本站消息


爬虫练习(一)-初体验-淘宝商品名称价格爬取
发布于2020-02-26 12:00 阅读(1407) 评论(0) 点赞(23) 收藏(2)
爬虫练习(一)-初体验-淘宝商品名称价格爬取
思路:
1、首先需要一个接口
2、希望爬取多页,要了解翻页的机制

第二页

第三页
由此可知,淘宝默认44为一页
爬虫思路:
要定义四个函数:
1、用来抓取网页的内容
import re
import requests as rs
import os
#1、抓取网页
def GetContent(url):
try:
head = {
'accept-encoding': 'gzip, deflate, sdch, br',
'accept-language': 'zh-CN,zh;q=0.8',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4620.400 QQBrowser/9.7.13014.400',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'cache-control': 'max-age=0',
'authority': 's.taobao.com',
'cookie': 'miid=2068212171251276260; cna=YvxMEvl+JhUCAXPnMSUJhymi; hng=CN%7Czh-CN%7CCNY%7C156; thw=cn; _m_h5_tk=b42f55e88611d73a88e78a1520bc4ced_1582442005441; _m_h5_tk_enc=e80ad35c3150848e5ad0173d474b40fe; enc=yZL87SLXumyKkPbZsmenpov9aRW8WoTj3UlVbKvYq%2BALmLFJgP48275Zva8%2FoG%2BbkM44qSCyOZCnPvlV6DbsFg%3D%3D; v=0; _samesite_flag_=true; _tb_token_=565deb30175ee; sgcookie=D75g13IFkErNuFojbANjg; unb=2602104768; uc3=lg2=Vq8l%2BKCLz3%2F65A%3D%3D&vt3=F8dBxd3wqiM01J46ZF8%3D&id2=UU6hRiHl6tC%2Frg%3D%3D&nk2=3v4ljD7ra5bC6d5BT9K9pQ%3D%3D; csg=4aff3b2b; lgc=%5Cu5EFA%5Cu8BAE%5Cu600E%5Cu4E48%5Cu53D6%5Cu540D%5Cu5B57%5Cu554A; t=e7ad534a64c25f8816fa93fe6f8c4863; cookie17=UU6hRiHl6tC%2Frg%3D%3D; dnk=%5Cu5EFA%5Cu8BAE%5Cu600E%5Cu4E48%5Cu53D6%5Cu540D%5Cu5B57%5Cu554A; skt=8bf9b2dcdb64dcfe; cookie2=10124cf623f791d2e29696d9343f83bc; existShop=MTU4MjYwNjU2MQ%3D%3D; uc4=nk4=0%403LcI4%2BzBT9saZmTdSg9oeiSOvQ9%2BQx8jKv0E&id4=0%40U2xsBh9eUxOA1C2mX6rQvlbLzc79; tracknick=%5Cu5EFA%5Cu8BAE%5Cu600E%5Cu4E48%5Cu53D6%5Cu540D%5Cu5B57%5Cu554A; mt=ci=55_1; _cc_=VFC%2FuZ9ajQ%3D%3D; tg=0; _l_g_=Ug%3D%3D; sg=%E5%95%8A87; _nk_=%5Cu5EFA%5Cu8BAE%5Cu600E%5Cu4E48%5Cu53D6%5Cu540D%5Cu5B57%5Cu554A; cookie1=V3oagUsOJ6T3Qw8UrlL%2BWQ9cXELGg5thneeqVyyIews%3D; tfstk=ceJFB7mxevHEhxGwit6PPus08x-dZ2tHqRSftIXS9WK7yGfhMjf-wogjViIuw; alitrackid=www.taobao.com; lastalitrackid=www.taobao.com; uc1=cookie16=URm48syIJ1yk0MX2J7mAAEhTuw%3D%3D&cookie21=U%2BGCWk%2F7ow0zmglPa33heg%3D%3D&cookie15=URm48syIIVrSKA%3D%3D&existShop=false&pas=0&cookie14=UoTUOLUnH0Ynwg%3D%3D&tag=8&lng=zh_CN; JSESSIONID=E8108D4668AF12DF30F1AEACA136D5CB; isg=BKSkEyKipkOMENJfRiZFL-4fYKKWPcingBvtLL7FMG8yaUQz5k2YN9rLKcHxqgD_; l=dB_LyZwgQOaEdPZCBOCanurza77OSLAYYuPzaNbMi_5Bq6Ts7N_Oo8K29F96VjS1ix8B4zcBghp9-etkZklM5f--g3fr4LQjJFrs8wHZexf..',
'referer': 'https://www.taobao.com/',
}
r = rs.get(url,headers = head)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('爬取失败')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2、用来存储目标信息
def Fillinfo(html,list):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
scl = re.findall(r'\"view_sales\"\:\"\d.*?\"',html)
nam= re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
real_price = eval(plt[i].split(':')[1])
real_sale = eval(scl[i].split(':')[1])
real_name = eval(nam[i].split(':')[1])
list.append([real_name,real_price,real_sale])
except:
print('存储失败')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3、用来打印和存到文件夹内
def PrintGOD(list,file_name):
os.chdir('E:\\Text\\')
count=1
count1=1
with open(file_name,'w') as f:
tpl = '{:4}\t{:20}\t{:10}\t{:4}'
tpl1 = '{:4}\t{:16}\t{:10}\t{:4}\n'
f.writelines(tpl1.format('序号','商品名','价格','销量'))
for each_goods in list:
f.writelines(tpl1.format(count,each_goods[0],each_goods[1],each_goods[2],chr(12288)))
count+=1
print(tpl.format('序号','商品名','价格','销量',chr(12288)))
for each_good in list:
print(tpl.format(count1,each_good[0],each_good[1],each_good[2],chr(12288)))
count1+=1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4、用来运行上述三个函数
def main():
start_url = 'https://s.taobao.com/search?q='
goods = 'TimeX'
depth = 3
list = []
file_name = 'TIMEX.txt'
for i in range(depth):
url = start_url+goods+'&s='+str(i*44)
html =GetContent(url)
Fillinfo(html,list)
PrintGOD(list,file_name)
main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
问题:
1、在获取内容的函数内,若不加上headers,实际上爬取的页面是淘宝的登陆页面。
解决办法:
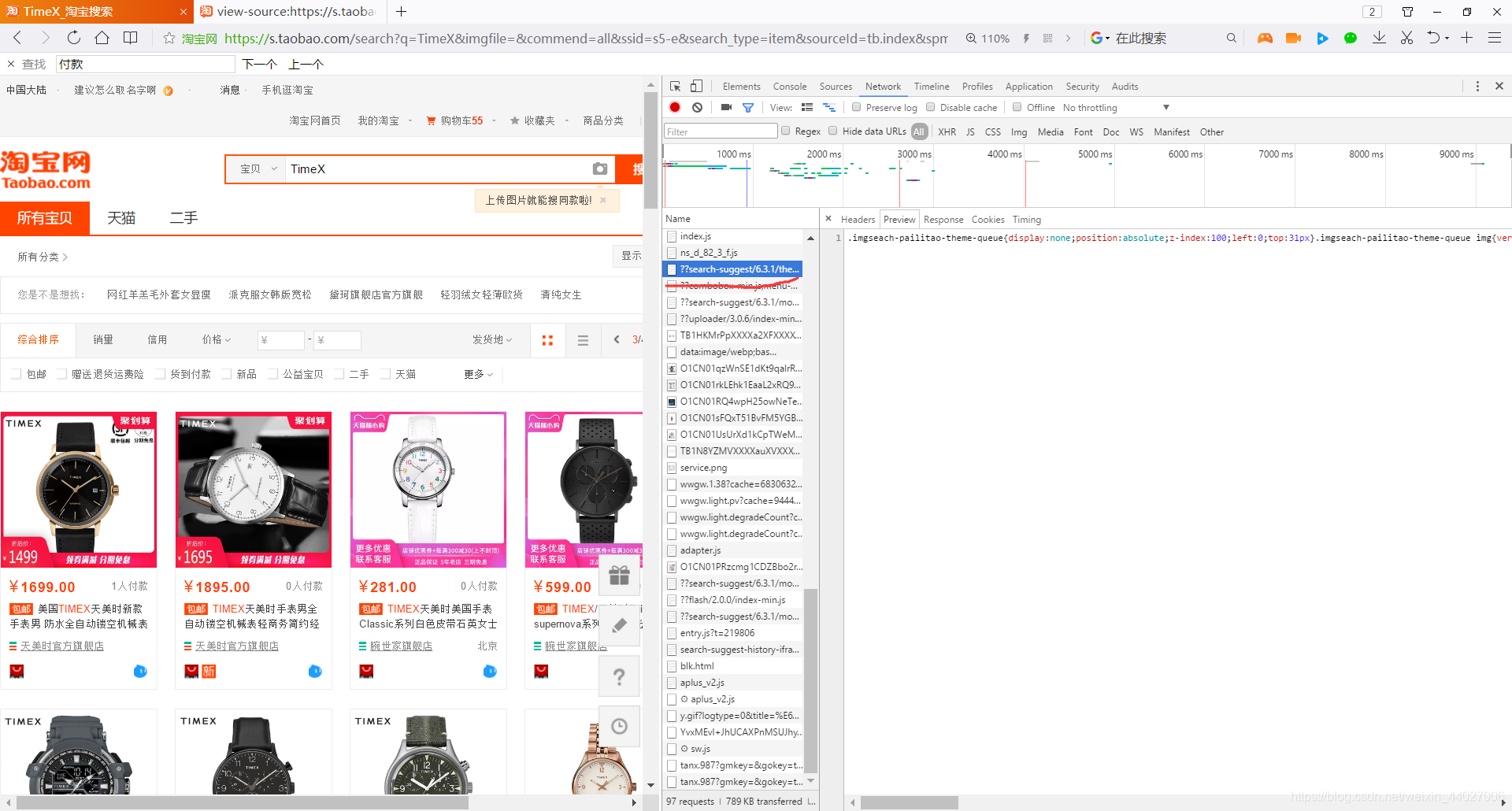
搜索页面按F12>>点击Network>>找到最上面的search(如下图)>>右键Copy as cURL(bash)
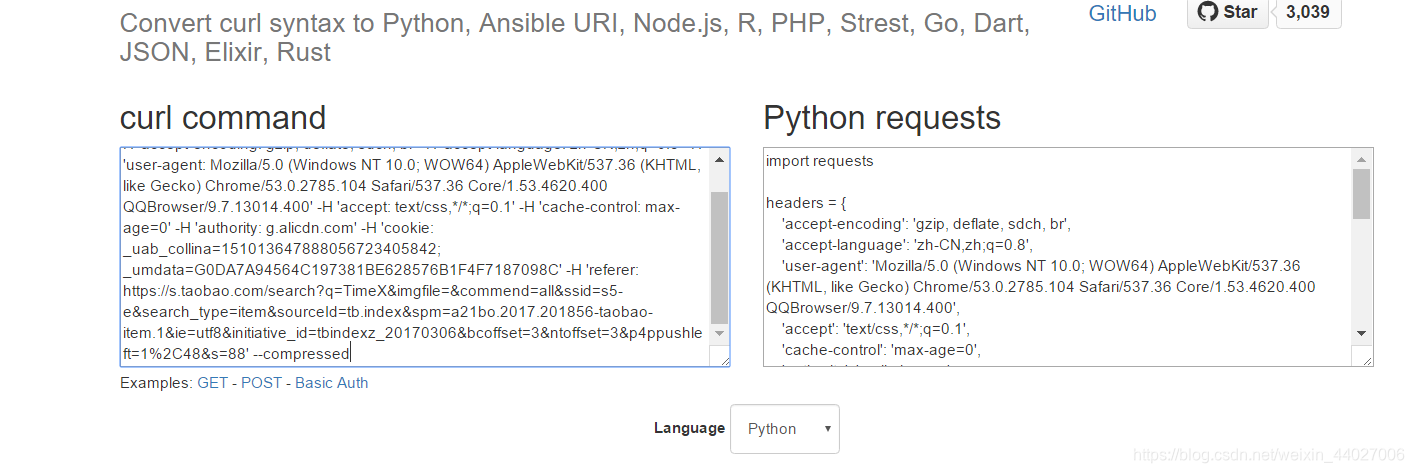
打开https://curl.trillworks.com/>>把复制的内容粘贴在左框>>复制右框的headers内容(到}为止)>>回答代码>>在requests.get(url,headers = headers)即可
2、正则表达式不太熟练
注意:
1、注意要在冒号前面加上r,注意 . :等符号,要转义的话要加上
2、正确书写正则表达式
3、打印处count应该设为两个不同的
4、注意打印时要用中文空格:chr(12288)

所属网站分类: 技术文章 > 博客
作者:爬虫soeary
链接:https://www.pythonheidong.com/blog/article/234110/2d459642f8995a9f9fd9/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
23
0
收藏该文
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力
站长公众号(new)
更多>
pdf(new)
更多>
问答(new)
更多>
游戏(new)
更多>