 歌手外号 专辑语言
将这些信息保存到all_songs列表中
"""
# 因为我的收藏为4页,所以我保存了4个json文件
# path为存储json文件路径的列表
paths = []
for i in range(1,num+1):
path = 'D:/Documents/python/wordcloud/getFavorites'+str(i)+'.json'
paths.append(path)
# all_songs 为保存4页歌曲信息的列表
all_songs = []
# 依次遍历每个json文件
for path in paths:
# 打开json
f = open(path,encoding='utf-8')
content = json.load(f) #内容是字典格式
# songs即为该页上的所有歌曲信息
songs = content['result']['data']['songs']
# 该页歌曲的个数
songs_num = len(songs)
# songs_为只存储的自己想要的歌曲信息的列表
songs_ = []
# 遍历songs中的所有歌曲
for i in range(songs_num):
# 只提取该歌曲中的歌手名 歌手外号 专辑语言
song = [songs[i]['songName'],songs[i]['albumName'],
songs[i]['artistName'],songs[i]['artistAlias'],songs[i]['albumLanguage']]
songs_.append(song)
all_songs = all_songs+songs_
return all_songs# 从所有json文件中得到自己想要的信息
songs = get_info(4)#保存songs
f = open('D:/Documents/python/wordcloud/songs.json','w')
json.dump(songs,f)
f.close()
提取完自己感兴趣的信息后,制作词云图。
# -*- coding: utf-8 -*-
"""
Created on Sat Feb 22 22:46:35 2020@author: leslielee
人家的博客页面很好看
https://www.cnblogs.com/polly-ling/p/10429624.html
"""
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
import json
import numpy as np
from PIL import Image
import collections # 词频统计库# 读取songs.json
path = 'D:/Documents/python/wordcloud/songs.json'
f = open(path, encoding='utf-8')
songs = json.load(f)# 将songs整合到一个列表中
info = []
for songs in songs:
info = info+songs#词频统计
word_counts = collections.Counter(info) # 对分词做词频统计# 词频展示
mask = np.array(Image.open('D:/Documents/python/wordcloud/madonna.jpg')) # 定义词频背景 该图片自己随意选取
wc = WordCloud(
background_color='white', # 设置背景颜色
mask=mask, # 设置背景图
max_words=250, # 最多显示词数
random_state=42,
max_font_size=150, # 字体最大值
scale=32, #图片清晰度
font_path="C:/Windows/Fonts/STFANGSO.ttf" # 解决显示口字型乱码问题
)# 生成词云
wc.generate_from_frequencies(word_counts)image_colors = ImageColorGenerator(mask, default_color=(255,23,140))
wc.recolor(color_func=image_colors)wc.to_file('D:/Documents/python/wordcloud/songs5.jpg') # 将结果保存为图片

所属网站分类: 技术文章 > 博客
作者:python是我的菜
链接:https://www.pythonheidong.com/blog/article/232496/71ce8bb6a97f35cfaa06/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
7
0
收藏该文
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力
问答(new)
更多>
游戏(new)
更多>