

Python学习笔记:字符编码原理和操作详解
发布于2020-04-07 18:05 阅读(1999) 评论(0) 点赞(21) 收藏(3)
一、电脑字符集的历史
1、电脑是如何将二进制与字符对应起来的?
我们知道,电脑底层只认识0和1的二进制数据,为了让电脑可以跟人类互动,我们使用8个二进制位(即1个字节)来对应一个更复杂的数字,
比如:使用二进制“01000001”来指代十进制“65”,也就是大写字母A
实际使用场景中,人类利用键盘打字符“A”时,实际上是打65这个数字,电脑再到表中寻找65所代表的二进制数据“01000001”,实际处理的是这个二进制数据,这样就对应起来了,
这种对应关系表就是最早的字符编码集ASCII码表,如下图:
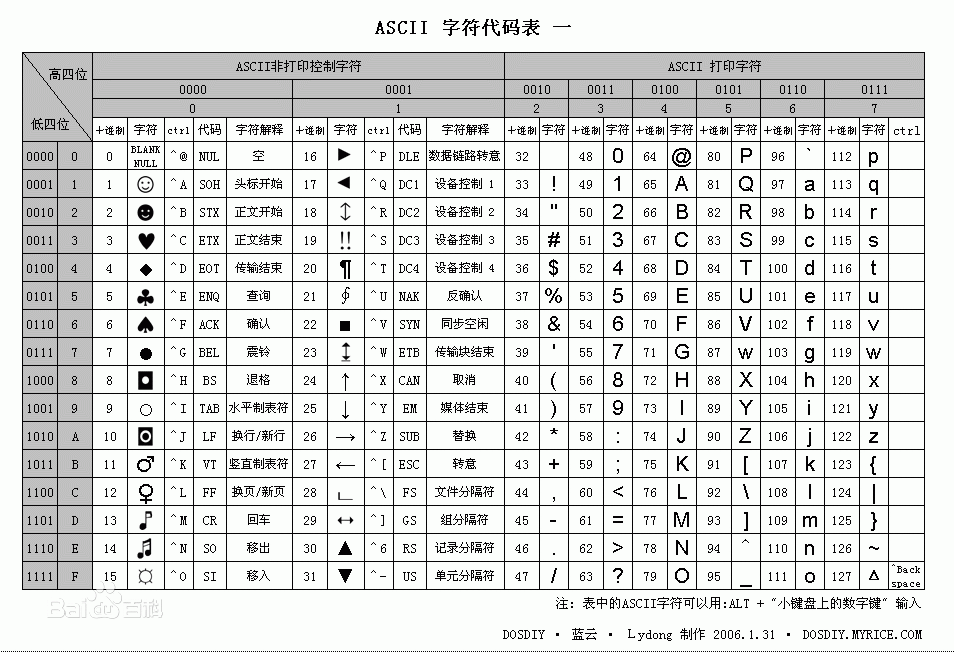
2、字符集是如何发展成一个庞大家族的?
电脑最初是西方人发明的,欧美国家的字符比较少,他们仅占用了前面127个位置就已经够用了,而8位的二进制数据最多可以表示255个不同的字符,剩下的128个字符就留给了别的国家,那么别国肯定是不够用的,怎么办?
于是聪明的中国人在ASCII码中规定几个位置,默认当电脑要寻找这几个位置的字符时就映射到另外一张表格中,而这张表格中存储了完整的中文字符,中文字符的发展历史如下:
a、GB2312:支持7000个汉字
b、GBK1.0:支持20000+个中文字符
c、GB18030:支持27000+个中文字符
d、Unicode:由于当时各国都发展出了自己的字符集,非常的混乱,于是国际标准组织统一将各国的字符集又整合成一个大字符集,即Unicode万国码,所有字符都至少占2个字节
e、UTF-8:这是Unicode的扩展集。使用了Unicode以后,西方人发现,自己原来的ASCII仅占1个字节,现在却需要至少2个字节存储,这样让原来的文件大了一倍,所以不干了,为了兼容原来的ASCII就有了UTF-8,规定英文字符依然是1字节,其他字符是3字节存储。
3、乱码问题是怎么产生的?
因为编码集繁多,不同编码集之间没有对应关系。比如中文和日文字符中都有“酒”这个字,但是在中文编码集中可能对应的是50这个数字,而日文中则对应的是100,那么如果将中文软件放在日文电脑中执行就会出现乱码。
所以产生乱码的根本原因有两点:
a、编码集中找不到这个编码:比如有些国家的字符异常的多,在该国编码集中对应30000的字符,在中文GB2312中可能就没有相应的字符,于是就无法显示。
b、编码集中对应到错误的编码:就算两个编码集中都有30000这个字符,但是因为编著的时候各自的数字对应的字符是不同的,所以也会造成乱码。
二、Python操作字符集
1、python2/python3中如何处理编码问题?
python3中默认是Unicode解码方式的,也就是说无论你的py文件是用何种编码格式,python3都默认将用Unicode重新解码,所以在py文件头部要声明编码格式,以告诉python3该文件的编码格式,请python3将文件解码成Unicode中对应的编码集
比如:py格式是用GBK编码的,python3在编译的时候会用Unicode来解码,这样就会报错,因为GBK的编码格式跟Unicode不同,你需要声明你使用的是GBK编码格式,然后python3再将GBK转成Unicode中对应的GBK集,这样就没问题了。
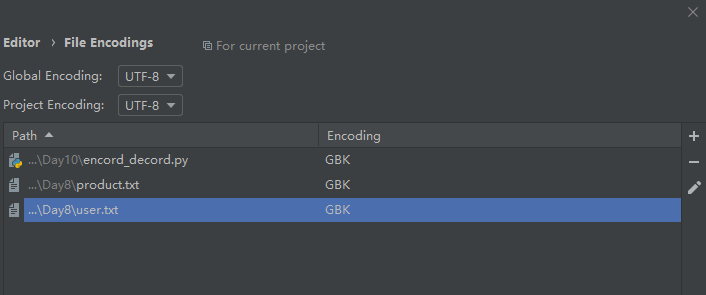
在pycharm中一般将编码全部改成utf-8即可,这样一来,编码是用uft-8,解码是Unicode,因为uft-8是Unicode的扩展集,是可以互相转换的,不会报错。如下图:
python2中也是一样的道理,不过python2中默认是用ASCII码解码的,所以如果你的py文件是用别的字符集编码的,则需要在头部声明编码格式,这样python2才会用对应的方式解码。
不声明编码方式的情况,在文件中出现中文,编译时就会报错!
2、不同编码集之间怎么转换?
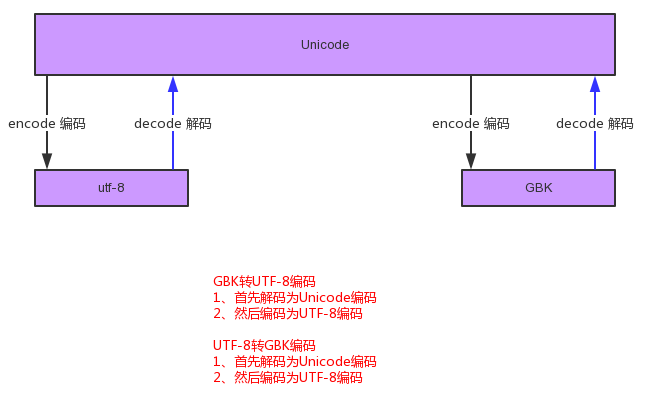
因为Unicord涵盖了所有编码集,所以只需要先解码成Unicord,这样就可以达到两个编码集互相转换的目的。
比如:中文gbk要转成uft-8,电脑则需要先找到gbk对应的Unicord中的对应编码(从gbk解码成Unicord),然后从Unicord编码成utf-8,即可。如下图:
3、python3中怎么用代码处理编码?
a、encode("coding"):即编码。将文本编码成指定的编码,返回该编码的字节码,参数coding是你想要编码的编码集。
b、decode(“coding”):即解码。将文本解码成Unicode编码集中对应的编码集,参数coding是告诉decode方法你之前用的是什么编码格式,如果不告知则无法从Unicode中找到对应的编码集。
比如:str1.decode(“gbk”),即,str1我之前是用gbk格式编码的,decode请你将我解码成Unicode中对应的gbk编码,
注意:gbk编码和Unicode中对应的gbk编码是不同的概念,因为Unicode已经重新将gbk编码过了,所以编码格式肯定是不同的,我们要将gbk解码成Unicode中的gbk,
就是为了能让Unicode起到兼容作用,这样在别的支持Unicode的电脑上也可以显示,不会乱码。
c、将gbk转utf-8,具体代码如下:
str1.decode("gbk").encode("utf-8")
d、将utf-8转gbk,具体代码如下:
str1.decode("utf-8").encode("gbk")
三、总结
总的来说,有3个要点:
1、你用什么编码集编码的,就要用什么编码集编码,比如:你用的是gbk编码,那么在解码的时候也要选择gbk,不然就会乱码或者不能解析报错
2、不同编码集之间的转换是通过Unicode编码集转换的,比如:你用gbk编码的要转成utf-8,就先要将gbk解码成Unicode中对应的gbk编码,然后再转成utf-8
3、如果解码的时候不知之前的编码格式,那么就会报错,需要先给定你的编码方式,然后解码成Unicode中对应的编码集
------------------------------------------------------------------------------------
参考:
1、文章:https://www.cnblogs.com/luotianshuai/articles/5735051.html
2、老男孩Alex的python课程
所属网站分类: 技术文章 > 博客
作者:以拯救苍生己任
链接:https://www.pythonheidong.com/blog/article/314793/a97fb59a347aafdcb641/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力