

面试题--python高级
发布于2019-08-03 09:01 阅读(3888) 评论(0) 点赞(10) 收藏(3)
第三章Python 高级
一.元类
1.Python 中类方法、类实例方法、静态方法有何区别?(2018-3-30-lxy)
类方法:是类对象的方法,在定义时需要在上方使用“@classmethod”进行装饰,形参为cls,
表示类对象,类对象和实例对象都可调用;
类实例方法:是类实例化对象的方法,只有实例对象可以调用,形参为self,指代对象本身;
静态方法:是一个任意函数,在其上方使用“@staticmethod”进行装饰,可以用对象直接调用,
静态方法实际上跟该类没有太大关系。
2.python会不会出现内存泄漏?
编程语言中内存的管理和分配一般有两种方式,程序手动回收和系统自动回收,前者的代表性语言就是C++,而python使用的是系统自动回收的机制。自动化管理的方式大大提供程序员的开发效率的同时,但是会在一些特殊的场景下可能会错误处理的情况,就像前段时间的美国波音737事件,传感器错误数据引起的飞机自动化系统操作强制下降,最终酿成事故
在python中是可能出现内存泄漏的,比如当对象A引用了对象B,同时对象B又引用了对象A,即出现了循环引用,Python中使用引用计数的内存管理方式,此时A和B的引用计数就会永远大于1,也就是说解释器将无法自动回收对象A和B的内存空间,也就产生了内存泄漏。随着该模块对象创建次数的逐渐增加,在操作系统负载上可以看到该Python程序内存持续上升,知道系统资源不够进程被强制终止3.过往的项目中有没有出现过性能问题?
有,有出现过性能问题,之前我参与的一个项目中有出现过内存泄漏的情况。
当时经过跟踪后发现有一个项目代码过程中有一个对象A引用对象B,同时对象B又引用对象A,即出现了循环引用。编程语言中内存的管理和分配一般有两种方式是,程序手动回收或者系统自动回收。前者的代表性语言就是C++,而Python使用的是系统自动回收的机制,自动化管理的方式大大提高了程序员的开发效率,但是在一些特殊的场景下也可能出现错误处理的情况,就像前段时间的美国波音737事件,传感器错误数据引发的飞机自动化系统操作强制下降,最终酿成事故
python中使用引用计数的内存管理方式,循环引用出现时对象的引用计数将永远大于等于1,也就是说解释器将无法自动回收对象A和B的内存空间,就会产生内存泄漏
####如何避免
1.不适用一个对象时 使用del object来删除一个对象的引用计数,可以有效防止内存泄露
2. 通过python扩展模块 gc 来查看不能回收的对象的详细信息
3. 可以通过sys.getrefcount(obj)来获取对象的引用计数,并根据返回值是否为0,来判断是否内存泄漏
三.函数
1.函数参数
1.1 Python 函数调用的时候参数的传递方式是值传递还是引用传递?(2018-3-30-lxy)
Python 的参数传递有:位置参数、默认参数、可变参数、关键字参数。
函数的传值到底是值传递还是引用传递,要分情况:
不可变参数用值传递:像整数和字符串这样的不可变对象,是通过拷贝进行传递的,因为你无论如何都不可能在原处改变不可变对象
可变参数是引用传递的:比如像列表,字典这样的对象是通过引用传递、和C 语言里面的用指针传递数组很相似,可变对象能在函数内部改变。
1.2 对缺省参数的理解?(2018-3-30-lxy)
缺省参数指在调用函数的时候没有传入参数的情况下,调用默认的参数,在调用函数的同时赋值时,所传入的参数会替代默认参数。
*args 是不定长参数,他可以表示输入参数是不确定的,可以是任意多个。
**kwargs 是关键字参数,赋值的时候是以键= 值的方式,参数是可以任意多对在定义函数的时候不确定会有多少参数会传入时,就可以使用两个参数。
1.5 有这样一段代码,print c 会输出什么,为什么?(2018-3-30-lxy)
1. a = 10
2. b = 20
3. c = [a]
4. a = 15
###结果:10 对于字符串,数字,传递的是相应的值
2.2 递归函数停止的条件?(2018-3-30-lxy)
递归的终止条件一般定义在递归函数内部,在递归调用前要做一个条件判断,根据判断的结果选择是继续调用自身,还是return;返回终止递归。
终止的条件:
- 判断递归的次数是否达到某一限定值
- 判断运算的结果是否达到某个范围等,根据设计的目的来选择
2.4 Python 主要的内置数据类型都有哪些? print dir( ‘a ’) 的输出?
内建类型:布尔类型、数字、字符串、列表、元组、字典、集合;
输出字符串‘a’的所有内建方法;
2.5 print(list(map(lambda x: x * x, [y for y in range(3)])))的输出?
[0, 1, 4]2.6 hasattr() getattr() setattr() 函数使用详解?(2018-4-16-lxy)
hasattr(object, name)函数:
判断一个对象里面是否有name 属性或者name 方法,返回bool 值,有name 属性(方法)返回True,否则返回False。
注意:name 要使用引号括起来。
1. class function_demo(object):
2. name = 'demo'
3. def run(self):
4. return "hello function"
5. functiondemo = function_demo()
6. res = hasattr(functiondemo, 'name') #判断对象是否有name 属性,True
7. res = hasattr(functiondemo, "run") #判断对象是否有run 方法,True
8. res = hasattr(functiondemo, "age") #判断对象是否有age 属性,Falsw
9. print(res)getattr(object, name[,default]) 函数:
获取对象object 的属性或者方法,如果存在则打印出来,如果不存在,打印默认值,默认值可选。
注意:如果返回的是对象的方法,则打印结果是:方法的内存地址,如果需要运行这个方法,可以在后面添加括号()。
1. functiondemo = function_demo()
2. getattr(functiondemo, 'name') #获取name 属性,存在就打印出来--- demo
3. getattr(functiondemo, "run") #获取run 方法,存在打印出方法的内存地址---<bound method function_demo.run of
<__main__.function_demo object at 0x10244f320>>
4. getattr(functiondemo, "age") #获取不存在的属性,报错如下:
5. Traceback (most recent call last):
6. File "/Users/liuhuiling/Desktop/MT_code/OpAPIDemo/conf/OPCommUtil.py", line 39, in <module>
7. res = getattr(functiondemo, "age")
8. AttributeError: 'function_demo' object has no attribute 'age'
9. getattr(functiondemo, "age", 18) #获取不存在的属性,返回一个默认值setattr(object,name,values)函数:
给对象的属性赋值,若属性不存在,先创建再赋值
1.class function_demo(object):
2. name = 'demo'
3. def run(self):
4. return "hello function"
5.functiondemo = function_demo()
6.res = hasattr(functiondemo, 'age') # 判断age 属性是否存在,False
7.print(res)
8.setattr(functiondemo, 'age', 18 ) #对age 属性进行赋值,无返回值
9.res1 = hasattr(functiondemo, 'age') #再次判断属性是否存在,True综合使用:
class function_demo(object):
name = 'demo'
def run(self):
return "hello function"
functiondemo = function_demo()
res = hasattr(functiondemo, 'addr')
# 先判断是否存在if res:
if res:
addr = getattr(functiondemo, 'addr')
print(addr)
else:
addr = getattr(functiondemo, 'addr', setattr(functiondemo, 'addr', '北京首都'))
#addr = getattr(functiondemo, 'addr', '美国纽约')
print(addr)2.7 一句话解决阶乘函数?(2018-4-16-lxy)
在Python2 中:
reduce(lambda x,y: x*y, range(1,n+1))
注意:Python3 中取消了该函数。
Lambda
3.2 下面这段代码的输出结果将是什么?请解释。(2018-3-30-lxy)
def multipliers1():
return [lambda x: i * x for i in range(4)]
print([m(2) for m in multipliers1()])
###【6,6,6,6】
def multipliers2():
for i in range(4): yield lambda x: i*x
print([m(2) for m in multipliers2()])
###【0,2,4,6】
上述问题产生的原因是Python 闭包的延迟绑定。这意味着内部函数被调用时,参数的值在闭包内
进行查找。因此,当任何由multipliers()返回的函数被调用时,i 的值将在附近的范围进行查找。那时,
不管返回的函数是否被调用,for 循环已经完成,i 被赋予了最终的值3。
一种解决方法就是用Python 生成器。
如上第二哥函数设计模式
1.1请手写一个单例
1.使用__new__方法
class A(object):
_instance = None
def __new__(cls, *args, **kwargs):
if cls._instance is None:
cls._instance = object.__new__(cls)
return cls._instance
else:
return cls._instance2.使用模块
新建一个py文件 mysingleton.py
class Singleton(object):
def foo(self):
pass
singleton = Singleton()
#将上面的代码保存在文件mysingleton.py中,要使用时,直接在其他文件中导入词文件中的对象,这个对象就是单例模式的对象3.使用装饰器
def Singleton(cls):
_instance = {}
def _singleton(*args, **kwargs):
if cls not in _instance:
_instance[cls] = cls(*args, **kwargs)
return _instance[cls]
return _singleton
@Singleton
class A(object):
a = 1
def __init__(self, x=0):
self.x = x
a1 = A(2)
a1 = A(3)1.2 单例模式的应用场景有哪些?(2018-4-16-lxy)
单例模式应用的场景一般发现在以下条件下:
(1)资源共享的情况下,避免由于资源操作时导致的性能或损耗等。如日志文件,应用配置。
(2)控制资源的情况下,方便资源之间的互相通信。如线程池等。1.网站的计数器2.应用配置3.多线程池4.
数据库配置,数据库连接池5.应用程序的日志应用....
生成器和迭代器
4.1 生成器、迭代器的区别?(2018-3-30-lxy)
迭代器是一个更抽象的概念,任何对象,如果它的类有next 方法和iter 方法返回自己本身,对于string、list、
dict、tuple 等这类容器对象,使用for 循环遍历是很方便的。在后台for 语句对容器对象调用iter()函数,iter()
是python 的内置函数。iter()会返回一个定义了next()方法的迭代器对象,它在容器中逐个访问容器内元素,next()
也是python 的内置函数。在没有后续元素时,next()会抛出一个StopIteration 异常。
生成器(Generator)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需要返回数
据的时候使用yield 语句。每次next()被调用时,生成器会返回它脱离的位置(它记忆语句最后一次执行的位置
和所有的数据值)
区别:生成器能做到迭代器能做的所有事,而且因为自动创建了iter()和next()方法,生成器显得特别简洁,而且
生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当
发生器终结时,还会自动抛出StopIteration 异常。
4.3 请尝试用“一行代码”实现将1-N 的整数列表以3 为单位分组,比如1-100分组后为? (2018-4-20-lxy)
print([[x for x in range(1, 100)][i:i + 3] for i in range(0, 100, 3)]) ##利用切片的原理
面向对象
2.1 Python 中的可变对象和不可变对象?(2018-3-30-lxy)
不可变对象,该对象所指向的内存中的值不能被改变。当改变某个变量时候,由于其所指的值不能被改变,相当于把原来的值复制一份后再改变,这会开辟一个新的地址,变量再指向这个新的地址。
可变对象,该对象所指向的内存中的值可以被改变。变量(准确的说是引用)改变后,实际上是其所指的值直接发生改变,并没有发生复制行为,也没有开辟新的出地址,通俗点说就是原地改变。
Python 中,数值类型(int 和float)、字符串str、元组tuple 都是不可变类型。而列表list、字典dict、集合set 是可变类型。
2.2 Python 中is 和==的区别?(2018-3-30-lxy)
is 判断的是a 对象是否就是b 对象,是通过id 来判断的。
==判断的是a 对象的值是否和b 对象的值相等,是通过value 来判断的。
2.3 Python 的魔法方法(2018-3-30-lxy)
魔法方法就是可以给你的类增加魔力的特殊方法,如果你的对象实现(重载)了这些方法中的某一个,那么这个方法就会在特殊的情况下被Python 所调用,你可以定义自己想要的行为,而这一切都是自动发生的。它们经常是两个下划线包围来命名的(比如__init__,lt),Python 的魔法方法是非常强大的,所以了解其使用方法也变得尤为重要!
init 构造器,当一个实例被创建的时候初始化的方法。但是它并不是实例化调用的第一个方法。
__new__才是实例化对象调用的第一个方法,它只取下cls 参数,并把其他参数传给init。__new__很少使
用,但是也有它适合的场景,尤其是当类继承自一个像元组或者字符串这样不经常改变的类型的时候。
call 允许一个类的实例像函数一样被调用。
getitem 定义获取容器中指定元素的行为,相当于self[key] 。
getattr 定义当用户试图访问一个不存在属性的时候的行为。
setattr 定义当一个属性被设置的时候的行为。
getattribute 定义当一个属性被访问的时候的行为。
什么是面向对象编程?
面向对象是相对于面向过程而言的。面向过程语言是一种基于功能分析的、以算法为中心的程序设计方法;而面向对象是一种基于结构分析的、以数据为中心的程序设计思想。在面向对象语言中有一个有很重要东西,叫做类。
面向对象有三大特性:封装、继承、多态。
封装:将某些内容先封装到一个地方,等需要的时候再去调用
class School:
def __init__(self,name,age): #构造方法,创建对象是执行
self.name=name
self.age=age
#创建对象a1,a2
a1=School("zhangsan",18)
a2=School("lisi",18)继承:即攀升类(子类)可以继承基类(父类)的方法,我们可以将多个类共有的方法提取到父类中,这样子类仅需要继承父类而不必实现每个方法
#使用class创建一个School类
class School:
def __init__(self,name,age):
self.name=name
self.age=age
def student(self):
print("name:%s,age:%s"%(self.name,self.age))
def classroom(self):
print("%s去教室"%self.name)
class SchoolA(School): #SchoolA继承School
def __init__(self,name):
self.name=name
class SchoolB(SchoolA): #SchoolB继承SchoolA
def __init__(self,name):
self.name=name
#创建对象a1
a1=SchoolA("zhangsan")
a1.classroom()
#创建对象a2
a2=SchoolB("lisi")
a2.classroom()
#执行结果:
# zhangsan去教室
# lisi去教室多继承
在python中 类可以继承多个类,在继承多个类时,它对类中的函数查找有两种当时,他对类中的函数查找有两种方式
深度优先:类是经典类hi,多继承的情况下,会按照深度有限的方式查找
广度优先:类是新式类,多继承的情况下,会按照广度优先的方式查找
(在python3中)都默认是广度优先,但还是可以了解一下两个的区别,
新式类:当前类或者基类继承了object类 就叫新式类,否则就是经典类
在python2.7中
#python2.7中经典类
class A():
def name(self):
print("AAAAAA")
class B(A):
pass
class C(A):
def name(self):
print("CCCCCC")
class D(B,C):
pass
a1=D()
a1.name() #输出:AAAAAA
#查找顺序:# 首先去自己D类中查找,如果没有,则继续去B类中找,没有则继续去A类中找,没有则继续去C类中找,如果还是未找到,则报错
#深度优先:D-B-A-C
#python2.7中新式类
class A(object):
def name(self):
print("AAAAAA")
class B(A):
pass
class C(A):
def name(self):
print("CCCCCC")
class D(B,C):
pass
a1=D()
a1.name() #输出:CCCCCC
#查找顺序:# 首先去自己D类中查找,如果没有,则继续去B类中找,没有则继续去C类中找,没有则继续去A类中找,如果还是未找到,则报错
#广度优先:D-B-C-A多态
不同的子类对象调用相同的父类方法,产生不同执行效果,可以增加代码的外部调用灵活度。父类变量能够引用子类对象,当子类中有重写父类父类方法,调用的将是子类对象
鸭子类型:
①出处:鸭子类型的名称来源于西方谚语:一只鸟长得像鸭子,叫声像鸭子,走路也像鸭子,那它就是鸭子!
②原则:如果想编写现有对象的自定义版本,可以继承该对象也可以创建一个外观和行为像,但与它无任何关系的全新对象,后者通常用于保存程序组件的松耦合度。
③优缺点:
- 优点:低耦合,每个相似的类之间都没有影响
- 缺点:对自觉性要求较高
④应用实例:list、tuple该两个类极为相似,但却没有用继承来实现,它们互为鸭子类型
六.正则表达式
1.Python 里match 与search 的区别?(2018-3-30-lxy)
match()函数只检测RE 是不是在string 的开始位置匹配,
search()会扫描整个string 查找匹配;
也就是说match()只有在0 位置匹配成功的话才有返回,
如果不是开始位置匹配成功的话,match()就返回none。
2.Python 字符串查找和替换?(2018-3-30-lxy)
1. re.findall(r’目的字符串’,’原有字符串’) #查询
2. re.findall(r'cast','itcast.cn')[0]
3. re.sub(r‘要替换原字符’,’要替换新字符’,’原始字符串’)
4. re.sub(r'cast','heima','itcast.cn')4.用Python 匹配HTML g tag 的时候,<.> 和<.?> 有什么区别?(2018-3-30-lxy)
<.*>是贪婪匹配,会从第一个“<”开始匹配,直到最后一个“>”中间所有的字符都会匹配到,中间可能会包含“<>”
<.*?>是非贪婪匹配,从第一个“<”开始往后,遇到的第一个“>”:结束匹配,这中间的字符串都会匹配到,但是不会有“<>”| 语法 | 说明 | 表达式实例 | 完整匹配的字符串 |
|---|---|---|---|
| . | 匹配任意除换行符"\n"外的字符。在DOTALL 模式中也能匹配换行符。 | a.c | abc |
| \ | 转义字符,使后一个字符改变原来的意思。如果字符串中有字符*需要匹配,可以使用*或者字符集[*] | a.c | a. c a\c |
| [...] | 字符集(字符类)。对应的位置可以是 字符集中任意字符。字符集中的字 符可以逐个列出,也可以给出范围, 如[abc]或[a-c]。第一个字符如果是^ 则表示取反,如[^abc]表示不是abc 的其他字符。 所有的特殊字符在字符集中都失去 其原有的特殊含义。在字符集中如 果要使用]、-或^,可以在前面加上反 斜杠,或把]、-放在第一个字符,把^ 放在非第—个字符。 |
a[bcd]e | abe ace ade |
| \d | 数字:[0-9] | a\dc | a1c |
| \D | 非数字:[^\d] | a\Dc | abc |
| \s | 空白字符:[<空格> t\r\n\f\v] | a\sc | ac |
| \S | 非空白字符:[^\s] | a\Sc | abc |
| \w | 单词字符:[A-Za-z0-9_] | a\wc | abc |
| \W | 非单词字符:[^\W] | a\Wc | ac |
| * | 匹配前一个字符0 或无限次 | abc* | ab abccc |
| + | 匹配前一个字符0 次或无限次 | abc+ | abc abccc |
| ? | 匹配前一个字符0 次或1次 | abc? | Ababc |
| {m} | 匹配前一个字符m | ab{2}c | abbc |
七.系统编程
1.进程总结
进程:程序运行在操作系统上的一个实例,就称之为进程。进程需要相应的系统资源:内存、时间
片、pid。
创建进程:
1.首先要导入multiprocessing 中的Process;
2.创建一个Process 对象;
3.创建Process 对象时,可以传递参数;
1.p = Process(target=XXX, args=(元组,) , kwargs={key:value})
2.target = XXX 指定的任务函数,不用加()
3.args=(元组,) , kwargs={key:value} 给任务函数传递的参数4.使用start()启动进程;
5.结束进程。
Process 语法结构:
Process([group [, target [, name [, args [, kwargs]]]]])
target:如果传递了函数的引用,可以让这个子进程就执行函数中的代码
args:给target 指定的函数传递的参数,以元组的形式进行传递
kwargs:给target 指定的函数传递参数,以字典的形式进行传递
name:给进程设定一个名字,可以省略
group:指定进程组,大多数情况下用不到
Process 创建的实例对象的常用方法有:
start():启动子进程实例(创建子进程)
is_alive():判断进程子进程是否还在活着
join(timeout):是否等待子进程执行结束,或者等待多少秒
terminate():不管任务是否完成,立即终止子进程
Process 创建的实例对象的常用属性:
name:当前进程的别名,默认为Process-N,N 为从1 开始递增的整数
pid:当前进程的pid(进程号)
给子进程指定函数传递参数Demo:
1.import osfrom multiprocessing import Process
2.import time
3.
4.def pro_func(name, age, **kwargs):
5. for i in range(5):
6. print("子进程正在运行中,name=%s, age=%d, pid=%d" %(name, age, os.getpid()))
7. print(kwargs)
8. time.sleep(0.2)
9.
10.if __name__ == '__main__':
11. # 创建Process 对象
12. p = Process(target=pro_func, args=('小明',18), kwargs={'m': 20})
13. # 启动进程
14. p.start()
15. time.sleep(1)
16. # 1 秒钟之后,立刻结束子进程
17. p.terminate()
18. p.join()
#注意:进程间不共享全局变量。
进程之间的通信-Queue
在初始化Queue()对象时,(例如q=Queue(),若在括号中没有指定最大可接受的消息数量,或数
量为负值时,那么就代表可接受的消息数量没有上限-直到内存的尽头)
Queue.qsize():返回当前队列包含的消息数量。
Queue.empty():如果队列为空,返回True,反之False。
Queue.full():如果队列满了,返回True,反之False。
Queue.get([block[,timeout]]):获取队列中的一条消息,然后将其从队列中移除,block 默认值为
True。
如果block 使用默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞
(停在读取状态),直到从消息列队读到消息为止,如果设置了timeout,则会等待timeout 秒,若还
没读取到任何消息,则抛出"Queue.Empty"异常;
如果block 值为False,消息列队如果为空,则会立刻抛出"Queue.Empty"异常;
Queue.get_nowait():相当Queue.get(False);
Queue.put(item,[block[, timeout]]):将item 消息写入队列,block 默认值为True;
如果block 使用默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写入,此
时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了timeout,则会等待
timeout 秒,若还没空间,则抛出"Queue.Full"异常;
如果block 值为False,消息列队如果没有空间可写入,则会立刻抛出"Queue.Full"异常;
Queue.put_nowait(item):相当Queue.put(item, False);
进程间通信Demo:
1.from multiprocessing import Process, Queueimport os, time, random
2.# 写数据进程执行的代码:def write(q):
3. for value in ['A', 'B', 'C']:
4. print('Put %s to queue...' % value)
5. q.put(value)
6. time.sleep(random.random())
7.# 读数据进程执行的代码:def read(q):
8. while True:
9. if not q.empty():
10. value = q.get(True)
11. print('Get %s from queue.' % value)
12. time.sleep(random.random())
13. else:
14. break
15.if __name__=='__main__':
16. # 父进程创建Queue,并传给各个子进程:
17. q = Queue()
18. pw = Process(target=write, args=(q,))
19. pr = Process(target=read, args=(q,))
20. # 启动子进程pw,写入:
21. pw.start()
22. # 等待pw 结束:
23. pw.join()
24. # 启动子进程pr,读取:
25. pr.start()
26. pr.join()
27. # pr 进程里是死循环,无法等待其结束,只能强行终止:
28. print('')
29. print('所有数据都写入并且读完')1.# -*- coding:utf-8 -*-
2.from multiprocessing import Poolimport os, time, random
3.def worker(msg):
4. t_start = time.time()
5. print("%s 开始执行,进程号为%d" % (msg,os.getpid()))
6. # random.random()随机生成0~1 之间的浮点数
7. time.sleep(random.random()*2)
8. t_stop = time.time()
9. print(msg,"执行完毕,耗时%0.2f" % (t_stop-t_start))
11.po = Pool(3) # 定义一个进程池,最大进程数3
12.for i in range(0,10):
13. # Pool().apply_async(要调用的目标,(传递给目标的参数元祖,))
14. # 每次循环将会用空闲出来的子进程去调用目标
15. po.apply_async(worker,(i,))
16.
17.print("----start----")
18.po.close() # 关闭进程池,关闭后po 不再接收新的请求
19.po.join() # 等待po 中所有子进程执行完成,必须放在close 语句之后
20.print("-----end-----")2. 什么是协程?
协程的概念最早提出于1963年,但由于其不符合当时崇尚的“自顶向下”的程序设计思想,未能成为当时主流编程语言的一部分
20世纪60年代,进程的概念被引入,进程作为操作系统资源分配和调度的基本单位,多进程的方式很长时间内大大提高了系统运行的效率,虽然中间产生了Copy-On-Write等技术的出现,但进程的频繁创建和销毁代价较大,资源的大量复制和分配耗时任然较高,于是80年代出现了能独立运行的单位--线程,调度执行的最小单位。多线程之间可以直接共享资源,同时线程之间得通信效率远高于进程间,讲任务并发得性能再次向前推了一大步,不过多线程有很多不足得地方,虽然说线程之间切花代价相较进程小了很多,但是一些场景下线程CPU时间片的大量切换其实是做了很多不必要的无用功,特别是python中因为GIL锁的存在,其多线程很多时候并不能提供程序运行效率,于是协程的概念又开始发挥了作用,是一个线程在执行,只有当该子程序内部发生中断或阻塞时,才会交出线程的执行权交给其他子程序,在适当的时候在返回来接着执行。这省区了线程间频繁切换的时间开销,同时也解决了多线程加锁造成的相关问题
具体的生产环境中,Python项目经常会使用多进程+协程的方式,规避GIL锁的问题,充分利用多核的同时又充分发挥协程高效的特性。
3.什么是多线程竞争?(2018-3-30-lxy)
线程是非独立的,同一个进程里线程是数据共享的,当各个线程访问数据资源时会出现竞争状态即:数据几乎同步会被多个线程占用,造成数据混乱,即所谓的线程不安全,那么怎么解决多线程竞争问题?-- 锁。
锁的好处:确保了某段关键代码(共享数据资源)只能由一个线程从头到尾完整地执行能解决多线程资源竞争下的原子操作问题。
锁的坏处:阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了
锁的致命问题:死锁。4.解释一下什么是锁,有哪几种锁? (2018-3-30-lxy)
锁(Lock)是Python 提供的对线程控制的对象。有互斥锁、可重入锁、死锁。
5.什么是死锁呢?(2018-3-30-lxy)
若干子线程在系统资源竞争时,都在等待对方对某部分资源解除占用状态,结果是谁也不愿先解锁,
互相干等着,程序无法执行下去,这就是死锁。
##死锁不代表程序终止,加上事物 ,过一段时间会回滚
GIL 锁(有时候,面试官不问,你自己要主动说,增加b 格,尽量别一问一答的尬聊,不然最后等到的一句话就是:你还有什么想问的么?)
GIL 锁全局解释器锁(只在cpython 里才有)
作用:限制多线程同时执行,保证同一时间只有一个线程执行,所以cpython 里的多线程其实是伪多线程!
所以Python 里常常使用协程技术来代替多线程,协程是一种更轻量级的线程,
进程和线程的切换时由系统决定,而协程由我们程序员自己决定,而模块gevent 下切换是遇到了耗时操作才会切换。
三者的关系:进程里有线程,线程里有协程。6.什么是线程安全,什么是互斥锁?(2018-3-30-lxy)
每个对象都对应于一个可称为" 互斥锁" 的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
同一个进程中的多线程之间是共享系统资源的,多个线程同时对一个对象进行操作,一个线程操作尚未结束,另一个线程已经对其进行操作,导致最终结果出现错误,此时需要对被操作对象添加互斥锁,保证每个线程对该对象的操作都得到正确的结果。
7. 说说下面几个概念:同步,异步,阻塞,非阻塞, 并行(parallel)和并发(concurrency)?(2018-3-30-lxy)
同步:多个任务之间有先后顺序执行,一个执行完下个才能执行。
异步:多个任务之间没有先后顺序,可以同时执行有时候一个任务可能要在必要的时候获取另一个
同时执行的任务的结果,这个就叫回调!
阻塞:如果卡住了调用者,调用者不能继续往下执行,就是说调用者阻塞了。
非阻塞:如果不会卡住,可以继续执行,就是说非阻塞的。
同步异步相对于多任务而言,阻塞非阻塞相对于代码执行而言。
并行:同一时刻多个任务同时在运行。
实现并行的库:multiprocessing
并发:在同一时间间隔内多个任务都在运行,但是并不会在同一时刻同时运行,存在交替执行的情况。
实现并发的库:threading8.Python 中的进程与线程的使用场景? (2018-3-30-lxy)
多进程适合在CPU 密集型操作(cpu 操作指令比较多,如位数多的浮点运算)。
多线程适合在IO 密集型操作(读写数据操作较多的,比如爬虫)。
IO 密集型:系统运作,大部分的状况是CPU 在等I/O (硬盘/内存)的读/写。
CPU 密集型:大部份时间用来做计算、逻辑判断等CPU 动作的程序称之CPU 密集型。
八.网络编程
1.1 I/O模型基础
更好的理解I/O模型,需要先回顾:同步、异步、阻塞、非阻塞
- 同步:执行完代码后,原地等待,直至出现结果
- 异步:执行完代码后,不等待,继续执行其他事务(常与回调机制关联)
- 阻塞:cpu在遇到I/O操作,进入阻塞状态,cpu切换到其他任务
- 非阻塞:不会遇到I/O操作,cpu一直处于计算状态
注:同步不等于阻塞
I/O模型总计有五种,其中信号驱动I/O,在实际中并不常用,主要还是学习另外四种I/O模型
- 阻塞I/O模型(blocking IO)
- 非阻塞I/O模型(nonblocking IO)
- 多路复用I/O模型(IO multiplexing)
- 异步I/O模型(asynchronous IO)
web开发中主要碰到的是网络I/O,对于一个network IO 它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,该操作会经历两个阶段:
#1)等待数据准备 (Waiting for the data to be ready)
#2)将数据从内核拷贝到进程中(Copying the data from the kernel to the process)这些IO模型的区别就是在两个阶段上各有不同的情况。在网络中常用的I/O操作有(accept,recv,send),其中send的感官比较少,主要是只存在本地copy阶段,对于网络传输如何不关注。
2.url到服务器,政府各过程会经历哪些?(例如访问百度)
按照TCP/IP五层协议描述
1.首先进行域名解析,域名解析具体过程如下:
- 浏览器搜索自己的DNS缓存,缓存中维护一张域名和ip地址的对应表
- 若没有,则搜索操作系统DNS缓存
- 没有,则操作系统将域名发送至本地域名服务器(递归查询方式), 本地域名服务器查询自己的DNS缓存,查询成功则返回结果,否则通过以下方式迭代查找:
- 本地域名服务器向根域名服务器发起请求,根域名服务器返回com域的顶级域名服务器的地址;
- 本地域名服务器向com域的顶级域名服务器发起请求,返回权限域名服务器地址;
- 本地域名服务器向权限域名服务器发起请求,得到IP地址
- 本地域名服务器将得到的IP地址返回给操作系统,同时自己将IP地址缓存起来;
- 操作系统将IP地址返回给浏览器,同时自己也将IP地址缓存起来:
2.应用层:浏览器发起HTTP请求
3.传输层:选择传输协议,TCP/UDP,TCP是可开的传输控制协议,对HTTP请求进行封装,加入端口号等信息;提供端到端的链接
4.网络层:通过IP协议讲ip地址封装成ip数据报,通过路由传输到对端,采用ARP协议,主机发送信息时讲包含目标的ip地址的ARP请求广播到网络上所有的主机,并接收返回信息,以此确定目标的物理地址
5.数据链路层:根据mac地址,建立链接
6.物理层:物理层传输010101的数据流
7.服务器户端要的资源,传回给客户端;断开TCP链接,浏览器对也买你进行渲染呈现给客户端
2:http和https协议
http协议:
- 端口:TCP80端口
- 超文本传输协议,信息是明文传输
- 连接简单,是基于无状态的传输。
https协议:
- 端口:TCP443端口
- 具有安全协议的超文本传输协议,具有安全性的ssl加密传输协议,信息是密文传输
- 由ssl+http协议构建的可进行加密传输,身份认证的网络协议
- https协议需要到ca机构申请ssl证书,免费证书较少,高级ssl证书需一定的费用
注:关于http版本的相关内容还待学习,主要是1.0/1.1/2.0版本之间的区别
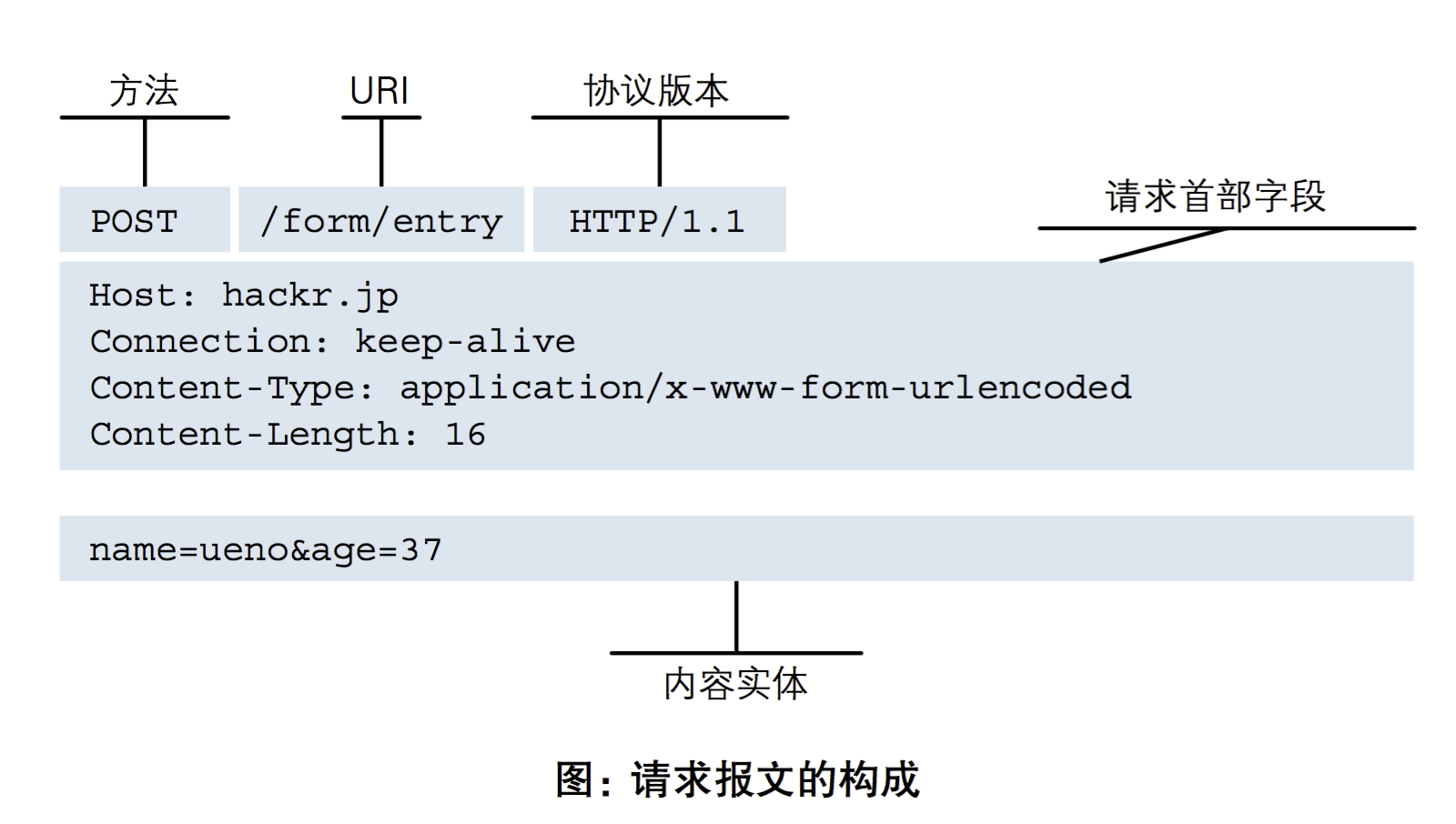
http请求报文:HTTP 请求报文由请求行、请求头部、空行 和 请求包体 4 个部分组成,如下图所示:
http响应报文:响应报文由状态行、响应头部、空行 和 响应包体 4 个部分组成,如下图所示:

请求报文以及响应报文相关具体的应用,需要参考具体的项目或者是实例。
3.状态码如200 OK,以3位数字和状态原因构成。数字中的第一位指定了响应级别,后两位无分别。响应分别有5种。
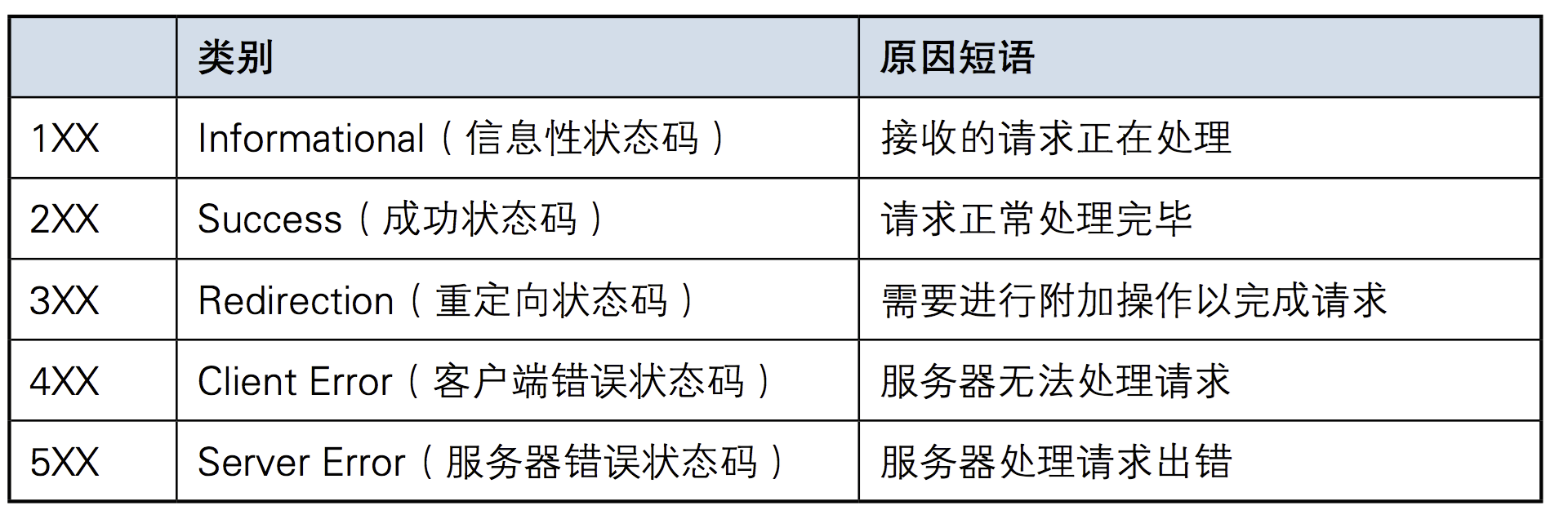
每个系列常用的code
2xx:200(get请求成功),201(post,put创建了一个资源),204(删除一个资源,服务器删除成功)
3xx:301(服务器永久移动,自动转发到新的位置),302(服务器临时移动,原服务器没有永久移除)俩者的最大区别为搜索引擎是否记录
4xx:400(客户端请求语法错误),403(服务器拒绝提供服务),404(客户端引用了不存在的资源)
5xx:500(服务器错误,拒绝请求),503(服务器当前不能处理客户请求,当前服务器不可用),504(请求超时,没有到达网关)
500,503,504常见场景
500:常见场景为编程语言语法错误,web脚本错误,高并发,打开文件数超过系统资源限制,一般解决思路为查看服务器nginx,python的错误日志,负载均衡,修复脚本错误
503:常见场景为服务器无法使用,一般为服务器超载或者是停机维护,解决思路为查看服务器系统资源或者确定服务器开启状态
502,504:常见场景为web服务器故障,程序进程不够,一般解决思路为查看nginx代理的问题,或者是nginx的conf配置相关
5.相关问题
问题1: 请详细描述三次握手和四次挥手的过程,并画出状态图
问题2: 四次挥手中TIME_WAIT状态存在的目的是什么?
问题3: TCP是通过什么机制保障可靠性的?
2.问题回答
问题1:
状态图如下

补充知识:TCP报文中共计6个标志位,每个标志位占1个字节,即URG、ACK、PSH、RST、SYN、FIN等
- URG:紧急指针(urgent pointer)有效。
- ACK:确认序号有效。
- PSH:接收方应该尽快将这个报文交给应用层。
- RST:重置连接。
- SYN:发起一个新连接。
- FIN:释放一个连接。
三次握手详情
- 第一次握手:Client将标志位SYN置为1,随机产生一个值seq=a,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认
- 第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将SYN和ACK都置为1,ack=a+1,随机产生一个值seq=b,并将该数据包发送给Client以确认连接,Server进入SYN_RCVD状态
- 第三次握手:Client收到确认后,检查ack是否为b+1,ACK是否为1,如果,正确则将标志位ACK置为1,ack=b+1,并将该数据包发送给Server,Server检查ack是否为b+1,ACK是否为1,如果正确,则连接成功,client和server进入ESTABLISHED状态,完成三次握手,随后client和server端可以开始通信
四次挥手详情(被动关闭)
- 第一次挥手:Client发送一个FIN,随机产生一个seq=a,用来关闭client到server端的数据传送,client进入FIN_WAIT状态
- 第二次挥手:Server收到FIN后,发送一个ACK给Client,ack=a+1,Server进入CLOSE_WAIT状态
- 第三次挥手:Server收到一个FIN,随机产生一个值seq=b,用来关闭Server到Client的数据发送,同时发送ACK标志位,ack=a+1,Server进入LAST_ACK状态
- 第四次挥手:Client,收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,ack=b+1,Server进入CLOSED状态,完成四次挥手
补充1:
SYN攻击:在三次握手过程中,Server发送SYN-ACK之后,收到Client的ACK之前的TCP连接称为半连接(half-open connect),此时Server处于SYN_RCVD状态,当收到ACK后,Server转入ESTABLISHED状态。SYN攻击就是Client在短时间内伪造大量不存在的IP地址,并向Server不断地发送SYN包,Server回复确认包,并等待Client的确认,由于源地址是不存在的,因此,Server需要不断重发直至超时,这些伪造的SYN包将产时间占用未连接队列,导致正常的SYN请求因为队列满而被丢弃,从而引起网络堵塞甚至系统瘫痪。SYN攻击时一种典型的DDOS攻击,检测SYN攻击的方式非常简单,即当Server上有大量半连接状态且源IP地址是随机的,则可以断定遭到SYN攻击了,使用如下命令可以让之现行:
#netstat -nap | grep SYN_RECV
补充2:
四次挥手的同时关闭状况:实际中还会出现同时发起主动关闭的情况,具体流程如下图

问题2:
在四次挥手中,第三次挥手结束后,Client端进入TIME_WAIT状态,客户端不会马上进入closed状态,理由如下
- 等待2MSL时间段,确保Client端发送的FIN报文,Server端可以接收,如果Server端没有收到第四次挥手,则会对Client端重发第三次挥手,确保Client可以正确关闭,如果没有进入TIME_WAIT状态,则Client端就无法接收Server端的发来的报文。简略:确保客户端正确关闭。
- 一个连接结束,网络内路由或者是网络包还会继续保留一段时间,在tcp连接结束后,在旧TCP连接对应的网络包消失之前,才允许建立新的TCP连接。简略:在新的TCP建立之前,确保旧的TCP链接对应的网络包正确的结束。
问题3:
TCP传输的可靠性主要靠以下手段来保证传输
- ACK确认机制:简单的说就是发送随机生成一个数字,接收端在确认收到数据,提取随机数并加1,返回发送端,告知确认收到数据包,同时也保证数据接收的唯一性
- 超时重传:发送方在一定时间内未收到对方的回传的ack确认码,则将数据重新发送,保证数据传输的一致性
- 滑动窗口:看补充
- 流量控制:看补充
建议:滑动窗口与流量控制视情况是否说明
补充:滑动窗口与流量控制
1).滑动窗口:
“窗口”对应的是一段可以被发送者发送的字节序列,其连续的范围称之为“窗口”;
“滑动”则是指这段“允许发送的范围”是可以随着发送的过程而变化的,方式就是按顺序“滑动”。
- TCP协议的两端分别为发送者A和接收者B,由于是全双工协议,因此A和B应该分别维护着一个独立的发送缓冲区和接收缓冲区,由于对等性(A发B收和B发A收),我们以A发送B接收的情况作为例子;
- 发送窗口是发送缓存中的一部分,是可以被TCP协议发送的那部分,其实应用层需要发送的所有数据都被放进了发送者的发送缓冲区;
- 发送窗口中相关的有四个概念:已发送并收到确认的数据(不再发送窗口和发送缓冲区之内)、已发送但未收到确认的数据(位于发送窗口之中)、允许发送但尚未发送的数据以及发送窗口外发送缓冲区内暂时不允许发送的数据;
- 每次成功发送数据之后,发送窗口就会在发送缓冲区中按顺序移动,将新的数据包含到窗口中准备发送;
案例如下:
TCP建立连接的初始,B会告诉A自己的接收窗口大小,比如为‘20’:
字节31-50为发送窗口

A发送11个字节后,发送窗口位置不变,B接收到了乱序的数据分组:

只有当A成功发送了数据,即发送的数据得到了B的确认之后,才会移动滑动窗口离开已发送的数据;同时B则确认连续的数据分组,对于乱序的分组则先接收下来,避免网络重复传递:

2).流量控制
流量控制方面主要有两个要点需要掌握。一是TCP利用滑动窗口实现流量控制的机制;二是如何考虑流量控制中的传输效率。
\1. 流量控制
所谓流量控制,主要是接收方传递信息给发送方,使其不要发送数据太快,是一种端到端的控制。主要的方式就是返回的ACK中会包含自己的接收窗口的大小,并且利用大小来控制发送方的数据发送,案例如图:

这里面涉及到一种情况,如果B已经告诉A自己的缓冲区已满,于是A停止发送数据;等待一段时间后,B的缓冲区出现了富余,于是给A发送报文告诉A我的rwnd大小为400,但是这个报文不幸丢失了,于是就出现A等待B的通知||B等待A发送数据的死锁状态。为了处理这种问题,TCP引入了持续计时器(Persistence timer),当A收到对方的零窗口通知时,就启用该计时器,时间到则发送一个1字节的探测报文,对方会在此时回应自身的接收窗口大小,如果结果仍未0,则重设持续计时器,继续等待。
\2. 传递效率
一个显而易见的问题是:单个发送字节单个确认,和窗口有一个空余即通知发送方发送一个字节,无疑增加了网络中的许多不必要的报文(请想想为了一个字节数据而添加的40字节头部吧!),所以我们的原则是尽可能一次多发送几个字节,或者窗口空余较多的时候通知发送方一次发送多个字节。对于前者我们广泛使用Nagle算法,即:
- 若发送应用进程要把发送的数据逐个字节地送到TCP的发送缓存,则发送方就把第一个数据字节先发送出去,把后面的字节先缓存起来;
- 当发送方收到第一个字节的确认后(也得到了网络情况和对方的接收窗口大小),再把缓冲区的剩余字节组成合适大小的报文发送出去;
当到达的数据已达到发送窗口大小的一半或以达到报文段的最大长度时,就立即发送一个报文段;
对于后者我们往往的做法是让接收方等待一段时间,或者接收方获得足够的空间容纳一个报文段或者等到接受缓存有一半空闲的时候,再通知发送方发送数据。
所属网站分类: 技术文章 > 博客
作者:忘也不能忘
链接:https://www.pythonheidong.com/blog/article/3822/6e326e98504c3bd315c9/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力