本站消息


【python爬虫 系列】5.python解析库
发布于2020-02-26 10:40 阅读(1280) 评论(0) 点赞(18) 收藏(4)
第五节:python解析库

5.1文本清洗
1)编码解码:
编码是信息从一种形式或格式转换为另一种形式的过程,解码则是编码的逆过程
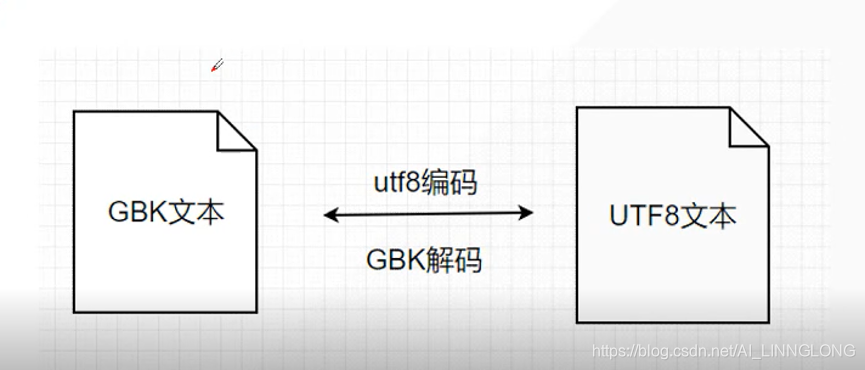
乱码的诞生就是编解码不一样造成的,只有编码和解码的方式一样才会正常显示
编码:Encode
解码:Decode
- 1
- 2
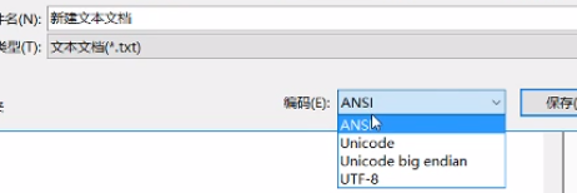
比如你新建一个文本文档,就可以在下方看到编码,如图
2)常见格式:
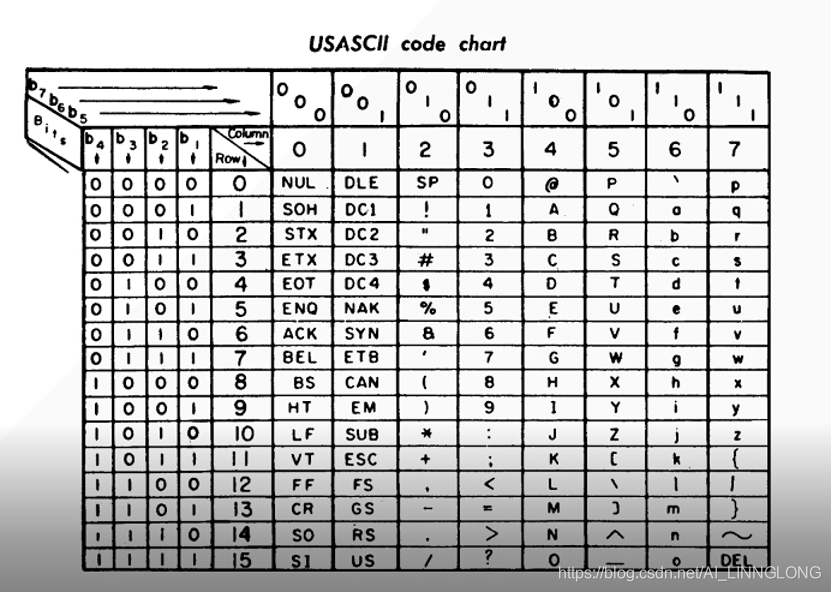
ASCII(补码形式)
计算机内部,所有信息最后都是一个二.进制
一个字节byte是8位二进制,二进制有0和1两种状态,所以一个字节有256种状态,每个状态对应一个符号。 asci-共256个符号。
上个世纪,美国制定了这套编码,英语字符和二进制一一对应,沿用到现在。
比如空格是32,大写字母A是65。 字符一共128个, 这些字符只占用一个字节的后边7位,最前边统一为0
Unicode(python2)(被称为上帝的馈赠):
100多万个符号,把世界上所有的符号融入其中,每个符号都有独一无二 的编码。
比如U+0639代表阿拉伯字母Ain,U+4E25代表汉字严。
不过存在的问题是,unicode转化为二进制需要很多空间,比如严的16进制4E25转化为二进制有15位(100111000100101) ,至少两个字节。其他更大的符号可能有5一-6个字节。

英文字母只需要二进制的七位,所以在unicode中,一-般字符三到四个字节,会有空间浪费,文本文件因此大出好几倍,是无法接受的。
UTF-8(Unicod中的,轻量级Unicod)
目前最常见的unicode实现方式,还有uf- 16,utf-32等等。
对于单字节的符号,字节第一位为0,后边7位是unicode码。
对于英文字母,utf8和unicode是 一样的。
对于n字节的符号,第一个字节前边的n位都设为1,n+1为设 为0,后边字节的前两位一律为10。剩下的没有提及的为unicode。
如果字节第一位为0,就是单独一个字符;
如果第一位为1,则有多少个连续的1,就是几个字节
严的unicode是4E25 (100111000100101)处于0000800 000FFFF范围内, 所以转化为utf8是111xxx1x0xxxxxxxxx,然后,从最后一个开始,依次填充unicode,得到十六进制E4B8A5。
3)python编码解码
编码解码一般是一一对应的,编解码格式应该一致,
不一致可能导致编码问题乱码,或者干脆解析不了:
例如:
text = 'hello python 汉字'
ens = text.encode("utf-8") #编码一般是先转化,类似于加密
print(ens)
des = ens.decode("utf-8") #解码就是解密
print(des)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出:
b'hello python \xe6\xb1\x89\xe5\xad\x97' #16进制
hello python 汉字
- 1
- 2
然而我们加上:
ddns = ens.decode("ascii")
print(ddns)
- 1
- 2
就会报错:
UnicodeDecodeError:
'ascii' codec can't decode byte 0xe6 in position 13
- 1
- 2
这就是因为我们使用了错误的解码格式
常用的编码方式应用:
在Python中,编码解码常见于
1.写入文本文件
2.获取网页页面
#编码方式应用1 获取网页页面时
import requests
html = requests.get("http://baidu.com")
html.encoding="utf-8"
#html.encoding="gbk" #中文
print(html.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
#编码方式应用2 写入文本文件时
text = "text"
with open ("file.txt",encoding="utf-8") as f:
f.write(text)
- 1
- 2
- 3
- 4
你可以在网页的源代码处查看网页相应的编码格式以达到确定采用哪种编码方式的目的:
5.2 Python操作字符串
1).根据任意多的分隔符操作字符串
re.split()
可以设定分隔符,或者采用 re.rsplit()右分割(针对于长文本处理,取出后边的几个),当然也可设定分割几个
扩展知识: 自然语言处理: 正向分割,反向分割,双向分割
如:
text = "https:/baidu.com/python"
res1 = text.split("/")
res2 = text.rsplit("/",maxsplit=2) #从右边分割,分割成几个
print(res1)
print(res2)
输出:
['https:', 'baidu.com', 'python']
['https:', 'baidu.com', 'python']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2).在字符串开头结尾做文本匹配
本方法适用于存储或者清洗数据的时候找到我们所需要的数据,
注意大小写也是区分的。
Str.startswith() 匹配开头
Str.endswith() 匹配结尾
如:
text1 = "python入门"
text2 = "go 入门"
if text1.startswith("python"):
print(text1)
else:
print("no python book")
if text2.startswith("python"):
print(text1)
else:
print("no python book")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
输出:
python入门
no python book
- 1
- 2
3).字符串连接合并问题
Str.join() 把容器里的东西按你自定义方式拼接
值得注意的是它的写法要s = (",".join(res)),res是列表等
如:(我们利用如下两种方式作为对比)
res=["python","go","java","c"]
- 1
#方法1
tmp = ""
for i in res:
tmp+=i
print(tmp)
#方法二
print(",".join(res))
输出:
pythongojavac
python,go,java,c
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
我们可以看到,两种都可以实现拼接,但显然第二种更加好,
还可以自定义你的拼接设定
4).字符串替换
Str.replace() 字符串替换
Str.translate() ord映射替换
- 1
- 2
我们日常写的爬虫基本都是小的爬虫而不是特别大的工程,所以我们往往习惯使用replace方法,而在大工程里,往往代码行要成千上万,那么利用replace方法是极其复杂的,我们需要一个一个的更改才行,而translate方法就不需要,这也是这两种方法的区别,使用方法如下:
#替换方法translate
ins = "abcd" #替换前
outs = "degf" #替换后
str_trantab = str.maketrans(ins,outs) #前面写替换前,后面写替换后
test_str = "abcd hijk lmn"
print(test_str.translate(str_trantab))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结果:degf hijk lmn
5).去除不需要的字符
Str.lstrip()
Str.rstrip()
Str.strip(str)
- 1
- 2
- 3
string.strip([chars])
方法删除字符串开头和结尾指定的字符或字符序列(即不能删中间字符)。
string.lstrip([chars])
方法删除字符串开头指定的字符或字符序列(即不能删中间字符)。(l - left - strip 左侧,即开头)
string.rstrip([chars])
方法删除字符串结尾指定的字符或字符序列(即不能删中间字符)。(r - right - strip 右侧,即结尾)
上面三个函数返回移除字符串string头尾指定的字符生成的新字符串,string本身不会发生改变。
chars 指的是移除字符串头尾指定的字符序列,
若其为空,则默认删除空白符:\n、\r、\t、’ ',即:换行、回车、制表符、空格
若其不为空时,找出字符串string中头尾部分含有的与chars中所包含的字符相同的字符,然后将这些字符去掉
6).格式化替换
%d %s传统替换格式
Format()替换
f“”替换
res = "www.baidu.com/f"
#1.c语言传承传统替换方法
print("www.baidu.com/f=%s--%d"%('python',1))
#2 format python2-3
print("www.baidu.com/f={}".format("python"))
#3. f 3.6python新加
p = 'python'
print(f'www.baidu.com/f={p}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出:
www.baidu.com/f=python--1
www.baidu.com/f=python
www.baidu.com/f=python
- 1
- 2
- 3
三种方法你都可以使用,但最好在一个项目里选择一个
5.3正则表达式
什么是正则表达式?
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个"规则字符串", 这个规则字符串"用来表达对字符串的一种过滤逻辑。
1.re
Python自带库,使用方法 import re即可导入
修饰符:
re.I* 使匹配对大小写不敏感
re.L 做本地化识别( locale-aware )匹配
re.M* 多行匹配,影响^和$
re.S* 使匹配包括换行在内的所有字符(html匹配常用)
re.U 根据Unicode字符集解析字符。这个标志影响lw, W, lb, IB.re.X
re.X 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。
同时使用多个修饰符方法,利用 | 如:re.I|re.s
Pattern ,我们编写的正则表达式,
String ,我们要匹配的字符串
Flag,我们的修饰符
1)re.match(pattern,string,flag) 从文本开头开始匹配
匹配string 开头,成功返回Match object, 失败返回None,只匹配一个。
用group()提取结果
2).search
在string中进行搜索,成功返回Match object, 失败返回None, 只匹配一个。
用group()提取结果
例:
**
import re
text = '<a href="www.baidu.com">百度一下' \
'<a href="www.baidu.com">跳转</a></a>'
print(text)
res = re.match('href=".*?"',text,re.I|re.S) #失败
print(res)
ress = re.match('<a href=".*?"',text,re.I|re.S) #对 因为match是从头开始匹配的
print(ress)
resss = re.search('href=".*?"',text,re.I|re.S) #对 在string中进行搜索
print(resss)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
**
结果:
<a href="www.baidu.com">百度一下<a href="www.baidu.com">跳转</a></a>
None
<re.Match object; span=(0, 23), match='<a href="www.baidu.com"'>
<re.Match object; span=(3, 23), match='href="www.baidu.com"'>
- 1
- 2
- 3
- 4
通过结果可以看出
- 1
Match和search得到的是正则表达式匹配对象
提取结果需要使用特定函数
Group () 匹配的正则字符串
Groups() 返回包含字符串元组
(为什么用元祖?因为元祖展示一个一个迭代,占用内存小)
如:
resss = re.search('href="(.*?)"',text,re.I|re.S) #对 在string中进行搜索
print(resss)
print(resss.group())
print(resss.groups())
结果:
<re.Match object; span=(3, 23), match='href="www.baidu.com"'>
href=www.baidu.com
('www.baidu.com',) #groups
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3).findall
在string中查找所有 匹配成功的组, 即用括号括起来的部分。返回list对象,每个list item是由每个匹配的所有组组成的list。
4).finditer
在string中查找所有 匹配成功的字符串, 返回iterator,每个item是一个Match object。
5).re,compile()
提前建立一个匹配模式,可复用
如:
tmp = re.compile('href=".*?"',re.I|re.S)
print(tmp.search(text).group())
输出:
href=www.baidu.com
那么你也可以利用findall()匹配多个:
- 1
- 2
- 3
- 4
- 5
- 6
例:
import re
text = '<a href="www.baidu.com">百度一下' \
'<a href="www.baidu1.com">跳转</a></a>'
tmp = re.compile('href=".*?"',re.I|re.S) #fuyong
print(tmp.findall(text))
输出:['href="www.baidu.com"', 'href="www.baidu1.com"']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
6).re.sub()使用正则替换字符串
我们可以用Python自带的replace或者translate解决,一般不常用
例如:这里就是讲href替换为url
import re
text = '<a href="www.baidu.com">百度一下' \
'<a href="www.baidu1.com">跳转</a></a>'
res = re.sub("href",'url',text,re.I|re.S)
print(res)
- 1
- 2
- 3
- 4
- 5
- 6
输出:
<a url="www.baidu.com">百度一下<a url="www.baidu1.com">跳转</a></a>
- 1
注:正则表达式还有很多,感兴趣的读者可以深入了解。
面试常考:
用正则表达式匹配邮件地址,ip地址,手机号码等
5.4Python操作xpath
1)安装模块方法:
Pip install lxml
- 1
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
2)XPath常用规则:
表达式 描述
nodename 选取此节点的所有子节点。
/ 从根节点选取。
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
. 选取当前节点。
… 选取当前节点的父节点。
@ 选取属性。
.CONTAINS() //DIV[CONTAINS(@ID,IN’)]
.TEXT() //a[text()=‘baidu’]
.STARTS-WITH() //div[starts-with(@id,‘in’)]
.NOT() //input[not(contains(@clas,a))]
示例如下:
对于多属性的标签,可以使用以上两种方法提取里边文字,
当然提取标签里的属性,比如href(result)
from lxml import etree
text = """
<li class ="li ze-vin">
<a href = "link.html"> 我需要的文字 </a>
</li>"""
html = etree.HTML(text)
print(html)
result = html.xpath("//li/a/text()")
result2 = html.xpath("//li[@class='li ze-vin']/a/text()")
result3 = html.xpath("//li[contains(@class,'li ze-')]/a/text()")
result4 = html.xpath("//li[contains(@class,'li')]/a/@href")
print(result)
print(result2)
print(result3)
print(result4)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
结果:
[' 我需要的文字 ']
[' 我需要的文字 ']
[' 我需要的文字 ']
['link.html']
- 1
- 2
- 3
- 4
3)xpath实战
#xpath 解析百度搜索页面
#
import requests
from lxml import etree
def get_html():
url = "http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&ch=1&tn=25017023_6_dg&wd=%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4&oq=Syntax%2526gt%253Brror%253A%2520invalid%2520syntax&rsv_pq=f02201a00002574e&rsv_t=902a2cbzt5E3YhY6KEiSSShOZRUS20hdRxLG%2F1ua661Acg21E%2BfZp8ENRLHoUGKs9BmZSg&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=2&rsv_sug2=0&inputT=2168&rsv_sug4=3420"
html = requests.get(url)
if html.status_code == 200:
return get_content(html)
else:
print("get html error")
def get_content(html):
#html.encoding="utf-8"
#print(html.text)
soup = etree.HTML(html.text)
elements = soup.xpath('//div[@id="content_left"]//div[starts-with(@class,"result")]')
for e in elements:
title = e.xpath('h3/a/text()')
print("".join(title))
try:
link = e.xpath('h3/a/@href')[0]
print(link)
except:
print("no link")
else:
print("error")
if __name__ == '__main__':
get_html()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
#xpath 解析博客"https://www.cnblogs.com/Amy-is-a-fish-yeah/p/11788464.html"
#
import requests
from lxml import etree
def get_html():
url = "https://www.cnblogs.com/Amy-is-a-fish-yeah/p/11788464.html"
html = requests.get(url)
if html.status_code == 200:
return get_content(html)
else:
print("get html error")
def get_content(html):
html.encoding="utf-8"
#print(html.text)
soup = etree.HTML(html.text)
elements = soup.xpath('//div[@class="post"]//div[@id="cnblogs_post_body"]/p/text()')
new = ("".join(elements))
print(new)
if __name__ == '__main__':
get_html()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

所属网站分类: 技术文章 > 博客
作者:从新来过
链接:https://www.pythonheidong.com/blog/article/233821/992581bea1ee6a725ad5/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
18
0
收藏该文
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力
问答(new)
更多>
游戏(new)
更多>