

爬虫初尝试 | 易车网文章url爬取
发布于2019-08-22 15:54 阅读(647) 评论(0) 点赞(12) 收藏(3)
目标网站:news.bitauto.com/
由于推荐页的加载更多不方便操作
选择单项页面爬取 例如新车页
在页面右键选择 检查
找到目标位置
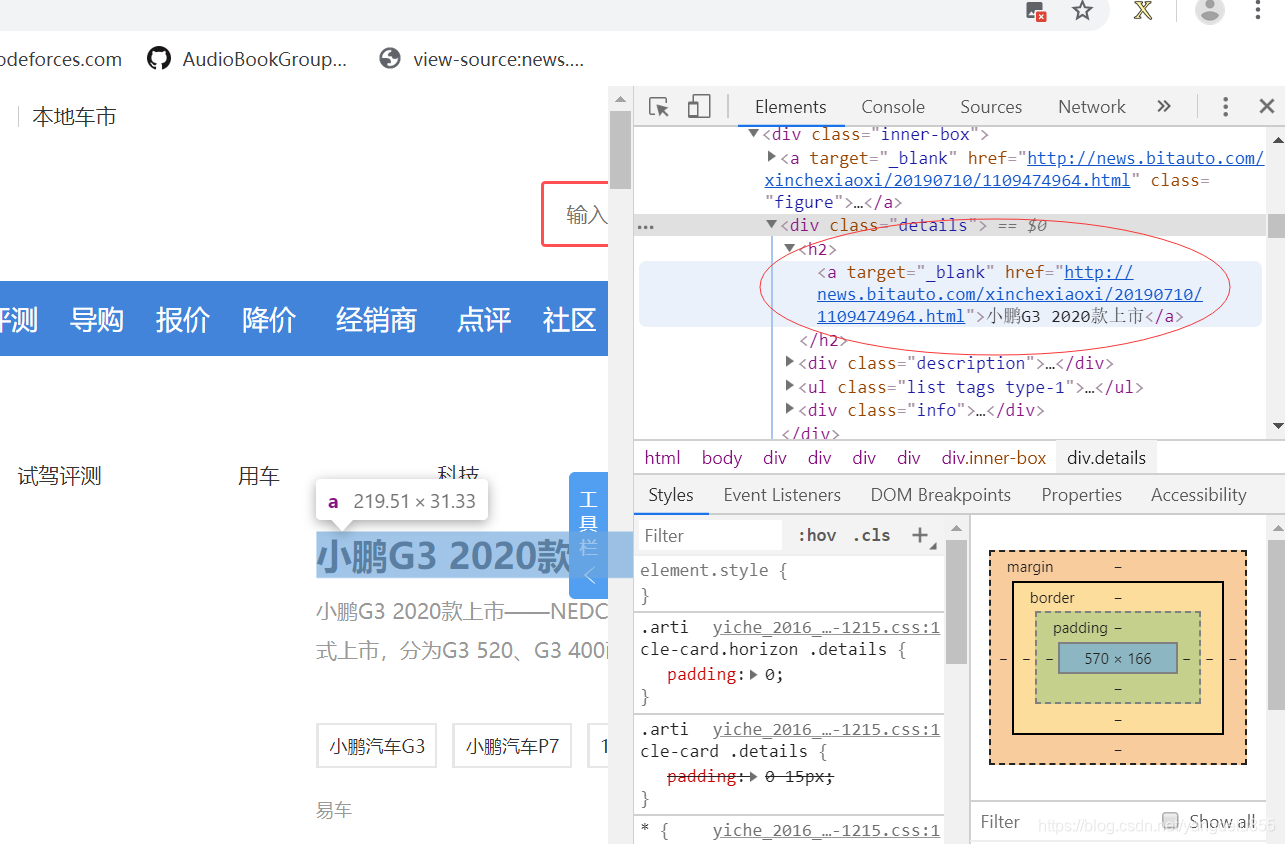
/html/body/div[3]/div/div[1]/div[3]/div/div/h2/a (推荐使用Xpath helper 可以直接复制Xpath)
- #coding: utf8
- from selenium import webdriver
- f=open("url6.txt","w",encoding="utf-8")
- fw = open("news.txt", "w", encoding="utf-8")
- driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver')
-
-
- def geturl(url,k):
- driver.get(url)
- urls = driver.find_elements_by_xpath('//div[@class="article-card horizon"]//a') #目标url存在于多个位置 可以选一个方便找到的
- url_list=[]
- for url in urls:
- u = url.get_attribute('href')
- if u == 'None':
- continue
- else:
- url_list.append(str(url.get_attribute("href")))
- url_list=list(set(url_list))
- #print(url_list)
- for new_url in url_list:
- if(len(new_url)<2):
- continue
- if(new_url[-1]=='l'):
- print(new_url)
- f.write(new_url+"\n")
- #
- if __name__ == '__main__':
- #url= 'http://news.bitauto.com/xinche/'
- a_list=[("xinche",4786)]
- for t,am in a_list:
- url = "http://news.bitauto.com/" + t + "/?pageindex="
- k=len(t)
- for i in range(1, am):
- new_url = url + str(i)
- print(t," page:", i)
- geturl(new_url,k)
- f.close()
- driver.close()
所属网站分类: 技术文章 > 博客
作者:085iitirtu
链接:https://www.pythonheidong.com/blog/article/52643/d2e6065c674bd4b92114/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力