

夏令营7.29--爬虫之正则表达式
发布于2019-08-20 12:59 阅读(611) 评论(0) 点赞(25) 收藏(1)
正则匹配:
正则表达式:是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配,
定义了一种规则,匹配出所有符合这个规则的字符。
大概分三点:
01:正则匹配字符
02:看懂复杂的正则表达式
03:python中的re库
1:
正则匹配常见字符:
^:匹配一行字符串的开头
. : 匹配任意字符,除了换行符
[…]:匹配括号中的任一个,[amk] 匹配
‘a’,‘m’或’k’
[^…]: 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符
*:匹配0个或多个的表达式
+:匹配1个或多个的表达式
?:匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式
|:a| b,匹配a或b
{n}:精确匹配 n 个前面表达式。例如, o{2} 不能匹配 “Bob” 中的 “o”,但是能匹配 “food” 中的两个 o。
{n,}:匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。
“o{1,}” 等价于 “o+”。“o{0,}” 则等价于 “o*”。
{ n, m}:匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式
\w:匹配字母数字下划线
\W:匹配非字母数字下划线
\s:匹配任意空白字符
\S:匹配任意非空白字符
\d: 匹配任意数字,等价于 [0-9]
\D:匹配任意非数字
2:
读懂复杂的正则表达式:
读懂复杂的正则表达式:
例题:字符?正则?
基本思路:拆分->各个击破
解释:
先将一个,很长的,很复杂的正则表达式,从左向右,一点点读取,分析,一点找到某部分的内容,是一个逻辑概念上的独立的一块,就暂时拆分出来,如此,一点点把复杂的正则表达式,拆分成很多个逻辑上独立的小块。
然后针对每个小块的表达式,再去分析其含义,每个小块的正则表达式都搞懂后,把和所有的含义,合并出一个整体的含义,最后就可以实现,用人类的语言,把对应的复杂的正则表达式,一点点解释出来了,
即:把之前看不懂的,复杂的正则表达式,翻译成,通俗易懂的自然语言,,不过最主要的是自己看懂:
3:
re库:re 模块使 Python 语言拥有全部的正则表达式功能
常用方法:
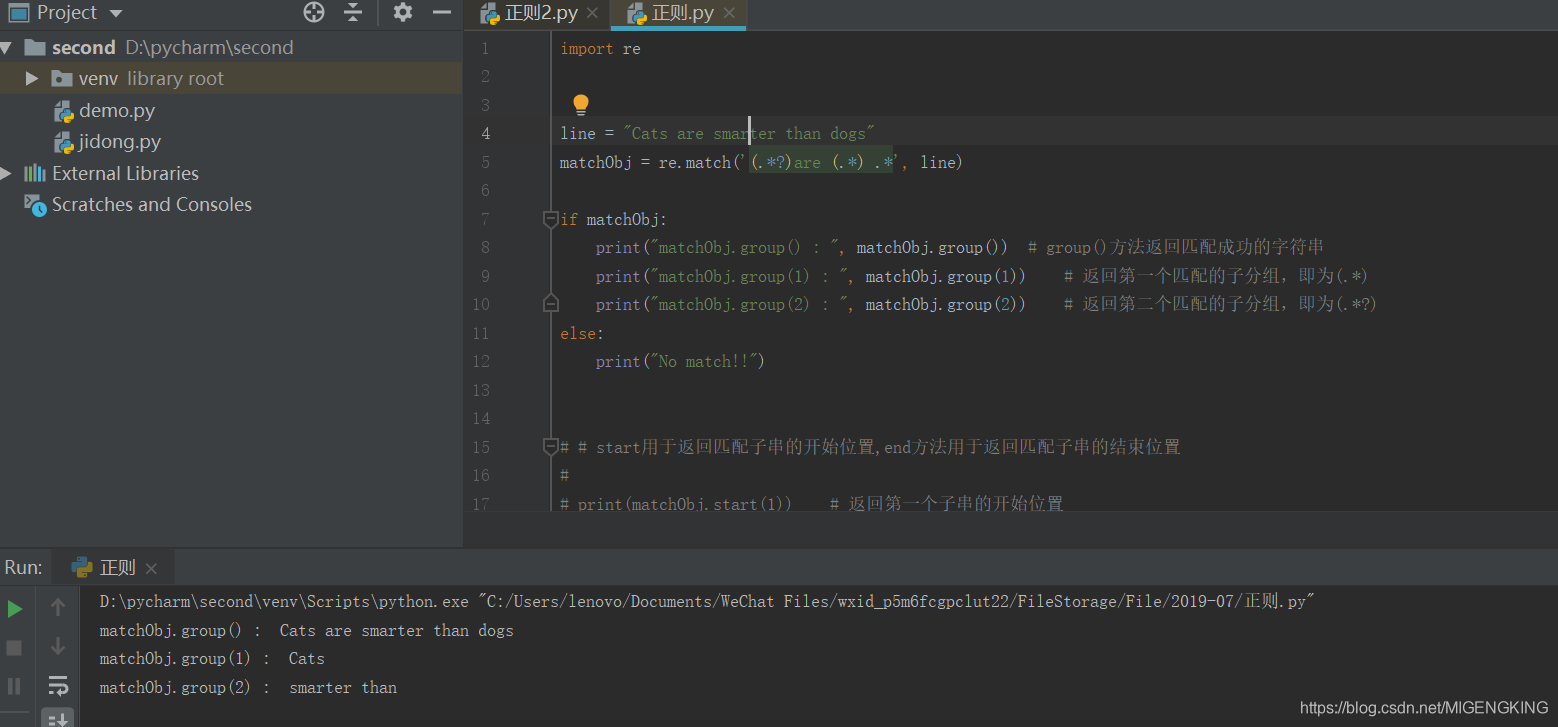
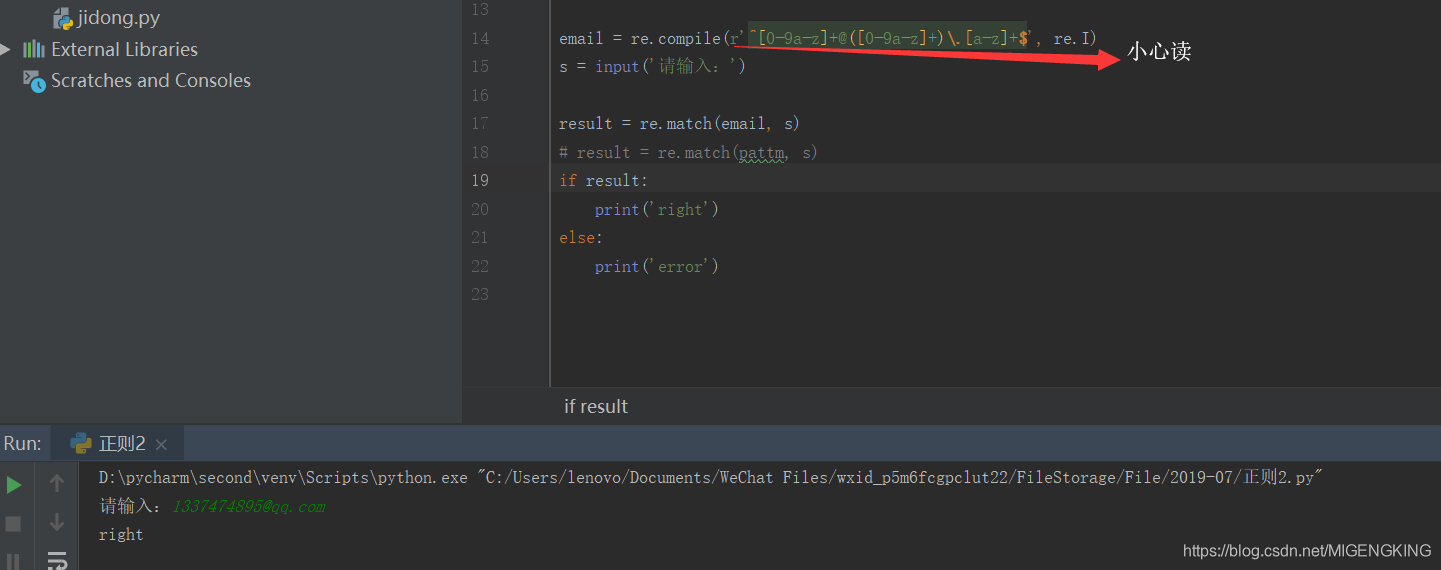
re.match :尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回none。第一个参数传入了正则表达式,第二个参数传入了要匹配的字符串。
re.search:扫描整个字符串并返回第一个成功的匹配。
span():获取开始和结束位置;string:获取匹配的内容
group():获取子表达式匹配的内容
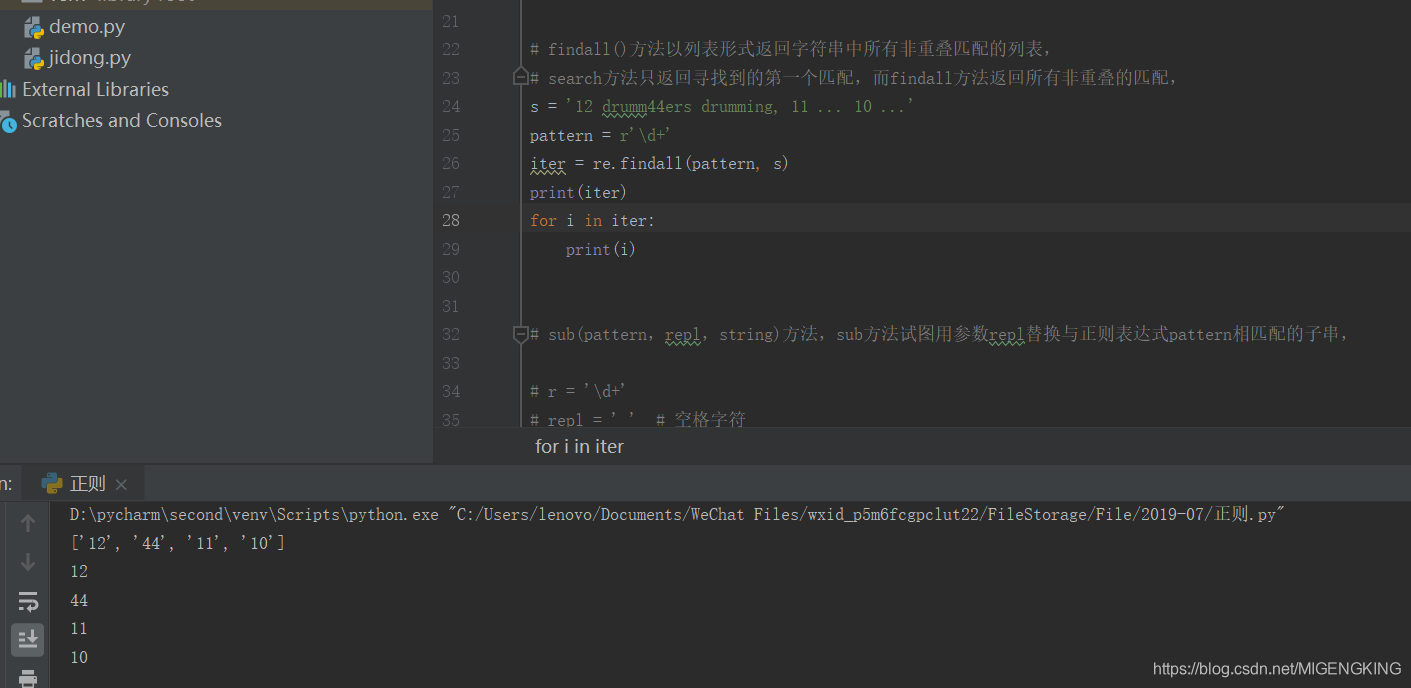
re.findall:在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
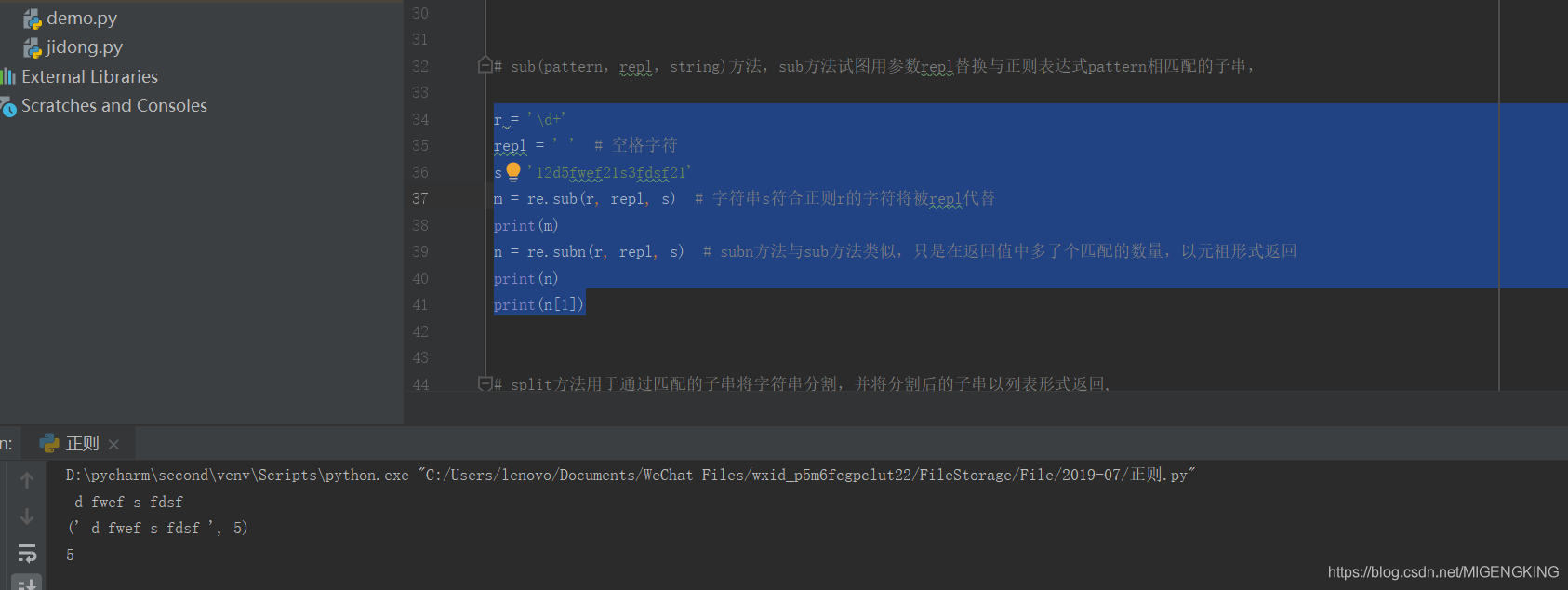
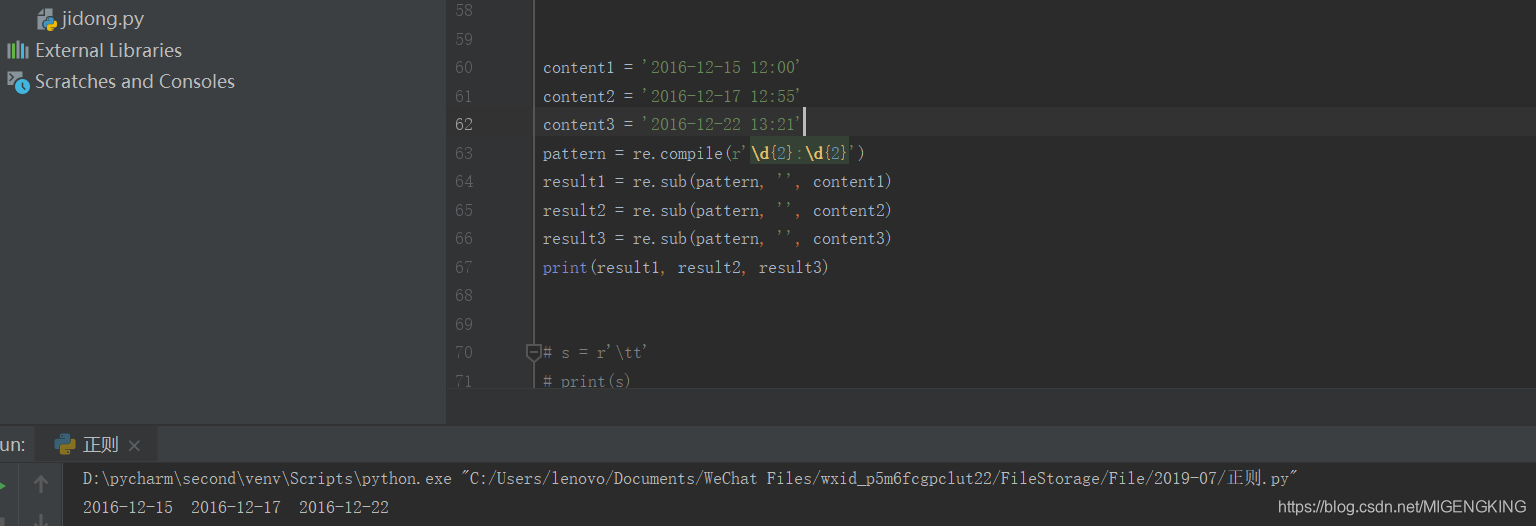
re.sub(‘表达式’, ‘新字符’, ‘字符串’):用于替换字符串中的匹配项。
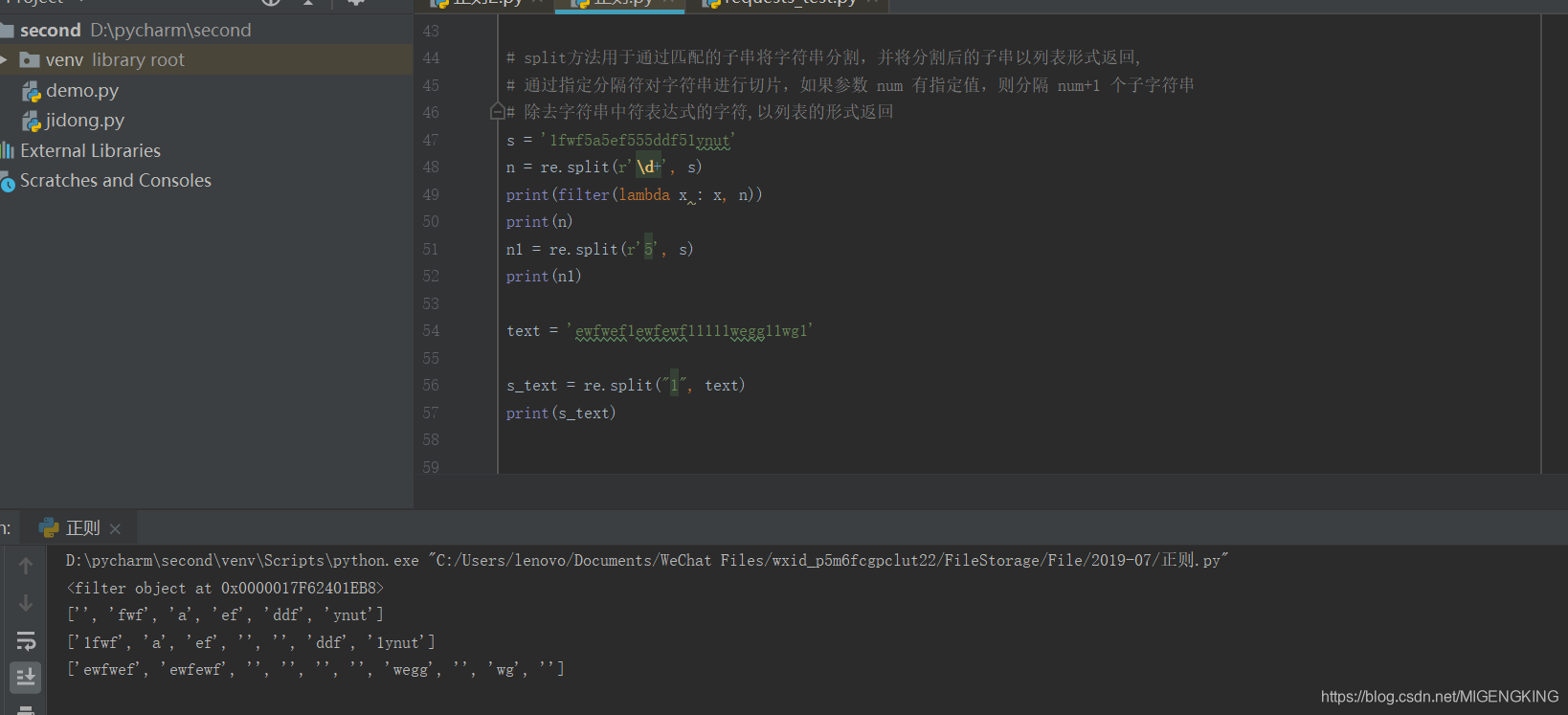
re.split:方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
re.compile:函数用于编译正则表达式,生成一个正则表达式对象
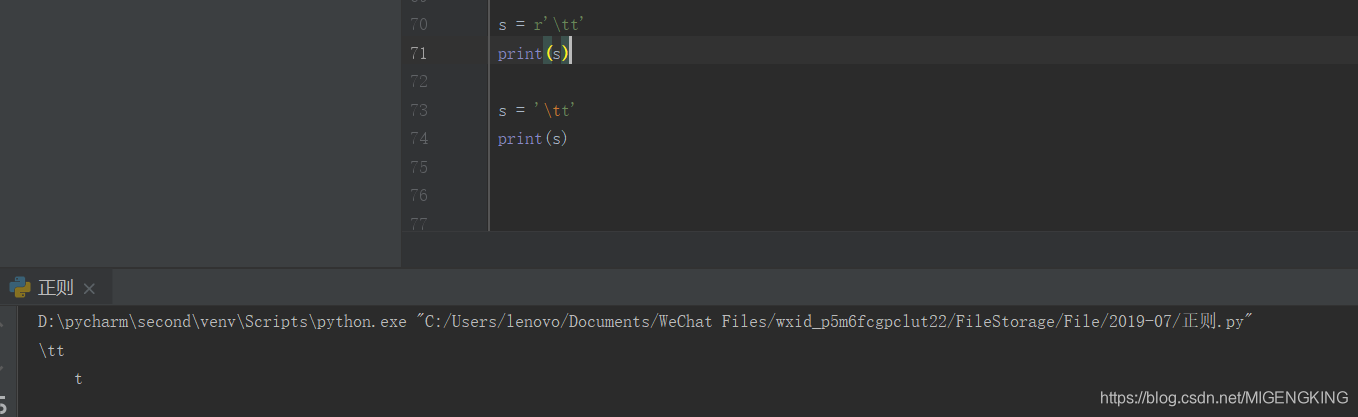
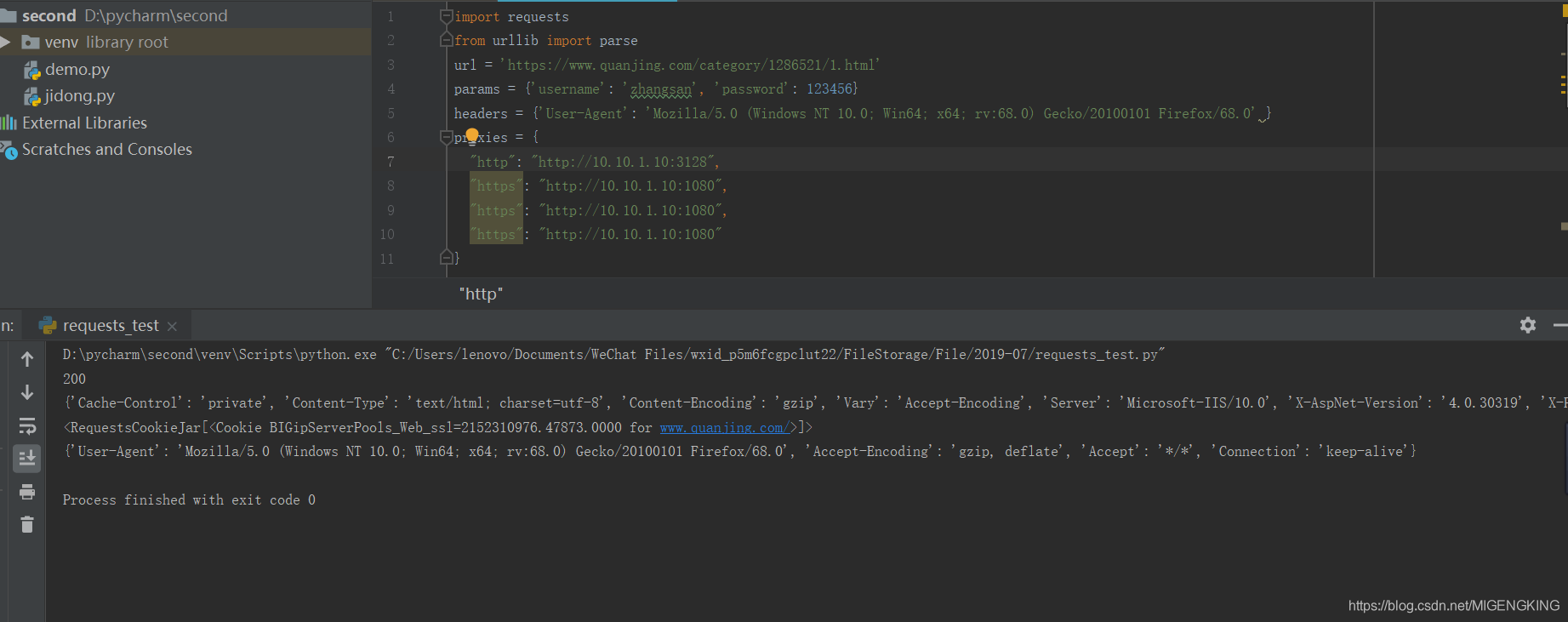
实例:
所属网站分类: 技术文章 > 博客
作者:085iitirtu
链接:https://www.pythonheidong.com/blog/article/49344/18e2230b2f4ce190db51/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力