

Python爬虫
发布于2020-03-20 10:47 阅读(5451) 评论(0) 点赞(5) 收藏(4)
Python爬虫
1、背景
互联网是一个巨大的资源库,只要方法适当,就可以找到你所需的数据。少量的数据可以通过人工去找,但是对于大量的数据,而且数据获取之后还需要进行分析,那么靠人工就无法完成任务,因此需要通过计算机程序来自动化完成这些工作。有一家公司就是用爬虫发家的,并且很多公司的数据都愿意给这家公司爬取,那就是百度啦。
2、技术介绍
网络爬虫(又称为网页蜘蛛,网络机器人),是按照一定的规则,自动地爬取互联网数据的计算机程序。编写网络爬虫主要涉及的技术有网络通信技术、多线程并发技术、数据交换技术、HTML等Web前端技术、数据分析技术和数据存储技术等。因为Python拥有很多丰富的第三方库可以供我们调用,python学习门槛低,(主要原因☺)Python的设计者的龟叔头发是最多的,所以人生苦短,我用Python。
传闻Python是龟叔在圣诞节期间闲太无聊了,就写出了python的第一个版本。我是Python2.7版本发布的时候入坑的,Python3.0发布并且宣布不兼容python2,当时心中。。。,在此献上龟叔的照片

3、实战
接下来开始展现Python爬虫的魅力!!
下图是网易云某音乐的精彩评论

如何将这些评论资源获取到本地计算机里呢?
方法一:手动复制粘贴到本地(要是上万条评论,你一条一条复制粘贴,想想就心累)
方法二:使用爬虫让程序自己爬取数据(看上去挺不错的)
直接上代码,本代码是爬取网易云音乐热评
import requests
import json
def get_hot_comments(res):
comments_json = json.loads(res.text)
hot_comments = comments_json['hotComments']
with open('hot_comments.txt','w',encoding='utf-8') as file:
for each in hot_comments:
file.write(each['user']['nickname'] + ':\n\n')
file.write(each['content'] + '\n')
file.write("-----------------------------------\n")
def get_comments(url):
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'referer':'https://music.163.com'
}
params = "knm/5W3MRpj9Omxgt9My5iSwaQv8AdLtcaNDu+xfUX1r+Xr3fjLLD3FDjpstLHNhkqTyk1hdNtiIMIv5n1OX3mNh6KAYXvY4Kuy72LBq4XhAoyiR3vQgW6xLhbVT2QshJL2zJvEpaZOQ3WL8IBkmNViXesAnaQPabpzx9LwNyyUVAzhm1iHMpA20rAZD5LEa"
encSecKey = "b28bf9e76d929345700f37dd14a0a4739b7c8db5daff3de25297ce441691c53495d686ec22cd9419a722d73521a1e9fbbb9e270a52e3187131b0ee1775f39379c579ea9aee4d1c24edc56add062b7bfffd4987829018f2d4106349bb7b5e0f45edcd589cb2015ce9c431b639004e87f2a8ecbf4736c689f444763219bde1c306"
data = {
"params":params,
"encSecKey":encSecKey
}
name_id = url.split('=')[1]
target_url = "https://music.163.com/weapi/v1/resource/comments/R_SO_4_{}?csrf_token=".format(name_id)
res = requests.post(target_url,headers=headers,data=data)
return res
def main():
url = input("请输入链接地址:")
res = get_comments(url)
get_hot_comments(res)
if __name__ == "__main__":
main()
让我们来运行一遍上面的代码:

先输入你想要获取那首歌的热评的网站地址

回车,你就会发现本地多了一个hot_comments.txt文件
双击打开

这些正是你需要的评论数据,一秒钟不到就都到你的电脑里了。是不是感觉很神奇,是不是感觉Python无所不能呢。
思路
评论的数据会在哪里呢?
大家第一想到的是会不会在html文件里,让我们右键查看网页源代码,Ctrl+F查找

发现不在这里,那么会在哪里呢?一个页面是有数多个小东西组合而来的,于是我们就要请出谷歌浏览器,让浏览器加载页面慢下来,慢慢找。
第一步:打开谷歌浏览器的开发者工具
第二步:点击Network,先禁止缓存,再清除缓存。

第三步:设置加载速度,这里我选择Slow 3G的网速加载该页面

第四步:我们可以开始慢加载界面了,点击重新加载界面

当我们看到评论刚被加载出来的时候点击这个叉叉,界面就暂停了。
然后我们就可以开始找寻了(红色是还没有加载的文件,不需要看的)


很快我们就找到了

双击发现界面没有,原来是POST的方式获取的数据,双击打开默认是GET

知道数据存放的位置就好办了,只需要用Python的requests库模仿浏览器向该网址POST一下就OK了。
不过有些网站会有反爬虫机制,所以我们需要加点小东西。
找到该页面的头文件信息

找到下面的数据


所以下面代码的数据就这么来的

总结说明
requests是python实现的最简单易用的HTTP库,建议爬虫使用requests。json是python用来将对象转化为Python的JSON数据格式对象。
下面是我爬取的成果和代码供大家参考
爬取腾讯房产的2017年房价


import requests
import bs4
import re
import openpyxl
def open_url(url):
headers = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"}
res = requests.get(url,headers=headers)
return res
def find_data(res):
data = []
soup = bs4.BeautifulSoup(res.text,"html.parser")
content = soup.find(id="Cnt-Main-Article-QQ")
target = content.find_all("p",style="TEXT-INDENT: 2em")
target = iter(target)
for each in target:
if each.text.isnumeric():
data.append([
re.search(r'\[(.+)\]',next(target).text).group(1),
re.search(r'\d.*',next(target).text).group(),
re.search(r'\d.*',next(target).text).group(),
re.search(r'\d.*',next(target).text).group()
])
return data
def to_excel(data):
wb = openpyxl.Workbook()
wb.guess_type = True
wx = wb.active
wx.append(['城市','平均房价','平均工资','房价工资比'])
for each in data:
wx.append(each)
wb.save("2017年中国主要城市房价工资比排行榜.xlsx")
def main():
url = "http://news.house.qq.com/a/20170702/003985.htm"
res = open_url(url)
data = find_data(res)
to_excel(data)
if __name__ == "__main__":
main()
爬取豆瓣的TOP电影


import requests
import bs4
import re
def open_url(url):
#使用代理
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
res = requests.get(url,headers=headers)
return res
def find_movies(res):
soup = bs4.BeautifulSoup(res.text,"html.parser")
#电影名
movies = []
targets = soup.find_all("div",class_="hd")
for each in targets:
movies.append(each.a.span.text)
#评分
ranks = []
targets = soup.find_all("span",class_="rating_num")
for each in targets:
ranks.append("评分:%s"%each.text)
#资料
messages = []
targets = soup.find_all("div",class_="bd")
for each in targets:
try:
messages.append(each.p.text.split('\n')[1].strip() + each.p.text.split('\n')[2].strip())
except:
continue
result=[]
length = len(movies)
for i in range(length):
result.append(movies[i] + ranks[i] +messages[i] + '\n')
return result
#找出一共多少个页面
def find_depth(res):
soup = bs4.BeautifulSoup(res.text,"html.parser")
depth = soup.find('span',class_='next').previous_sibling.previous_sibling.text
return int(depth)
def main():
host = "https://movie.douban.com/top250"
res = open_url(host)
depth = find_depth(res)
result = []
for i in range(depth):
url = host+'/?start=' + str(25*i)
res = open_url(url)
result.extend(find_movies(res))
with open("豆瓣Top250电影.txt","w",encoding="utf-8") as f:
for each in result:
f.write(each)
if __name__ == "__main__":
main()
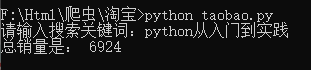
爬取淘宝某商品的总销量
这个小实践需要用到cookie,通过cookie可以登录淘宝界面下爬取否则无法爬取。
cookie可以在下图中找到

成果图
import requests
import re
import json
def open_url(keyword,page=1):
#&s=0 表示从第1个商品开始显示,由于1页是44个商品,所以$s = 44表示第二页
# &sort = sale-desc 表示按销量排序
playload = {'q':keyword,'s':str((page-1)*44),"sort":"sale-desc"}
url = "https://s.taobao.com/search"
cookie = "你自己登录淘宝后浏览器的cookie"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",
"Cookie":cookie
}
res = requests.get(url,params=playload,headers=headers)
return res
#获取列表页的所有商品
def get_items(res):
g_page_config = re.search(r'g_page_config = (.*?);\n',res.text)
page_config_json = json.loads(g_page_config.group(1))
page_items = page_config_json['mods']['itemlist']['data']['auctions']
results = []#整理出我们关注的信息(ID、标题、链接、售价、销量和商家)
for each_item in page_items:
dict1 = dict.fromkeys(('nid','title','detail_url','view_price','view_sales','nick'))
dict1['nid'] = each_item['nid']
dict1['title'] = each_item['title']
dict1['detail_url'] = each_item['detail_url']
dict1['view_price'] = each_item['view_price']
dict1['view_sales'] = each_item['view_sales']
dict1['nick'] = each_item['nick']
results.append(dict1)
return results
#统计该页面所有商品的销量
def count_sales(items):
count = 0
for each in items:
if '基础教程' in each['title']:
count += int(re.search(r'\d+',each['view_sales']).group())
return count
def main():
keyword = input("请输入搜索关键词:")
length = 3
total = 0
for each in range(length):
res = open_url(keyword,each+1)
items = get_items(res)
total += count_sales(items)
print("总销量是:",total)
if __name__ == "__main__":
main()
原文链接:https://blog.csdn.net/qq_38386639/article/details/104971054
所属网站分类: 技术文章 > 博客
作者:sjhjf0293
链接:https://www.pythonheidong.com/blog/article/270831/a6eaa429a83fb6276df1/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力