本站消息


从“猫狗大战”入门机器学习之“模型评估与选择”
发布于2020-02-25 09:57 阅读(1706) 评论(0) 点赞(28) 收藏(4)
必备概念:学习器、错误率、精度、训练误差、泛化误差、过拟合、欠拟合、训练集、验证集、测试集
关于猫狗大战:Cats vs. Dogs(猫狗大战)是一道经典赛题,利用给定的包含猫、狗图片的数据集,用算法实现猫和狗的识别(二分类)。
环境:Python3.6,numpy,sklearn,matplotlib
完整代码及相关数据包另传。
部分引用,侵删。
一、评估方法
假设已存在多个学习器,需要对其泛化误差进行评估并选择最优的一个。为此,首先需要对原始数据集进行划分,然后在划分出来的“测试集”上运行,用得到的测试误差作为泛化误差的近似。
数据集划分、评估的三种方法
- 留出法
将总计25k张猫狗图片,随机划分为训练集S、测试集T两部分,其中,各集合里猫与狗图片数量之比为1:1。
D_size = 0.8
cats_1 = random.sample(cats, k=len(cats))
cats_1_train, cats_1_test = cats_1[:round(D_size*len(cats))], cats_1[round(D_size*len(cats)):]
dogs_1 = random.sample(dogs, k=len(dogs))
dogs_1_train, dogs_1_test = dogs_1[:round(D_size*len(dogs))], dogs_1[round(D_size*len(dogs)):]
print(len(cats_1_train),len(cats_1_test))
- 1
- 2
- 3
- 4
- 5
- 6
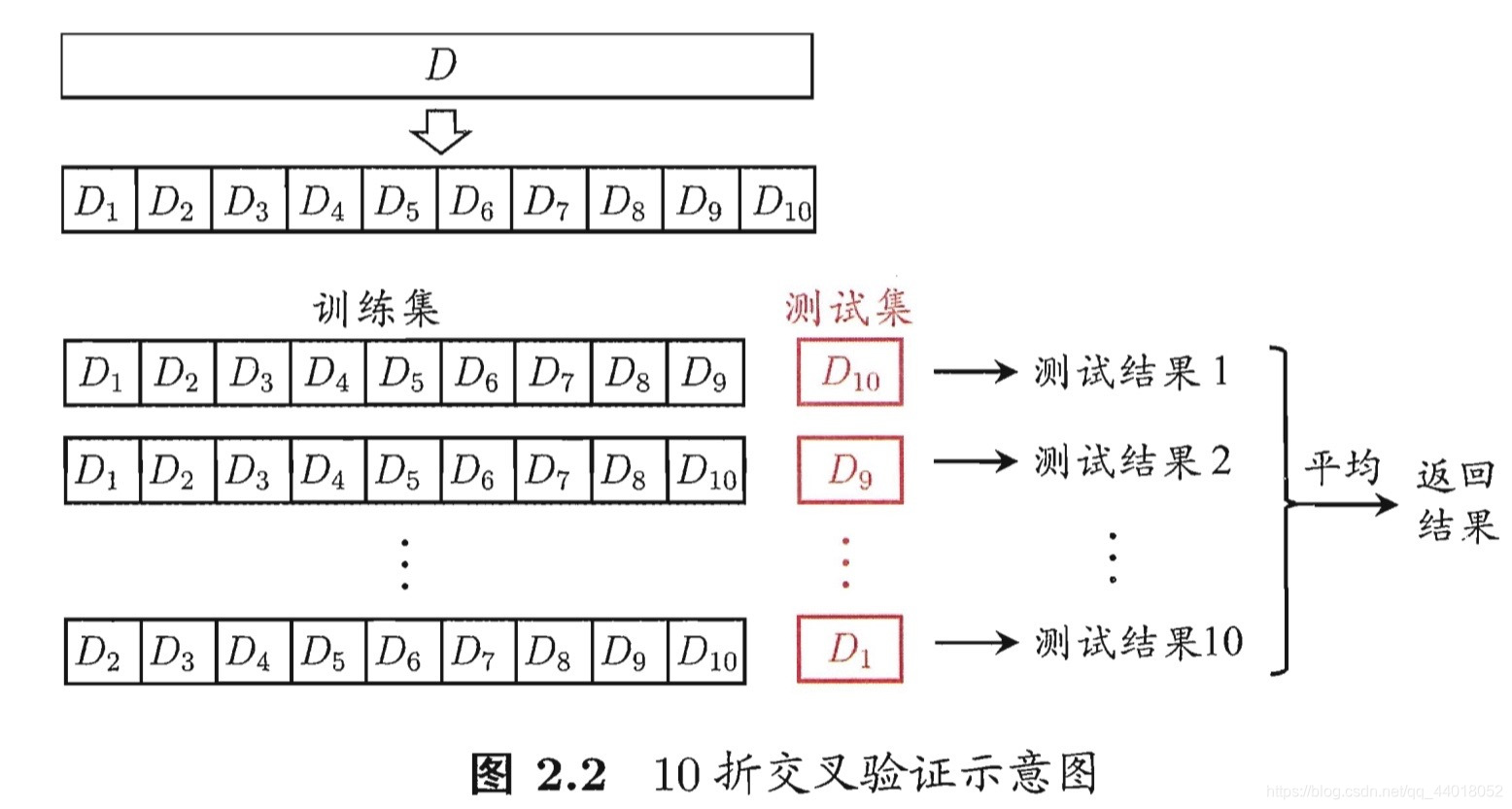
- 交叉验证法
“n次k折”交叉验证:
将数据集D划分为k等份(分层采样),即每份包含1:1的猫狗图片。每次测试,使用其中1份作为测试集,其余看k-1份作为训练集,共k次测试。由于划分时的不确定性,在此基础上划分n次,即测试数量总计n*k。
n=10
k=10
for i in range(n):
cats_2=np.hsplit(np.array(random.sample(cats,k=len(cats))),k)
cats_2_train,cats_2_test=np.array(cats_2[:k-1]),np.array(cats_2[k-1:])
dogs_2=np.hsplit(np.array(random.sample(dogs,k=len(dogs))),k)
dogs_2_train,dogs_2_test=np.array(dogs_2[:k-1]),np.array(dogs_2[k-1:])
#计算测试结果
print(cats_2_train.shape,cats_2_test.shape)
#n次采样求平均
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 自助法
适用于数据集数量较少时。对大小为25k的数据集D中的样本随机复制25k次,得到训练集D’。而D中大概有36.8%的样本不会出现在D’中,这一部分用做测试集。
cats_3_train=random.choices(cats,k=len(cats))
cats_3_test=set(cats)-set(cats_3_train)
print('测试集大小:',len(cats_3_test))
print("%.4f%%" %(len(list(cats_3_test))/len(cats)))
- 1
- 2
- 3
- 4
调参与最终模型
————————参考—————————
训练集:顾名思义指的是用于训练的样本集合,主要用来训练神经网络中的参数。
验证集:从字面意思理解即为用于验证模型性能的样本集合.不同神经网络在训练集上训练结束后,通过验证集来比较判断各个模型的性能.这里的不同模型主要是指对应不同超参数的神经网络,也可以指完全不同结构的神经网络。
测试集:对于训练完成的神经网络,测试集用于客观的评价神经网络的性能。
————————————————
原文链接:https://blog.csdn.net/qq_43741312/article/details/96994243
——————————————————————————————————————————————————————————
二、性能度量
主要介绍分类问题的性能度量。
(一)错误率与精度
使用已有的训练完成得到的模型,去预测一张未知的图片(一个样本),输出为两类别的概率,如:[0.2,0.8]。则表示该图片属于0类(cat)的可能性表示为0.2,属于1类(dog)的可能性为0.8。如果该图片确实是狗的图片,则预测结果符合真实标签(Ground Truth)。如果该图片不是狗的图片,则分类错误。通过测试大量样本从而得到错误率和精度(Accuracy)。
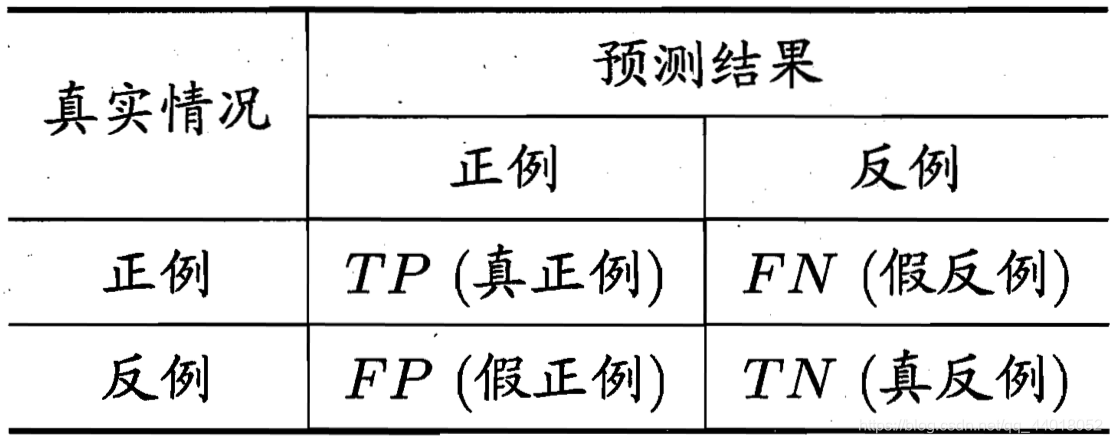
(二)查准率、查全率、F1

现在,我们有两个训练好的“猫狗二分类”神经网络模型,文件是HDF5类型。通过加载模型并对选取的一批图片(135张)进行预测,得到了包含预测结果的numpy数组,并保存在磁盘上。数组形状(135,3),每行表示一个样本的预测结果,共135行,第一列表示真实标签(0代表cat,1代表dog),第二列表示预测标签,第三列表示预测概率值*1000,如下:
[[ 0 0 0]
[ 0 1 999]
[ 0 1 1000]
[ 1 1 999]
[ 1 0 100]
[ 1 1 999]
[ 1 0 23]
[ 0 1 666]
[ 0 1 1000]
[ 0 0 0]
[ 1 1 928]
[ 1 1 864]
.....................
[ 1 1 999]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
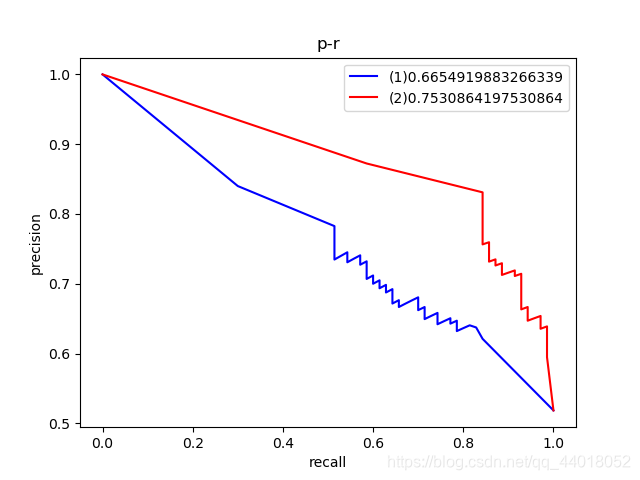
使用得到的两个numpy数组,可以借助sklearn绘制出dog作为正样本的P-R曲线、ROC曲线。
_1=np.load(dirname(__file__)+'/resault.npy')
_2=np.load(dirname(__file__)+'resault2.npy')
_true=_1[:,0]
_pre=_1[:,1]
_score=_1[:,2]/1000
_true2=_2[:,0]
_pre2=_2[:,1]
_score2=_2[:,2]/1000
P,R,thresholds=precision_recall_curve(np.array(_true),np.array(_score))
P2,R2,thresholds2=precision_recall_curve(np.array(_true2),np.array(_score2))
plt.plot(R,P,'blue')
plt.plot(R2,P2,'red')
plt.xlabel('recall')
plt.ylabel('precision')
plt.title('p-r')
plt.legend(['(1)'+str(f1_score(_true,_pre,average='macro')),'(2)'+str(f1_score(_true2,_pre2,average='macro'))])
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
F1度量的一般形式是:

在上图图例中,可以看到(1)号结果的F1度量小于(2)号结果,并且红色曲线完全包住蓝色曲线,都说明第二个模型更优。事实也是如此,第一个模型基于2000张图片训练,第二个模型则是基于7000张图片训练。
(三)ROC与AUC
fpr, tpr, thresholds = roc_curve(_true,_score)
fpr2, tpr2, thresholds = roc_curve(_true2,_score2)
plt.plot(fpr,tpr,'blue')
plt.plot(fpr2,tpr2,'red')
plt.xlabel('fpr')
plt.ylabel('tpr')
plt.legend(['(1)'+str(auc(fpr,tpr)),'(2)'+str(auc(fpr2,tpr2))])
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

ROC曲线即TPR-FPR曲线,AUC是用ROC曲线下的积分(面积)表示的度量模型优劣的指标。
和P-R曲线的绘制过程类似,ROC曲线也是首先对预测结果的数组按照预测值从高到低进行排序,然后在不同的位置截取(即选择一个分类阈值),计算当前阈值对应的TPR、FRP,即得到一系列点并绘图。
理想情况下,TPR=1,FPR=0。曲线越向左上方弯曲,表示FPR相同时,分类器查全率(真例率TPR)越好,意味着预测更加准确。

所属网站分类: 技术文章 > 博客
作者:外星人入侵
链接:https://www.pythonheidong.com/blog/article/233117/685db5cd8a037d00e409/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
28
0
收藏该文
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力
站长公众号(new)
更多>
pdf(new)
更多>
问答(new)
更多>
游戏(new)
更多>