

荐CenterLoss在MNIST上的实现
发布于2020-03-20 11:24 阅读(1958) 评论(0) 点赞(6) 收藏(2)
MNIST特征提取解释图像识别之CenterLoss
一、提出问题
在图像识别中,一个很关键的要素就是图像中提取出来的特征,它关乎着图像识别的精准度。而通常用的softmax输出函数提取到的特征之间往往接的很紧,无太大的明显界限。在根据这些特征做识别的时候会出现模拟两可的情况,那么怎么让提取到的特征之间差异性更大从而提高识别的正确率就成了图像识别的一个重大问题。
二、解决办法:
有研究就提出了解决问题的方法:减小类内聚,增大类间距,于是就有了后面的CenterLoss和ArcLoss
CenterLoss是减小类内聚,间接增大类间距;ArcLoss直接增大类间距
1、CenterLoss公式
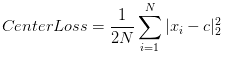
2、CenterLoss原理及效果
它的目的是给每个类别的特征加一个中心点,然后使这一类别的特征点与它的中心的距离总和作为一个损失,然后去优化这个损失,使他们彼此无限靠近。从理论层面上讲,当学习到一定程度后,每个类别的特征会集中为一个点上,但从实际上说,这几乎是不太可能的,只能说接近于重叠在一个点。
如图1为 (log_softmax + NLLLoss)+Adam 输出的特征图
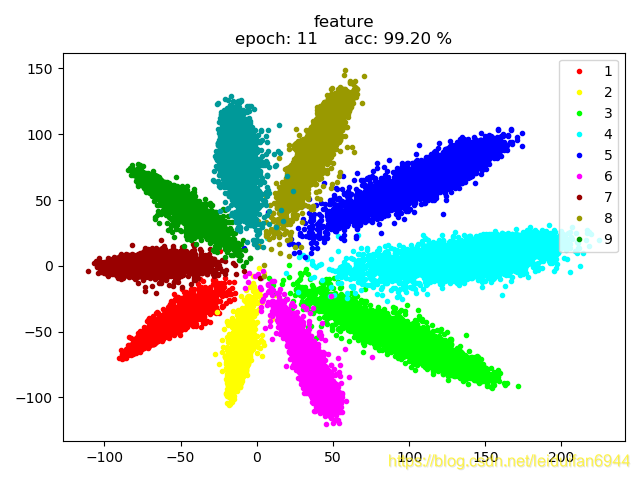
如图2为 CenterLoss 的原理

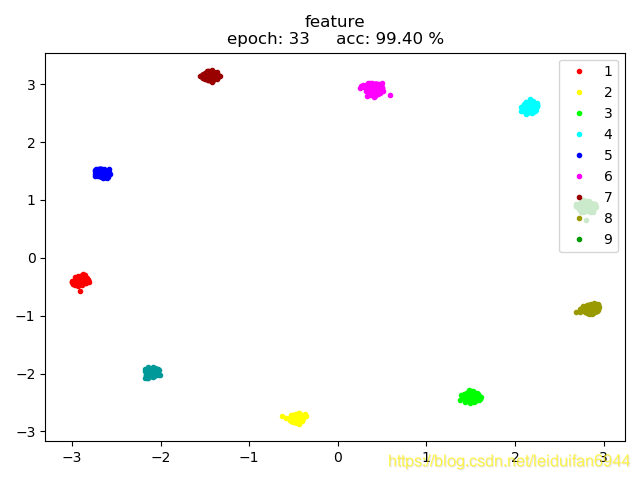
三、最终效果:
如图3为 (log_softmax + NLLLoss) + CenterLoss +Adam 的效果,网络中使用BacthNorm,且输出层bias=False,Centerloss中也对输入特征进行了Normalize
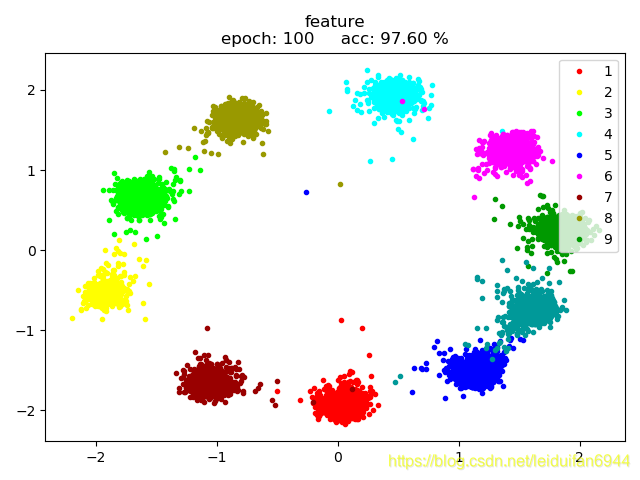
四、附:
当网络不加Bacthnorm,Centerloss中对输入特征不做normalize时,训练将会很费时,而且效果也不是很理想。如下图4即为(log_softmax + NLLLoss) + CenterLoss + Adam,网络不加Bacthnorm,Centerloss未做normalize时的效果。
五、源码:
class CenterLoss(nn.Module):
def __init__(self, cls_num, feature_num):
"""
:param cls_num: 类别数量
:param feature_num: 特征维度
"""
super().__init__()
self.cls_num = cls_num
# 随机10个center
self.center = nn.Parameter(torch.randn(cls_num, feature_num), requires_grad=True)
def forward(self, feature, _target):
"""
:param feature: 特征输入
:param _target: 标签输入
:return: 中心损失值
"""
feature = F.normalize(feature) # 对特征做归一化
# 将center广播成特征点那么多个,每一个特征对应一个center
centre = self.center.cuda().index_select(dim=0, index=_target.long())
# 统计每个类别有多少的数据
counter = torch.histc(_target, bins=self.cls_num, min=0, max=self.cls_num-1)
# 将每个类别的统计数量广播,每个数据对应一个该类的总数,好做计算
count = counter[_target.long()]
centre_dis = feature - centre # 做差,每个特征到它中心点的距离
pow_ = torch.pow(centre_dis, 2) # 平方
sum_1 = torch.sum(pow_, dim=1) # 横向求和,每个类别的距离总和
dis_ = torch.div(sum_1, count.float()) # 类别差,每个类别的差除以该类的总量,得到该类均差
# sqrt_ = torch.sqrt_(dis_) # 开方
sum_2 = torch.sum(dis_) # 求总差,所有类别的差
res = sum_2 / 2.0 # 乘:lambda / 2,
return res
原文链接:https://blog.csdn.net/leiduifan6944/article/details/104966867
所属网站分类: 技术文章 > 博客
作者:编程gogogo
链接:https://www.pythonheidong.com/blog/article/270941/544cf11290cb73b2f02a/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力