

pytorch相关问题
发布于2020-03-31 12:29 阅读(1883) 评论(0) 点赞(17) 收藏(4)
1. softmax问题
pytorch中有两个softmax,一个在torch.nn中,一个在torch.nn.functional中,顾明思想,torch.nn.functional.softmax就是一个函数,直接使用即可,torch.nn.Softmax和torch.nn.RNN一样是个类,需要先初始化,然后赋值
2. pytorch都有哪些损失函数
pytorch的损失函数都在torch.nn下面
- torch.nn.L1Loss(size_average=None, reduce=None, reduction=‘mean’):回归问题中,使用绝对值的损失函数
- torch.nn.MSELoss(size_average=None, reduce=None, reduction=‘mean’):回归问题中,使用平方和的损失函数(即最小二乘法)
- torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction=‘mean’):多分类,就是softmax对应的交叉熵损失函数,可以自定义每个类别的weight
- torch.nn.CTCLoss(blank=0, reduction=‘mean’, zero_infinity=False)
- torch.nn.NLLLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction=‘mean’):当使用torch.nn.LogSoftmax时,对应的损失函数
- torch.nn.PoissonNLLLoss(log_input=True, full=False, size_average=None, eps=1e-08, reduce=None, reduction=‘mean’)
- torch.nn.KLDivLoss(size_average=None, reduce=None, reduction=‘mean’)
- torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction=‘mean’):该损失函数就是逻辑回归(二分类)对应的logloss损失函数
- torch.nn.BCEWithLogitsLoss(weight=None, size_average=None, reduce=None, reduction=‘mean’, pos_weight=None)
- torch.nn.MarginRankingLoss(margin=0.0, size_average=None, reduce=None, reduction=‘mean’)
- torch.nn.HingeEmbeddingLoss(margin=1.0, size_average=None, reduce=None, reduction=‘mean’)
- torch.nn.MultiLabelMarginLoss(size_average=None, reduce=None, reduction=‘mean’)
- torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction=‘mean’)
- torch.nn.SoftMarginLoss(size_average=None, reduce=None, reduction=‘mean’)
- torch.nn.MultiLabelSoftMarginLoss(weight=None, size_average=None, reduce=None, reduction=‘mean’)
- torch.nn.CosineEmbeddingLoss(margin=0.0, size_average=None, reduce=None, reduction=‘mean’)
- torch.nn.MultiMarginLoss(p=1, margin=1.0, weight=None, size_average=None, reduce=None, reduction=‘mean’)
- torch.nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, size_average=None, reduce=None, reduction=‘mean’)
3. 优化器
pytorch优化方法都封装在torch.optim中,主要有以下(加粗和常用的):
- torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)
- torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0, eps=1e-10)
- torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
- torch.optim.AdamW(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.01, amsgrad=False)
- torch.optim.SparseAdam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08)
- torch.optim.Adamax(params, lr=0.002, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
- torch.optim.ASGD(params, lr=0.01, lambd=0.0001, alpha=0.75, t0=1000000.0, weight_decay=0)
- torch.optim.LBFGS(params, lr=1, max_iter=20, max_eval=None, tolerance_grad=1e-07, tolerance_change=1e-09, history_size=100, line_search_fn=None)
- torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)
- torch.optim.Rprop(params, lr=0.01, etas=(0.5, 1.2), step_sizes=(1e-06, 50))
- torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)
实战发现,优化器的选择很重要,lr也很重要。 - 优化器使用方法:
- 基本使用方法
import optim
ptimizer=optim.SGD(params=net.parameters(),lr=0.1)
optimizer.zero_grad() //梯度清零
output=net(input)
output.backward(output)
optimizer.step()
- 为不同的层设置不同的学习率
# 方法1
# 为不同子网络设置不同的学习率,在finetune中经常用到
# 如果对某个参数不指定学习率,就使用最外层的默认学习率(如feature层就使用1e-5)
optimizer =optim.SGD([
{'params': net.features.parameters()}, # 学习率为1e-5
{'params': net.classifier.parameters(), 'lr': 1e-2}
],
lr=1e-5)
# 方法2
# 只为两个全连接层设置较大的学习率,其余层的学习率较小
special_layers = nn.ModuleList([net.classifier[0], net.classifier[3]])
special_layers_params = list(map(id, special_layers.parameters()))
base_params = filter(lambda p: id(p) not in special_layers_params,
net.parameters())
optimizer = t.optim.SGD([
{'params': base_params},
{'params': special_layers.parameters(), 'lr': 0.01}
], lr=0.001 )
具体的可见下述代码
import torch
class TwoLayerNet(torch.nn.Module):
def __init__(self, d_input, d_hidden, d_output):
super(TwoLayerNet, self).__init__()
self.linear1 = torch.nn.Linear(d_input, d_hidden)
self.linear2 = torch.nn.Linear(d_hidden, d_output)
def forward(self, x):
h_relu = self.linear1(x).clamp(min=0)
Y_pred = self.linear2(h_relu)
Y_pred = torch.nn.functional.softmax(Y_pred, axis=1)
return Y_pred
n, d_input, d_hidden, d_output = 64, 1000, 100, 10
# Create random Tensors to hold inputs and outputs
X = torch.randn(n, d_input) # shape(64, 1000)
Y = torch.randn(n, d_output) # 10分类问题
model = TwoLayerNet(d_input, d_hidden, d_output)
criterion = torch.nn.CrossEntropyLoss(reduction='sum')
all_params = model.parameters()
print('all_params:', all_params)
weight_params = []
quant_params = []
print('model.named_parameters():', model.named_parameters())
# 根据自己的筛选规则 将所有网络参数进行分组
for pname, p in model.named_parameters():
print('pname', pname, 'p.shape:', p.shape)
if any([pname.endswith(k) for k in ['cw', 'dw', 'cx', 'dx', 'lamb']]):
quant_params += [p]
elif ('conv' or 'fc' in pname and 'weight' in pname):
weight_params += [p]
# 取回分组参数的id
params_id = list(map(id, weight_params)) + list(map(id, quant_params))
print('params_id:', params_id)
# 取回剩余分特殊处置参数的id
other_params = list(filter(lambda p: id(p) not in params_id, all_params))
print('other_params:', other_params)
# 构建不同学习参数的优化器
optimizer = torch.optim.SGD([
{'params': other_params},
{'params': quant_params, 'lr': 0.1*0.1},
{'params': weight_params, 'weight_decay': 0.1}],
lr=0.01,
momentum=0.1,
)
all_params: <generator object Module.parameters at 0x00000267D2565048>
model.named_parameters(): <generator object Module.named_parameters at 0x00000267E437FB48>
pname linear1.weight p.shape: torch.Size([100, 1000])
pname linear1.bias p.shape: torch.Size([100])
pname linear2.weight p.shape: torch.Size([10, 100])
pname linear2.bias p.shape: torch.Size([10])
params_id: [2645231002536, 2645231004048, 2645231004120, 2645231004192]
other_params: []
- 调整学习率
# 方法1
# 新建一个optimizer。对于使用动量的优化器(如Adam),会丢失动量等状态信息,可能会造成损失函数的收敛出现震荡等情况
old_lr = 0.1
optimizer1 =optim.SGD([
{'params': net.features.parameters()},
{'params': net.classifier.parameters(), 'lr': old_lr*0.1}
], lr=1e-5)
# 方法2: 调整学习率, 手动decay, 保存动量
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.1 # 学习率为之前的0.1倍
optimizer
# 具体实现
def adjust_learning_rate(optimizer, epoch, lr):
"""Sets the learning rate to the initial LR decayed by 10 every 2 epochs"""
lr *= (0.1 ** (epoch // 2))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
model = AlexNet(num_classes=2)
optimizer = optim.SGD(params = model.parameters(), lr=10)
plt.figure()
x = list(range(10))
y = []
lr_init = optimizer.param_groups[0]['lr']
for epoch in range(10):
adjust_learning_rate(optimizer, epoch, lr_init)
lr = optimizer.param_groups[0]['lr']
print(epoch, lr)
y.append(lr)
plt.plot(x,y)
上面代码用到了optimizer.param_groups,这个到底是什么,可以见下
import torch
class TwoLayerNet(torch.nn.Module):
def __init__(self, d_input, d_hidden, d_output):
super(TwoLayerNet, self).__init__()
self.linear1 = torch.nn.Linear(d_input, d_hidden)
self.linear2 = torch.nn.Linear(d_hidden, d_output)
def forward(self, x):
h_relu = self.linear1(x).clamp(min=0)
Y_pred = self.linear2(h_relu)
return Y_pred
# 定义样本数,输入层维度,隐藏层维度,输出层维度
n, d_input, d_hidden, d_output = 64, 1000, 100, 10
# Create random Tensors to hold inputs and outputs
X = torch.randn(n, d_input) # shape(64, 1000)
Y = torch.randn(n, d_output) # 10分类问题
# Construct our model by instantiating the class defined above
model = TwoLayerNet(d_input, d_hidden, d_output)
# Construct our loss function and an Optimizer. The call to model.parameters()
# in the SGD constructor will contain the learnable parameters of the two
# nn.Linear modules which are members of the model.
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4)
print(type(optimizer)) # SGD类型
print(optimizer)
print(dir(optimizer)) # 方法中有一个param_groups方法
for i in optimizer.param_groups:
print(type(i)) # param_groups中每一个元素都是字典
print(i.keys()) # 字典中共有6个key,其中有一个就是lr,记录了优化器的lr
print(i['lr']) # 目前lr的取值
print(type(i['params'])) # 记录了当前参数
print(i['params'][0].shape) # list中每个参数都是tensor
break
<class 'torch.optim.sgd.SGD'>
SGD (
Parameter Group 0
dampening: 0
lr: 0.0001
momentum: 0
nesterov: False
weight_decay: 0
)
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'add_param_group', 'defaults', 'load_state_dict', 'param_groups', 'state', 'state_dict', 'step', 'zero_grad']
<class 'dict'>
dict_keys(['params', 'lr', 'momentum', 'dampening', 'weight_decay', 'nesterov'])
0.0001
<class 'list'>
torch.Size([100, 1000])
关于优化器学习率的调整,pytorch已经封装好了,可详见博客https://blog.csdn.net/weixin_43722026/article/details/103271611
- PyTorch学习率调整策略通过torch.optim.lr_scheduler接口实现。PyTorch提供的学习率调整策略分为三大类,分别是
- 有序调整:等间隔调整(Step),按需调整学习率(MultiStep),指数衰减调整(Exponential)和 余弦退火CosineAnnealing。
- 自适应调整:自适应调整学习率 ReduceLROnPlateau。
- 自定义调整:自定义调整学习率 LambdaLR。
- 等间隔调整学习率 StepLR
等间隔调整学习率,调整倍数为 gamma 倍,调整间隔为 step_size。间隔单位是step。需要注意的是, step 通常是指 epoch,不要弄成 iteration 了。
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
'''
参数:
step_size(int)
学习率下降间隔数,若为 30,则会在 30、 60、 90…个 step 时,将学习率调整为 lr*gamma。
gamma(float)
学习率调整倍数,默认为 0.1 倍,即下降 10 倍。
last_epoch(int)
上一个 epoch 数,这个变量用来指示学习率是否需要调整。当last_epoch 符合设定的间隔时,就会对学习率进行调整。当为-1 时,学习率设置为初始值。
- 按需调整学习率 MultiStepLR
# 按设定的间隔调整学习率。这个方法适合后期调试使用,观察 loss 曲线,
# 为每个实验定制学习率调整时机。
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
'''
参数:
milestones(list)
一个 list,每一个元素代表何时调整学习率, list 元素必须是递增的。如 milestones=[30,80,120]
gamma(float)
学习率调整倍数,默认为 0.1 倍,即下降 10 倍。
'''
- 指数衰减调整学习率 ExponentialLR
# 按指数衰减调整学习率,调整公式: lr=l∗gamma∗∗epoch
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
'''
参数:
gamma
学习率调整倍数的底,指数为 epoch,即 gamma**epoch
'''
- 余弦退火调整学习率 CosineAnnealingLR
以余弦函数为周期,并在每个周期最大值时重新设置学习率。以初始学习率为最大学习率,以 2∗Tmax
2∗Tmax 为周期,在一个周期内先下降,后上升。
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
'''
参数:
T_max(int)
一次学习率周期的迭代次数,即 T_max 个 epoch 之后重新设置学习率。
eta_min(float)
最小学习率,即在一个周期中,学习率最小会下降到 eta_min,默认值为 0。
'''
- 自适应调整学习率 ReduceLROnPlateau
当某指标不再变化(下降或升高),调整学习率,这是非常实用的学习率调整策略。
例如,当验证集的 loss 不再下降时,进行学习率调整;或者监测验证集的 accuracy,当accuracy 不再上升时,则调整学习率。
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
'''
参数:
mode(str)
模式选择,有 min 和 max 两种模式, min 表示当指标不再降低(如监测loss), max 表示当指标不再升高(如监测 accuracy)。
factor(float)
学习率调整倍数(等同于其它方法的 gamma),即学习率更新为 lr = lr * factor
patience(int)
忍受该指标多少个 step 不变化,当忍无可忍时,调整学习率。
verbose(bool)
是否打印学习率信息, print(‘Epoch {:5d}: reducing learning rate of group {} to {:.4e}.’.format(epoch, i, new_lr))
threshold_mode(str)
选择判断指标是否达最优的模式,有两种模式, rel 和 abs。
当 threshold_mode == rel,并且 mode == max 时, dynamic_threshold = best * ( 1 +threshold );
当 threshold_mode == rel,并且 mode == min 时, dynamic_threshold = best * ( 1 -threshold );
当 threshold_mode == abs,并且 mode== max 时, dynamic_threshold = best + threshold ;
当 threshold_mode == rel,并且 mode == max 时, dynamic_threshold = best - threshold;
threshold(float)
配合 threshold_mode 使用。
cooldown(int)
“冷却时间“,当调整学习率之后,让学习率调整策略冷静一下,让模型再训练一段时间,再重启监测模式。
min_lr(float or list)
学习率下限,可为 float,或者 list,当有多个参数组时,可用 list 进行设置。
eps(float)
学习率衰减的最小值,当学习率变化小于 eps 时,则不调整学习率。
- 自定义调整学习率 LambdaLR
为不同参数组设定不同学习率调整策略。调整规则为,
lr=base_lr∗lmbda(self.last_epoch)
lr=base_lr∗lmbda(self.last_epoch)
fine-tune 中十分有用,我们不仅可为不同的层设定不同的学习率,还可以为其设定不同的学习率调整策略。
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
'''
参数:
lr_lambda(function or list)
一个计算学习率调整倍数的函数,输入通常为 step,当有多个参数组时,设为 list。
- 自定义调整学习率
#优化器针对loss进行参数更新,分三档
if (loss.item() <= 0.4) & lr_flag1:
for p in optimizer.param_groups:
p['lr'] = 3e-3
lr_flag1 = 0
if (loss.item() <= 0.2) & lr_flag1:
for p in optimizer.param_groups:
p['lr'] = 3e-4
lr_flag2 = 0
if (loss.item() <= 0.05) & lr_flag1:
for p in optimizer.param_groups:
p['lr'] = 3e-5
lr_flag3 = 0
4. embedding
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None)
- num_embedding:词汇表词的总个数
- embedding_dim:词向量维度
对于每个样本,传入的数据是n个单词对应的index,最终输出为(batch_size, seq_length, embedding_dim)
这时向量是随机初始化的
官方例子如下:

设置随机种子
from torch import nn
from torch.autograd import Variable
# 定义词嵌入
embeds = nn.Embedding(2, 5) # 2 个单词,维度 5
# 得到词嵌入矩阵,开始是随机初始化的
torch.manual_seed(1)
embeds.weight
# 输出结果:
Parameter containing:
-0.8923 -0.0583 -0.1955 -0.9656 0.4224
0.2673 -0.4212 -0.5107 -1.5727 -0.1232
[torch.FloatTensor of size 2x5]
如果需要加载预训练好的向量,使用如下:
# FloatTensor containing pretrained weights
weight = torch.FloatTensor([[1, 2.3, 3], [4, 5.1, 6.3]])
embedding = nn.Embedding.from_pretrained(weight)
# Get embeddings for index 1
input = torch.LongTensor([1])
embedding(input)
tensor([[ 4.0000, 5.1000, 6.3000]])
5. 使用GPU
- 将模型和输入模型的数据(tensor或者Variable等)添加到cuda(),如
x=x.cuda()、model = model.cuda()
此时如何指定cuda
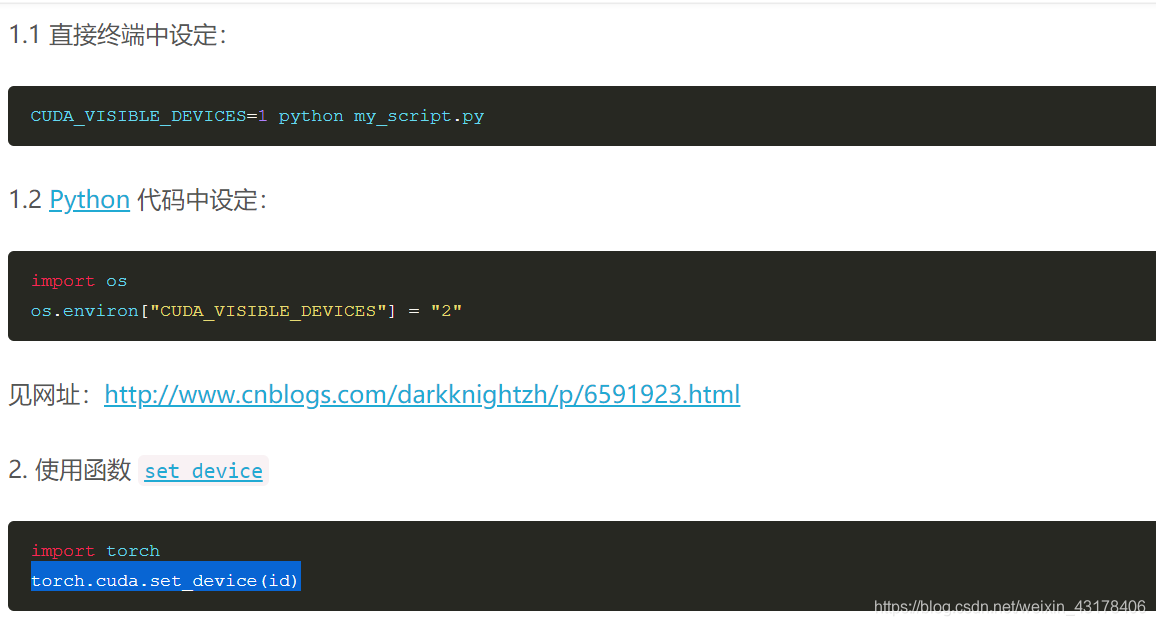
- 使用device
# 如果有cuda使用cuda,0表示第0块cuda,没有则使用cpu
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device) # 加不加model=都可以
- 使用多块cuda
此时不需要对input进行数据并行,只需要对模型进行并行
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = BiLSTMAttention(embedding_dim, num_classes, n_hidden, num_layers, weight) # 初始化BiLSTMAttention模型
if torch.cuda.device_count() > 1: # cuda个数
print('Use', torch.cuda.device_count(), 'gpus')
model = nn.DataParallel(model) # 模型并行
model.to(device) # 虽然并行,也需要将模型放到指定的一块cuda上
将数据从gpu转向cpu,只需要x.cpu()
6. tensor与numpy相互转化
6.1 tensor转numpy
x = tensor_input.numpy()
6.2 numpy转tensor
x = torch.from_numpy(numpy_data)
所属网站分类: 技术文章 > 博客
作者:imsorry
链接:https://www.pythonheidong.com/blog/article/292127/7ac522234551f4ecbbc6/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力