

GB2312编码下全角转半角的Python实现
发布于2019-08-20 11:04 阅读(1312) 评论(0) 点赞(22) 收藏(3)
运行环境
- python3.7
实现思路:
gb2312在文件中的二进制使用的机内码,这里需要区分一下区位码和机内码(这里忽略了国标码的介绍,感兴趣的可以去百度一下)。
- 区位码是gb2312表上每一个字符对应的位置的编码,gb2312将字符集分成了94个区,一个区内又有94个字符,区内码=区号(2位) 区内位置(2位)。
- 机内码则是gb2312在机器内的表示,机内码=区位码+0xA0A0H。
由此我们也可以知道gb2312的编码范围为0xA1A1-0xFEFE
因此接下的事情就是每两个字符判断一下它们的取值范围,如果满足则说明是gb2312编码
这里再说一下全角字符和半角字符的区别,在gb2312中,全角字符占2个字节,而半角字符只占1个字节,对于第三区位的字符来说,半角字符的值=全角字符的第二个字节-0x80H。至于为什么是减掉80H,是因为为了兼容原先的ASCII码,ASCII的范围为0~127(十进制),因此减掉80H的半角字符即为对应的ASCII编码值。
第三区位的区位表
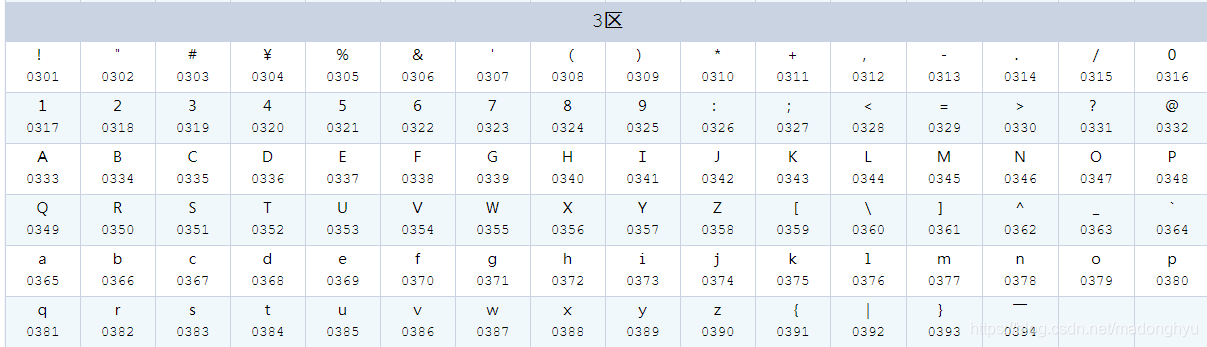
下面是实现的代码,这里注意的是转化的全角仅仅包括字母和数字,下面的代码仅适用与编码为gb2312的文件。
def f2b(contents: bytes):
r = bytearray()
skip = False
for i in range(len(contents) - 1):
if skip:
skip = False
continue
t1 = contents[i]
t2 = contents[i + 1]
skip = True
# 两个字节都添加,则要跳过下一个字节
if t1 == 0xA3 and (0xB0 <= t2 <= 0xB9 or 0xC1 <= t2 <= 0xDA or 0xE1 <= t2 <= 0xFA):
r.append(t2 - 0x80)
# 空格
elif 0xA1 == t1 and 0xA1 == t2:
r.append(0x20)
# 忽略ascii
elif t1 <= 127:
r.append(t1)
skip = False
else:
r.append(t1)
r.append(t2)
# 补充末尾,如果最后没有跳过字符的话
if not skip:
r.append(contents[-1])
return r
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
所属网站分类: 技术文章 > 博客
作者:dfjdhfjdf
链接:https://www.pythonheidong.com/blog/article/49066/c96b99809909e3725564/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力