

【深度学习】语义分割 NYUv2 数据集
发布于2019-08-17 21:35 阅读(4955) 评论(0) 点赞(3) 收藏(5)
数据集下载
去到NYU Depth V2[1] 官网下载数据集,如下图所示。这里我们只是用RGB数据,不使用RGB-D数据(带深度信息),所以只需要下载Labeled dataset (~2.8 GB)即可。此外还需要下载划分训练/测试数据集的文件:Train / Test Split

数据集的转换
概述
NYUv2一共提供了1449张RGB图像和和894个类别标注。在有些研究工作中,如[2][3],仅使用40个语义类别进行训练和评估,通常称之为NYUv2-40。模型训练中一般使用标准划分:795和654分别用于训练和测试。原始数据集使用.mat格式,我们需要将相应的数据提取出来。
下面会详细讲解如何提取,以及得到NYUv2-40的标注。
点击这里下载笔者搜集的资源和实现的转换脚本。解压后的目录结构如下:
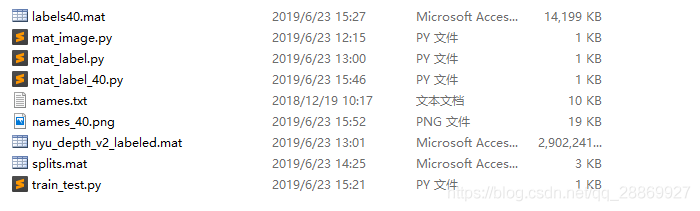
***注意:***
1. train_test.py中第16行,'.png'应该改为'.jpg'
2. mat_label_40.py中第28行,‘str('%06d'%(i+1))’改为'str(i)'
提取RGB图像和标注
首先,从nyu_depth_v2_labeled.mat(即上文中官网下载的标注数据)中提取到RGB图像和.png标注图像。运行:
python mat_image.py
python mat_label.py
- 1
- 2
脚本会自动在同级目录下生成nyu_images和nyu_labels两个文件夹,分别用于存放提取出来的RGB图像和.png灰度标注。
数据集划分
官网下载到的数据集划分文件splits.mat也需要转换为对应的train.txt和test.txt,运行脚本:
python train_test.py
- 1
脚本将自动创建train.txt和test.txt,分别对应训练集和测试集的图像id。现在目录结构如下:
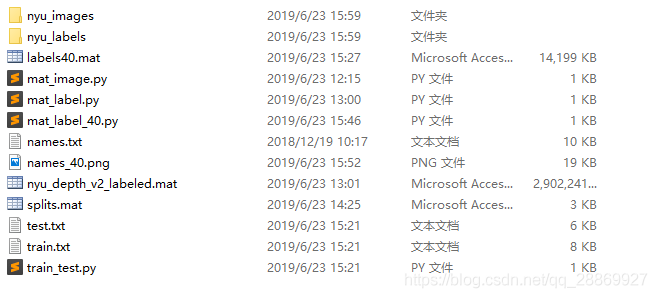
到这里,标准的NYUv2数据集就制作好了。语义分割中常使用RGB图像,并不使用其中的深度信息,所以这里并未提取RGB-D图像。
NYUv2-40制作
文件夹中names.txt表示原始NYUv2数据集的类别,names_40.png表示NYUv2-40中使用的语义类别。
接下来需要将NYUv2-40的语义类别标注从labels40.mat提取出来,运行:
python mat_label_40.py
- 1
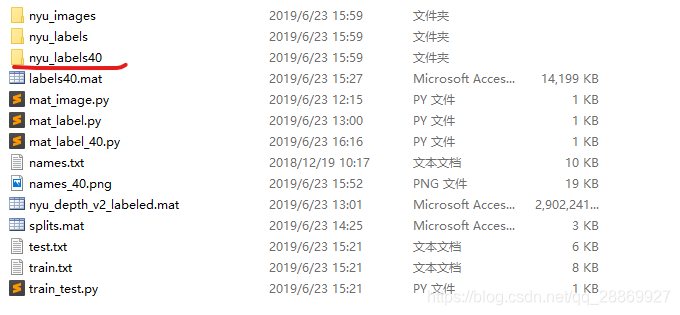
如下图,结果存放在生成的nyu_lables40文件夹中。
参考文献
[1] N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. Indoor segmentation and support inference from rgbd images. In Proceedings of the European Conference on Computer Vision, 2012.
[2] S. Gupta, P. Arbelaez, and J. Malik. Perceptual organization and recognition of indoor scenes from rgb-d images. In Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013.
[3] Lin G, Milan A, Shen C, et al. RefineNet: Multi-path Refinement Networks for High-Resolution Semantic Segmentation. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017.
所属网站分类: 技术文章 > 博客
作者:comeonbady
链接:https://www.pythonheidong.com/blog/article/48462/93daaf45b1f815ec6412/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力