

bert 原理及源码分析(一)
发布于2019-08-20 13:47 阅读(1837) 评论(0) 点赞(9) 收藏(1)
全称:Bidirectional Encoder Representations from Transformers,即双向 transformer的encoder 表示。
bert 的结构图
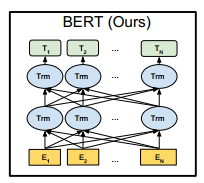
中间的神经网络为 transformer。
Embedding
embedding 由 3 种 embedding 求和而成:

Token Embeddings:词向量
Segment Embeddings:句向量
Position Embeddings:位置向量
Pre-training
Pre-training Task 1:Masked LM
俗称完形填空任务。利用上下文信息预测出缺失的单词,是不是和 word2vec 中的 CBOW 很像?在训练过程中速记 mask 15 % 的 token,最终的损失函数只计算被 mask 掉的那个 token。
随机 mask 的时候 10% 的单词会被替代成其他单词,10% 的打车你不提换,80%的单词1被替换成 [MASK]。
- 该任务的目的是什么?
充分利用上下文信息。因为单项预测不能理解整个句子的语义。捕捉词语级别的表示 - 为什么会有10%,10%,80% 的替代情况而不是全部用 mask 替代?
全部用 mask替代的话,模型会将 mask 当作一个固定的词,这不是我们想要的。
Pre-traing Task 2:Next Sentence Prediction
训练的输入是 句子 A 和 B,B 有一半的几率是 A 的下一句,模型预测 B 是不是 A 的下一句。
- 该任务的目的是什么?
捕捉句子级别的表示。可以应用在问答或阅读理解上,效果奇佳。
Fine-tuning
在 pre-training 的基础上
分类:直接取第一个 token(即 CLS) 的 hidden-state C,对其进行一个线性变换,再经过 softmax 转换得到 label probability。
文本匹配:输出为 label: [0,1] (是否匹配),输入为 待匹配的两个文本 text_a 和 text_b。
还可以用于标注、问答等任务上。
源码分析
相关代码如下:
create_pretraining_data.py
extract_features.py
modeling.py
modeling_test.py
optimization.py
optimization_test.py
run_classifier.py
run_classifier_with_tfhub.py
run_pretraining.py
run_squad.py
tokenization.py
tokenization_test.py
tokenization.py
功能:对原始文本进行预处理,分词。
主要分为 BasicTokenizer.py 和 WordpieceTokenizer 两类,以及对包含它们的类 FullTokenizer:作为对外的接口。
BasicTokenizer 中的函数:
tokenize(): 对文本进行一些预处理后再进行分词为主函数,一下皆为其子函数。对于中文来说,最后返回的是字列表。
_run_strip_accents(): 去掉文本中的重音
_run_split_on_punc(): 对文本按标点符号进行分割,标点符号不去除,作为单独的元素存进 list 中
_tokenize_chinese_chars(): 按字切分中文,在字两侧添加空格
_is_chinese_char(): 判断是否为汉字
_clean_text():去除无意义字符
WordpieceTokenizer:
在 BasicTokenizer 的基础上对单词进行更细粒度的划分。比如:
input = “unaffable”
output = [“un”, “##aff”, “##able”]
由于对中文无影响(因为中文最细粒度就是字),所以不再赘述。
FullTokenizer:
Tokenize(): 先进行 basic_tokenizer.tokenize(text),在其基础上再进行 wordpiece_tokenizer.tokenize(token)
convert_tokens_to_ids(): 将词转为 id
convert_ids_to_tokens(): 将 id 转为词
在类之外的函数:
validate_case_matches_checkpoint(do_lower_case, init_checkpoint): 检查包装配置(配置的名称)是否与检查点一致
convert_to_unicode(text): 将文本转化成 unicode 形式
printable_text(text): 将文本以合适的方式返回(unicode string 或 byte string)
load_vocab(vocab_file): 加载词典
convert_by_vocab(vocab, items): 用于 id 与 token 的转换
whitespace_tokenize(text): 去除首尾的空格并按空格进行分词
create_pretraining_data.py
功能:产生预训练数据,即将原始语料转换成模型与训练所需要的数据格式 TFRecord
python create_pretraining_data.py \
--input_file=./sample_text.txt \
--output_file=/tmp/tf_examples.tfrecord \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--do_lower_case=True \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--masked_lm_prob=0.15 \
--random_seed=12345 \
--dupe_factor=5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
参数解释:
input_file: 输入文件–sample_text.txt
output_file: 输出文件–/tmp/tf_examples.tfrecord
vocab_file:词典
do_lower_case:是否忽略大小写,true 忽略
max_seq_length:每条训练数据(两句话)的最大长度
max_predictions_per_seq:每条训练数据 mask 的最大数量
random_seed:一个随机种子
dupe_factor:dupe 的意思为复制,参数含义为可随机设置 MASK 的次数。比如,对于,hello,how are you?dupe_factor 的次数为 2,那么可能的一种结果为
[Mask] ,how are you?
hello,[Mask] are you?
masked_lm_prob:一条训练数据产生 mask 的概率
short_seq_prob:以此概率产生小于 max_seq_length 的训练数据
一个类: TrainingInstance
类中的函数:
__str__():
__repr__():
write_instance_to_example_files():以 TFRecord 格式保存数据
create_int_feature():
create_float_feature()
create_training_instances(): 构造训练 instances
create_instances_from_document():从一个文档抽取多个训练样本,将数据标记化处理,加入 [MASK] 及分句标识 [CLS][SEP]
create_masked_lm_predictions()
truncate_seq_pair()
先来看一看 main() 函数的逻辑:
先调用 tokenization.FullTokenizer() 对本文进行预处理,分词;
然后调用 create_training_instances() 产生一些实例
最后调用 write_instance_to_example_files():将产生的实例写进文件
create_instances_from_document
从文档 document 中生成 A,B 两个句子 tokens_a, tokens_b,先将 document 中的所有段落拼接在一起,存在 current_chunk 中,然后随机生成句子 A 的结尾位置 a_end = rng.randint(1,len(current_chunk) - 1);再来生成 B。
有两种情况:1. i == len(document) - 1;2. current_length >= target_seq_length。
对于情况 1,文档遍历结束,current_chunk 包含文档中所有 segment,则随即设定一个中间值 a_end,将document 分为 A 和 B。
对于情况 2,文档未遍历完,但当前长度 current_length 已大于或等于 最大长度 target_seq_length,则按照和 1 同样的方法生成 A 和 B,只是声称 A 和 B 之后并未遍历完 document,所以还得继续重复之前的过程,生成新的 A 和 B
B 的生成又分为两种情况:
若 len(current_chunk) == 1,则当前文档无法再生成 B,随机挑一篇文档来生成 B;否则,当前文档 current_chunk - tokens_a = tokens_b。
tokens_a 和 tokens_b 的最终格式为:[CLS] A [SEP] B [SEP].
对应的 segment_ids 为 0 和 1 的组合 :000…111,可以区分句子 A,B, 最后一个 0 对应中间的 [SEP]
在生成 instance 之前要先调用 create_masked_lm_predictions() 对句子进行 mask。
代码如下,在一些地方加了注释:
def create_instances_from_document(
all_documents, document_index, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng):
document = all_documents[document_index]
# 为 [CLS], [SEP], [SEP] 留下 3 个空间
max_num_tokens = max_seq_length - 3
target_seq_length = max_num_tokens
if rng.random() < short_seq_prob:
target_seq_length = rng.randint(2, max_num_tokens)
instances = [] # 存储instance
current_chunk = [] # 当前已存储的 document 中的每个 segment(mege segment 由多个 segment 组成)
current_length = 0 # current_chunk 中的所有 token的个数
i = 0 # 用来遍历 document 的索引
while i < len(document):
segment = document[i]
current_chunk.append(segment)
current_length += len(segment)
if i == len(document) - 1 or current_length >= target_seq_length:
if current_chunk:
a_end = 1 # 句子 A 的结尾
if len(current_chunk) >= 2:
a_end = rng.randint(1, len(current_chunk) - 1)
tokens_a = []
for j in range(a_end):
tokens_a.extend(current_chunk[j])
tokens_b = []
# Random next
is_random_next = False # 是否随机生成句子 b
# 0.5 说明有一半的可能随机,一半的可能不随机产生下句 B
if len(current_chunk) == 1 or rng.random() < 0.5:
# len(current_chunk) == 1 则当前文档只能生成 A 而无法生成 B
# rng.random() < 0.5 则是强制从另一篇文档中生成 B
is_random_next = True
target_b_length = target_seq_length - len(tokens_a)
for _ in range(10): #要保证另一篇文档不是当前文档
random_document_index = rng.randint(0, len(all_documents) - 1)
if random_document_index != document_index:
break
random_document = all_documents[random_document_index]
random_start = rng.randint(0, len(random_document) - 1)
for j in range(random_start, len(random_document)):
tokens_b.extend(random_document[j])
if len(tokens_b) >= target_b_length:
break
# 假设 遍历到 i 的时候,current_chunk 的长度超过最大限度,则从当前文档生成句子 A 和 从另一篇文档中生成 B 后 ,
当前文档 current_chunk还剩下一部分,本来时留给 B 的,但 B 从其他地方生成了,所以为了不浪费,产生了这段代码。
num_unused_segments = len(current_chunk) - a_end
i -= num_unused_segments
# Actual next
else:
is_random_next = False
for j in range(a_end, len(current_chunk)):
tokens_b.extend(current_chunk[j])
truncate_seq_pair(tokens_a, tokens_b, max_num_tokens, rng)
assert len(tokens_a) >= 1
assert len(tokens_b) >= 1
tokens = []
segment_ids = []
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
tokens.append("[SEP]")
segment_ids.append(1)
(tokens, masked_lm_positions,
masked_lm_labels) = create_masked_lm_predictions(
tokens, masked_lm_prob, max_predictions_per_seq, vocab_words, rng)
instance = TrainingInstance(
tokens=tokens,
segment_ids=segment_ids,
is_random_next=is_random_next,
masked_lm_positions=masked_lm_positions,
masked_lm_labels=masked_lm_labels)
# 如果是因为 current_length >= target_seq_length,instance 就不止一个
instances.append(instance)
current_chunk = []
current_length = 0
i += 1
return instances
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
** create_masked_lm_predictions()**
对 tokens 进行 mask,
输入序列中 15% 的词会被替换掉,这些词有 80% 的概率用 [MASK] 替换,10% 的概率随即替换,10% 的概率不进行替换。
masked_lm_positions: 序列里被 [MASK] 的位置
masked_lm_labels: 序列里被 [MASK] 的 token,转换为 id 形式即为 masked_lm_ids
create_training_instances()
该函数很简单,调用 create_instances_from_document() 随机生成一些例子 instances 返回,相关代码就不贴了。
write_instance_to_example_files()
将instances 保存为TFRecord 格式。
未完待续。。。
参考文献:
[1] https://zhuanlan.zhihu.com/p/53099098
[2] [BERT源码分析PART II
[3] BERT源码分析PART I
所属网站分类: 技术文章 > 博客
作者:滴水
链接:https://www.pythonheidong.com/blog/article/49397/87ffeaa9b55a7ab4199b/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力