

十、python计算机视觉编程之OPENCV
发布于2019-08-22 16:29 阅读(2622) 评论(0) 点赞(20) 收藏(3)
(一)OpenCV 的 Python 接口
OpenCV 是一个C++ 库,它包含了计算机视觉领域的很多模块。除了 C++ 和 C, Python 作为一种简洁的脚本语言,在 C++ 代码基础上的 Python 接口得到了越来越广泛的支持。
可以通过以下方式进行导入:
import cv2
- 1
安装opencv工具包需要在Anaconda Prompt中输入以下的命令即可:
pip install opencv-python
(二)OpenCV 基础知识
OpenCV自带读取、写入图像函数以及矩阵操作和数学库。
(1)读取和写入图像
载入一张图像,打印出图像大小,对图像进行转换并保存为.png 格式,编写实验代码:
# -*- coding: utf-8 -*-
import cv2
# 读取图像
im = cv2.imread('alcatraz1.jpg')
h,w = im.shape[:2]
print (h,w)
# 保存图像
cv2.imwrite('alcatraz1.png',im)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
实验结果:


函数 imread() 返回图像为一个标准的 NumPy 数组,并且该函数能够处理很多不同格式的图像。
将其他类型的图像转换并保存为.jpg格式,编写实验代码:
# -*- coding: utf-8 -*-
import cv2
# 读取图像
im = cv2.imread('C-uniform01.ppm')
h,w = im.shape[:2]
print (h,w)
# 保存图像
cv2.imwrite('C-uniform01.jpg',im)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
实验结果:

(2)颜色空间
在 OpenCV 中,图像不是按传统的 RGB 颜色通道,而是按 BGR 顺序(即 RGB 的倒序)存储的。读取图像时默认的是 BGR,但是还有一些可用的转换函数。颜色空间转换可以用函数cvtColor()来实现。
在读取原图像之后,紧接其后的是 OpenCV 颜色转换代码,其中最有用的一些转换代码如下所示:
- cv2.COLOR_BGR2GRAY (原图像转化为灰度图像)
- cv2.COLOR_BGR2RGB (原图像转化为RGB图像)
- cv2.COLOR_GRAY2BGR (灰度图像图像转化为BGR图像)
通过下面的方式将原图像转换为灰度图像和RGB图像,编写实验代码:
# -*- coding: utf-8 -*-
import cv2
import numpy as np
from pylab import *
from PIL import Image
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
# 读取图像
im = imread('alcatraz1.jpg')
im1 = cv2.imread('alcatraz1.jpg')
gray = cv2.cvtColor(im1,cv2.COLOR_BGR2GRAY)
BGR = cv2.cvtColor(gray,cv2.COLOR_GRAY2BGR)
figure()
subplot(131)
title(u'(a)原始图像', fontproperties=font)
axis('off')
imshow(im)
subplot(132)
title(u'(b)COLOR_BGR2GRAY转换后图像', fontproperties=font)
axis('off')
imshow(gray)
subplot(133)
title(u'(c)(b)经过COLOR_GRAY2RGB转换后图像', fontproperties=font)
axis('off')
imshow(BGR)
show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
实验结果:



(3) 显示图像及结果
利用OpenCv绘制功能和窗口管理功能来显示结果。
例子1 :从文件中读取一幅图像,并创建一个整数图像表示,编写实验代码:
# -*- coding: utf-8 -*-
import cv2
import numpy as np
from pylab import *
from PIL import Image
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
# 读取图像
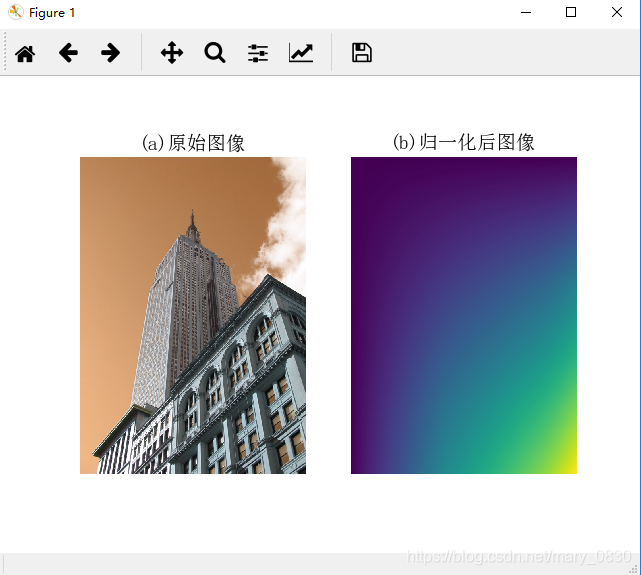
im = cv2.imread('empire.jpg')
gray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
# 计算积分图像
intim = cv2.integral(gray)
# 归一化并保存
intim = (255.0*intim) / intim.max()
figure()
subplot(121)
title(u'(a)原始图像', fontproperties=font)
axis('off')
imshow(im)
subplot(122)
title(u'(b)归一化后图像', fontproperties=font)
axis('off')
imshow(intim)
show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
实验结果:
实验分析:
读取图像后,将其转化为灰度图像,函数 integral() 创建一幅图像,该图像的每个像素值是原图上方和左边强度值相加后的结果。这对于快速评估特征是一个非常有用的技巧。在保存图像前,通过除以图像中的像素最大值将其归一化到0至255之间。
例子2 : 从一个种子像素进行泛洪填充,编写实验代码:
# -*- coding: utf-8 -*-
import cv2
import numpy as np
from pylab import *
from PIL import Image
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
# 读取图像
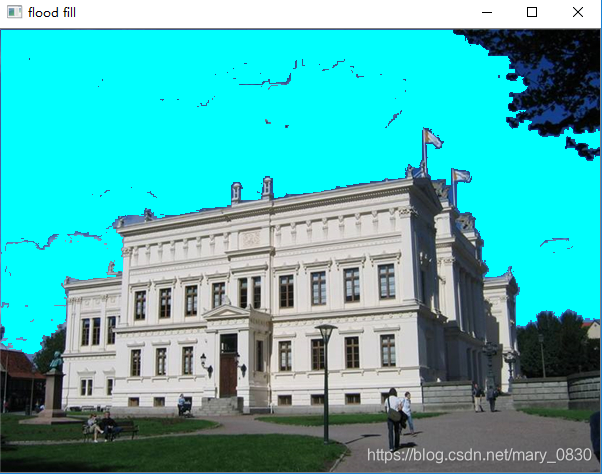
im = cv2.imread('university.jpg')
h,w = im.shape[:2]
# 泛洪填充
diff = (6,6,6)
mask = zeros((h+2,w+2),uint8)
im1 = cv2.floodFill(im,mask,(10,10), (255,255,0),diff,diff)
# 在OpenCV 窗口中显示结果
cv2.imshow('flood fill',im)
cv2.waitKey()
# 保存结果
cv2.imwrite('result.jpg',im)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
实验结果:

分析:
在例子2中,对图像应用泛洪填充并在 OpenCV 窗口中显示结果。waitKey() 函数一直处于暂停状态,直到有按键按下,此时窗口才会自动关闭。这里的 floodfill() 函数获取(灰度或彩色)图像、一个掩膜(非零像素区域表明该区域不会被填充)、一 个种子像素以及新的颜色值来代替下限和上限阈值差的泛洪像素。泛洪填充以种子像素为起始,只要能在阈值的差异范围内添加新的像素,泛洪填充就会持续扩展。不同的阈值差异由元组 给出。
例子3 : SURF特征的提取,SURF特征是SIFT特征的一个更快特征提取版,编写实验代码:
# -*- coding: utf-8 -*-
import cv2
import numpy as np
from pylab import *
from PIL import Image
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
# 读取图像
im = cv2.imread('empire.jpg')
# 下采样
im_lowres = cv2.pyrDown(im)
# 变换成灰度图像
gray = cv2.cvtColor(im_lowres,cv2.COLOR_RGB2GRAY)
# 检测特征点
s = cv2.xfeatures2d.SIFT_create()
mask = uint8(ones(gray.shape))
keypoints = s.detect(gray,mask)
# 显示结果及特征点
vis = cv2.cvtColor(gray,cv2.COLOR_GRAY2BGR)
for k in keypoints[::10]:
cv2.circle(vis,(int(k.pt[0]),int(k.pt[1])),2,(0,255,0),-1)
cv2.circle(vis,(int(k.pt[0]),int(k.pt[1])),int(k.size),(0,255,0),2)
cv2.imshow('local descriptors', vis)
cv2.waitKey()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
实验结果:


实验分析:
读取图像后,如果没有给定新尺寸,则用 pyrDown() 进行下采样,创建一个尺寸为原 图像大小一半的新图像,然后将该图像转换为灰度图像,并传递到一个 SURF 关键点检测对象;掩膜决定了在哪些区域应用关键点检测器。在画出检测结果时,将灰度图像转换成彩色图像,并用绿色通道画出检测到的关键点。在每到第十个关键点时循环一次,并在中心画一个圆环,每一个圆环显示出关键点的尺度(大小)。绘图函数 circle() 获取一幅图像、图像坐标(仅整数坐标)元组、半径、绘图的颜色元组以及线条粗细(-1 是实线圆环)。上图显示了提取出来的 SURF 特征。
遇到的问题及解决办法:

错误原因: OpenCv将SIFT、SURF等算法整合到xfeatures2d集合里面。
修改: 需要将s = cv2.SURF() 修改为s = cv2.xfeatures2d.SIFT_create() 即可。
(三)处理视频
单纯使用 Python 来处理视频有些困难,因为需要考虑速度、编解码器、摄像机、操作系统和文件格式。目前还没有针对 Python 的视频库,使用 OpenCV 的 Python 接口是唯一不错的选择。
(1)视频输入
OpenCV 能够很好地支持从摄像头读取视频。下面给出了一个捕获视频帧并在 OpenCV 窗口中显示这些视频帧的完整例子,编写实验代码:
# -*- coding: utf-8 -*-
import cv2
# 设置视频捕获
cap = cv2.VideoCapture(0)
while True:
ret,im = cap.read()
cv2.imshow('video test',im)
key = cv2.waitKey(10)
if key == 27:
break
if key == ord(' '):
cv2.imwrite('vid_result.jpg',im)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
实验结果:


实验说明:
捕获对象 VideoCapture 从摄像头或文件捕获视频。通过一个整数进行初始化,该整数为视频设备的 id。如果仅有一个摄像头与计算机相连接,那么该摄像头的 id 为 0。read() 方法解码并返回下一视频帧,第一个变量 ret 是一个判断视频帧是否成功读入的标志,第二个变量im则是实际读入的图像数组。函数 waitKey() 等待用户按键:如果按下的是 Esc 键(ASCII 码是 27)键,则退出应用;如果按下的是空格键,就保存该视频帧。
拓展上面的例子,将摄像头捕获的数据作为输入,并在 OpenCV 窗口中实时显示经模糊的(彩色)图像,对上面的代码进行修改为:
# -*- coding: utf-8 -*-
import cv2
# 设置视频捕获
cap = cv2.VideoCapture(0)
while True:
ret,im = cap.read()
blur = cv2.GaussianBlur(im, (0, 0), 5)
cv2.imshow('camera blur', blur)
if cv2.waitKey(10) == 27:
break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
实验结果:

实验说明:
每一视频帧都会被传递给 GaussianBlur() 函数,该函数会用高斯滤波器对传入的该帧图像进行滤波。这里,实验所传递的是彩色图像,所以 Gaussian Blur() 函数会录入对彩色图像的每一个通道单独进行模糊。该函数需要为高斯函数设定滤波器尺寸 (保存在元组中)及标准差;在本例中标准差设为 5。如果该滤波器尺寸设为 0,则它由标准差自动决定,显示出的结果与上面的实验结果相似。
(2)将视频读取到 NumPy 数组中
使用 OpenCV 可以从一个文件读取视频帧,并将其转换成 NumPy 数组。下面是一个从摄像头捕获视频并将视频帧存储在一个 NumPy 数组中的例子,代码如下:
# -*- coding: utf-8 -*-
import cv2
import numpy as np
# 设置视频捕获
cap = cv2.VideoCapture(0)
frames = []
# 获取帧,存储到数组中
while True:
ret,im = cap.read()
cv2.imshow('video',im)
frames.append(im)
if cv2.waitKey(10) == 27:
break
frames = array(frames)
# 检查尺寸
print (im.shape)
print (frames.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
实验结果:

实验说明:
上述代码将每一视频帧数组添加到列表末,直到捕获结束。最终得到的数组会有帧数、帧高、帧宽及颜色通道数(3 个)。这里总共记录了627帧。
(四)跟踪
跟踪是在图像序列或视频里对其中的目标进行跟踪的过程。
(1)光流
光流是目标、场景或摄像机在连续两帧图像间运动时造成的目标的运动。它是图像在平移过程中的二维矢量场。作为一种经典并深入研究了得方法,它在诸多视频压缩、运动估计、目标跟踪和图像分割等计算机视觉中得到了广泛的应用。
光流法主要依赖于三个假设:
- 亮度恒定:图像中目标的像素强度在连续帧之间不会发生变化。
- 时间规律:相邻帧之间的时间足够短,以至于在考虑运行变化时可以忽略它们之 间的差异。该假设用于导出下面的核心方程。
- 空间一致性:相邻像素具有相似的运动。
很多情况下这些假设并不成立,但是对于相邻帧间的小运动以及短时间跳跃,它还是一个非常好的模型。假设一个目标像素在 时刻亮度为,在时刻运动 后与 时刻具有相同的亮度,即 。 对该约束用泰勒公式进行一阶展开并关于 求偏导可以得到光流方程:
是运动矢量,是时间偏导。对于图像中那些单个的点,该方程是线性方程组。由于 包含两个未知变量,所以该方程是不可解的。通过强制加入空间一致性约束,则有可能获得该方程的解。
下面利用calcOpticalFlowFarneback()在视频中寻找运动矢量的例子,实验代码如下:
# -*- coding: utf-8 -*-
import cv2
import numpy as np
from pylab import *
from PIL import Image
def draw_flow(im,flow,step=16):
""" 在间隔分开的像素采样点处绘制光流 """
h,w = im.shape[:2]
y,x = mgrid[step/2:h:step,step/2:w:step].reshape(2,-1).astype(int)
fx, fy = flow[y, x].T
# 创建线的终点
lines = vstack([x,y,x+fx,y+fy]).T.reshape(-1,2,2)
lines = int32(lines)
# 创建图像并绘制
vis = cv2.cvtColor(im, cv2.COLOR_GRAY2BGR)
for (x1, y1), (x2, y2) in lines:
cv2.line(vis, (x1, y1), (x2, y2), (0, 255, 0), 1)
cv2.circle(vis, (x1, y1), 1, (0, 255, 0), -1)
return vis
#设置视频捕获
cap = cv2.VideoCapture(0)
ret,im = cap.read()
prev_gray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
while True:
# 获取灰度图像
ret,im = cap.read()
gray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
# 计算流
flow = cv2.calcOpticalFlowFarneback(prev_gray,gray,None,0.5,3,15,3,5,1.2,0)
prev_gray = gray
# 画出流矢量
cv2.imshow('Optical flow',draw_flow(gray,flow))
if cv2.waitKey(10) == 27:
break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
实验结果:

实验说明:
利用摄像头捕获图像,并对每个连续图像对进行光流估计。由于calcOpticalFlowFarneback() 返回的运动光流矢量保存在双通道图像变量 flow 中。除了需要获取前一帧和当前帧,该函数还需要一系列参数。辅助函数 draw_flow() 会在图像均匀间隔的点处绘制光流矢量, 它利用 OpenCV 的绘图函数 line() 和 circle(),并用变量 step 控制流样本的间距。 最终的结果上图所示:圆环网格表示流样本的位置,带有线条的流矢量显示了每个样本点是怎样运动的。
遇到的问题及解决办法:
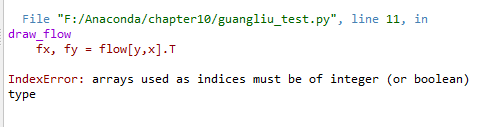
修改为:
y, x = mgrid[step / 2:h:step, step / 2:w:step].reshape(2, -1).astype(int)
#以网格的形式选取二维图像上等间隔的点,这里间隔为16,reshape成2行的array
(2)Lucas-Kanade算法
跟踪最基本的形式是跟随感兴趣点,比如角点。Lucas-Kanade 跟踪算法可以应用于任何一种特征,不过通常使用一些角点,角点是结构张量(Harris 矩阵)中有两个较大特征值的那些点,且更小的特征值要大于某个阈值。
如果基于每一个像素考虑,该光流方程组是欠定方程,即每个方程中含很多未知变量。利用相邻像素有相同运动这一假设,对于 n 个相邻像素,可以将这些方程写成如下系统方程:
该系统方程的优势是,现在方程的数目多于未知变量,并且可以用最小二乘法解出该系统方程。对于周围像素的贡献可以进行加权处理,使越远的像素影响越小;高斯权重是一种最常见的选择。将上面的矩阵变换成方程的结构张量形式,可以得出以下关系: 或者简记为:
该超定方程组可以用最小二乘法求解,得出运动矢量:
v 只有在 可逆时才是可解的。这就是 Lucas-Kanade 跟踪算法运行矢量怎样计算出来的全过程。
标准的 Lucas-Kanade 跟踪适用于小位移。为了能够处理较大位移,需要采用分层的方法。在该情形下,光流可以通过对图像由粗到精采样计算得到。这就是 OpenCV 函数 calcOpticalFlowPyrLK() 要做的事。
这些 Lucas-Kanade 函数包含在 OpenCV 中,利用这些函数建立一个 Python 跟踪类。创建名为 lktrack.py 的文件,向其添加下面的类和构造函数:
# -*- coding: utf-8 -*-
from numpy import *
import cv2
# 一些常数及默认参数
lk_params = dict(winSize=(15,15),maxLevel=2,
criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT,10,0.03))
subpix_params = dict(zeroZone=(-1,-1),winSize=(10,10),
criteria = (cv2.TERM_CRITERIA_COUNT | cv2.TERM_CRITERIA_EPS,20,0.03))
feature_params = dict(maxCorners=500,qualityLevel=0.01,minDistance=10)
class LKTracker(object):
""" 用金字塔光流 Lucas-Kanade 跟踪类"""
def __init__(self,imnames):
""" 使用图像名称列表初始化 """
self.imnames = imnames
self.features = []
self.tracks = []
self.current_frame = 0
def detect_points(self):
""" 利用子像素精确度在当前帧中检测“利于跟踪的好的特征”( 角点 ) """
# 载入图像并创建灰度图像
self.image = cv2.imread(self.imnames[self.current_frame])
self.gray = cv2.cvtColor(self.image,cv2.COLOR_BGR2GRAY)
# 搜索好的特征点
features = cv2.goodFeaturesToTrack(self.gray, **feature_params)
# 提炼角点位置
cv2.cornerSubPix(self.gray,features, **subpix_params)
self.features = features
self.tracks = [[p] for p in features.reshape((-1,2))]
self.prev_gray = self.gray
def track_points(self):
""" 跟踪检测到的特征 """
if self.features != []:
self.step() # 移到下一帧
# 载入图像并创建灰度图像
self.image = cv2.imread(self.imnames[self.current_frame])
self.gray = cv2.cvtColor(self.image,cv2.COLOR_BGR2GRAY)
#reshape() 操作,以适应输入格式
tmp = float32(self.features).reshape(-1, 1, 2)
# 计算光流
features,status,track_error = cv2.calcOpticalFlowPyrLK(self.prev_gray,self.gray,tmp,None,**lk_params)
# 去除丢失的点
self.features = [p for (st,p) in zip(status,features) if st]
# 从丢失的点清楚跟踪轨迹
features = array(features).reshape((-1,2))
for i,f in enumerate(features):
self.tracks[i].append(f)
ndx = [i for (i,st) in enumerate(status) if not st]
ndx.reverse() # 从后面移除
for i in ndx:
self.tracks.pop(i)
self.prev_gray = self.gray
def step(self,framenbr=None):
""" 移到下一帧。如果没有给定参数,直接移到下一帧 """
if framenbr is None:
self.current_frame = (self.current_frame + 1) % len(self.imnames)
else:
self.current_frame = framenbr % len(self.imnames)
def track(self):
""" 发生器,用于遍历整个序列 """
for i in range(len(self.imnames)):
if self.features == []:
self.detect_points()
else:
self.track_points()
#创建一份 RGB 副本
f = array(self.features).reshape(-1,2)
im = cv2.cvtColor(self.image,cv2.COLOR_BGR2RGB)
yield im,f
def draw(self):
""" 用 OpenCV 自带的画图函数画出当前图像及跟踪点,按任意键关闭窗口 """
# 用绿色圆圈画出跟踪点
for point in self.features:
cv2.circle(self.image,(int(point[0][0]),int(point[0][1])),3,(0,255,0),-1)
cv2.imshow('LKtrack',self.image)
cv2.waitKey()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
用一个文件名列表对跟踪对象进行初始化,变量features和tracks分别保存角点和对这些角点进行跟踪的位置,同时,利用一个变量对当前帧进行跟踪。定义了三个字典变量用于特征提取、跟踪、和亚像素特征点的提炼。在开始检测角点时,需要载入实际图像,并转换成灰度图像,提取“利用跟踪的好的特征”点。 OpenCv函数
goodFeaturesToTrack() 方法可以完成这一主要工作。
用 OpenCV 函数实现了一个完整独立的跟踪系统。
1. 使用跟踪器
将该跟踪类用于真实的场景中。下面的脚本初始化一个跟踪对象,对视频序列进行角点检测、跟踪,并画出跟踪结果:
# -*- coding: utf-8 -*-
import lktrack
imnames = ['F:\\Anaconda\\chapter10\\images\\bt.005.pgm','F:\\Anaconda\\chapter10\\images\\bt.004.pgm',
'F:\\Anaconda\\chapter10\\images\\bt.003.pgm', 'F:\\Anaconda\\chapter10\\images\\bt.002.pgm',
'F:\\Anaconda\\chapter10\\images\\bt.001.pgm', 'F:\\Anaconda\\chapter10\\images\\bt.000.pgm']
# 创建跟踪对象
lkt = lktrack.LKTracker(imnames)
# 在第一帧进行检测,跟踪剩下的帧
lkt.detect_points()
lkt.draw()
for i in range(len(imnames)-1):
lkt.track_points()
lkt.draw()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
实验结果:






实验说明:
每次画出一帧,并显示当前跟踪到的点,按任意键会转移到序列的下一帧。6幅结果图显示了牛津corridor 序列的前 6 幅图像的跟踪结果。(http://www.robots.ox.ac.uk/~vgg/data/data-mview.html )
2. 使用发生器
将下面的方法添加到 LKTracker 类:
def track(self):
""" 发生器,用于遍历整个序列 """
for i in range(len(self.imnames)):
if self.features == []:
self.detect_points()
else:
self.track_points()
#创建一份 RGB 副本
f = array(self.features).reshape(-1,2)
im = cv2.cvtColor(self.image,cv2.COLOR_BGR2RGB)
yield im,f
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
上面的方法创建一个发生器,可以使遍历整个序列并将获得的跟踪点和这些图像以 RGB 数组保存,以方便画出跟踪结果。可以用经典牛津“dinosaur"序列,并画出这些点的跟踪结果,代码如下所示:
# -*- coding: utf-8 -*-
import lktrack
import cv2
import numpy as np
from pylab import *
from PIL import Image
imnames = ['F:\\Anaconda\\chapter10\\images (1)\\viff.000.ppm', 'F:\\Anaconda\\chapter10\\images (1)\\viff.001.ppm',
'F:\\Anaconda\\chapter10\\images (1)\\viff.002.ppm', 'F:\\Anaconda\\chapter10\\images (1)\\viff.003.ppm',
'F:\\Anaconda\\chapter10\\images (1)\\viff.004.ppm']
# 用 LKTracker 发生器进行跟踪
lkt = lktrack.LKTracker(imnames)
for im,ft in lkt.track():
print ('tracking %d features' % len(ft))
# 画出轨迹
figure()
imshow(im)
for p in ft:
plot(p[0],p[1],'bo')
for t in lkt.tracks:
plot([p[0] for p in t],[p[1] for p in t])
axis('off')
show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
实验结果:

增加一组对比:
imnames = ['F:\\Anaconda\\chapter10\\images\\bt.005.pgm','F:\\Anaconda\\chapter10\\images\\bt.004.pgm',
'F:\\Anaconda\\chapter10\\images\\bt.003.pgm', 'F:\\Anaconda\\chapter10\\images\\bt.002.pgm',
'F:\\Anaconda\\chapter10\\images\\bt.001.pgm', 'F:\\Anaconda\\chapter10\\images\\bt.000.pgm']
- 1
- 2
- 3

实验说明:
该发生器使前面定义的跟踪类的使用变得非常容易,并且完全向用户隐藏了OpenCv里的函数。该例子产生的结果如上图所示,画出了跟踪点的轨迹。从上面结果显示,输入的轨迹的图像越多,轨迹发生器检测到的跟踪点会越多。不同的图像展示出来的跟踪点轨迹不一样。
(五)更多示例
OpenCv自带很多关于如何使用python接口的有用示例。下面说明OpenCv的一些其他功能。
(1)图像修复 cv2.inpaint()
概念:
对图像丢失或损坏的部分进行重建的过程叫做修复, 既包括以复原为目的的对图像丢失数据或损坏部分进行恢复的算法,也包括在照片编辑应用程序中去除红眼或物体的算法。典型的例子是,图像的一个区域标记为“破损”,并需要利用余下的数据对该区域进行填补。
OpenCv中的cv2.inpaint()函数可以实现图像修复的工作。图像修复的基本思路很简单:用邻近的像素替换那些坏标记,使其看起来像是邻居。
库函数:
dst = cv2.inpaint(src,mask, inpaintRadius,flags)
参数是:
src: 输入8位1通道或3通道图像。
inpaintMask: 修复掩码,8位1通道图像。非零像素表示需要修复的区域。
dst: 输出与src具有相同大小和类型的图像。
inpaintRadius: 算法考虑的每个点的圆形邻域的半径。
flags:
- INPAINT_NS基于Navier-Stokes的方法
- Alexandru Telea的INPAINT_TELEA方法
实现:
OpenCV提供了两种算法,两者都可以通过相同的函数访问,cv2.inpaint()
-
基于快速行进方法的图像修复技术:使用标志cv2.INPAINT_TELEA启用此算法
考虑图像中要修复的区域。算法从该区域的边界开始,然后进入区域内,逐渐填充边界中的所有内容。它需要在邻近的像素周围的一个小邻域进行修复。该像素由邻居中所有已知像素的归一化加权和代替。选择权重是一个重要的问题。对于靠近该点的那些像素,靠近边界的法线和位于边界轮廓上的像素,给予更多的权重。一旦像素被修复,它将使用快速行进方法移动到下一个最近的像素。FMM确保首先修复已知像素附近的像素,这样它就像手动启发式操作一样工作。 -
基于流体动力学的图像和视频修补:使用标志cv2.INPAINT_NS启用此算法
该算法基于流体动力学并利用偏微分方程。基本原则是heurisitic。它首先沿着已知区域的边缘行进到未知区域(因为边缘是连续的)。它继续等照片(连接具有相同强度的点的线,就像轮廓连接具有相同高度的点一样),同时在修复区域的边界处匹配渐变矢量。为此,使用来自流体动力学的一些方法。获得颜色后,填充颜色以减少该区域的最小差异。
创建一个与输入图像大小相同的掩码,其中非零像素对应于要修复的区域,编写实验代码:
# -*- coding: utf-8 -*-
import numpy as np
from matplotlib import pyplot as plt
import cv2
img = cv2.imread('inpainting_pictures\OpenCV_Logo_B.png') # input
mask = cv2.imread('inpainting_pictures\OpenCV_Logo_C.png',0) # mask
dst_TELEA = cv2.inpaint(img,mask,3,cv2.INPAINT_TELEA)
dst_NS = cv2.inpaint(img,mask,3,cv2.INPAINT_NS)
plt.subplot(221), plt.imshow(img)
plt.title('degraded image')
plt.subplot(222), plt.imshow(mask, 'gray')
plt.title('mask image')
plt.subplot(223), plt.imshow(dst_TELEA)
plt.title('TELEA')
plt.subplot(224), plt.imshow(dst_NS)
plt.title('NS')
plt.tight_layout()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
实验结果:
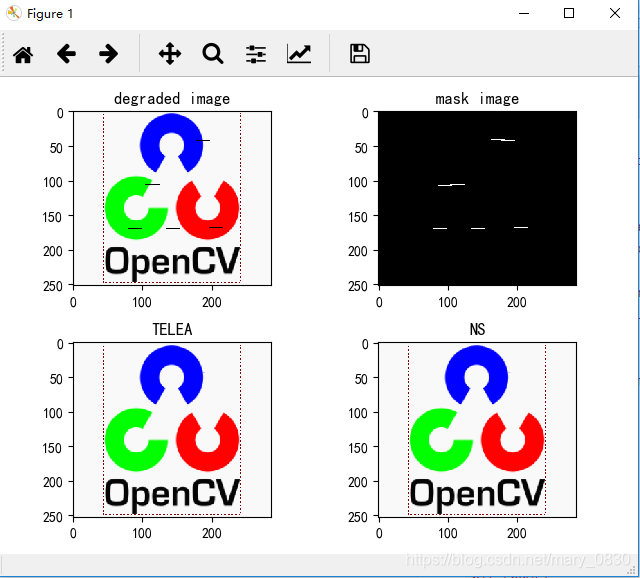
实验说明:
第一个是降级的OpenCV徽标,第二个图片是运行FMM所需的掩码。最后两张照片是两种算法修补的结果。从上面的结果看出,两种修补方法之间基本没有任何区别。
(2)利用分水岭变换进行分割 cv2.watershed()
分水岭是一种可以用于分割的图像处理技术。图像可以看成是一幅有很多种子区域“淹没”后形成的拓扑地貌。由于梯度幅值图像在突出的边缘有脊,而且分割通常在这些边缘处停止,所以通常会用到梯度幅值图像。(在之前的图像处理学习中也提到了分水岭分割法,可以参考 https://blog.csdn.net/mary_0830/article/details/89597672#_605 ,这是用matlab实现的)
原理背景:
任何一幅灰度图像都可以被看成拓扑平面,灰度值高的区域可以被看成是山峰,灰度值低的区域可以被看成是山谷。我们向每一个山谷中灌不同颜色的水,随着水的位的升高,不同山谷的水就会相遇汇合,为了防止不同山谷的水汇合,我们需要在水汇合的地方构建起堤坝。不停的灌水,不停的构建堤坝直到所有的山峰都被水淹没。我们构建好的堤坝就是对图像的分割。
原理描述:
上面所述的方法通常都会得到过度分割的结果,这是由噪声或者图像中其他不规律的因素造成的。为了减少这种影响, OpenCV 采用了基于掩模的分水岭算法,在这种算法中我们要设置哪些山谷点会汇合,哪些不会,这是一种交互式的图像分割。设置分水岭就是根据需要设置不同的标签。
- 如果某个区域是前景或对象,就使用某个颜色(或灰度值)标签标记它。
- 如果某个区域是背景就使用另外一个颜色标签标记。
- 剩下的不能确定是前景还是背景的区域就用 0 标记。
这就是所设置的标签。然后实施分水岭算法。每一次灌水,我们的标签就会被更新,当两个不同颜色的标签相遇时就构建堤坝,直到将所有山峰淹没,最后我们得到的边界对象(堤坝)的值为 -1。
编写实验代码:
# -*- coding: utf-8 -*-
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('alcatraz1.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
#cv2.imshow('ret',thresh)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
# noise removal
kernel = np.ones((3,3),np.uint8)
opening = cv2.morphologyEx(thresh,cv2.MORPH_OPEN,kernel, iterations = 2) # 形态开运算
# sure background area
sure_bg = cv2.dilate(opening,kernel,iterations=3)
# Finding sure foreground area
dist_transform = cv2.distanceTransform(opening,cv2.DIST_L2,5)
ret, sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.max(),255,0)
# Finding unknown region
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg,sure_fg)
# Marker labelling
ret, markers = cv2.connectedComponents(sure_fg)
# Add one to all labels so that sure background is not 0, but 1
markers = markers+1
# Now, mark the region of unknown with zero
markers[unknown==255] = 0
markers = cv2.watershed(img,markers)
img[markers == -1] = [255,0,0]
#cv2.imshow('img',img)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
plt.subplot(421), plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)),
plt.title('original'), plt.axis('off')
plt.subplot(422), plt.imshow(thresh, cmap='gray'),
plt.title('threshold'), plt.axis('off')
plt.subplot(423), plt.imshow(sure_bg, cmap='gray'),
plt.title('dilate'), plt.axis('off')
plt.subplot(424), plt.imshow(dist_transform, cmap='gray'),
plt.title('distanceTransform'), plt.axis('off')
plt.subplot(425), plt.imshow(sure_fg, cmap='gray'),
plt.title('threshold'), plt.axis('off')
plt.subplot(426), plt.imshow(unknown, cmap='gray'),
plt.title('subtract'), plt.axis('off')
plt.subplot(427), plt.imshow(np.abs(markers), cmap='jet'),
plt.title('mMarkers'), plt.axis('off')
plt.subplot(428), plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)),
plt.title('result'), plt.axis('off')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
实验结果:

实验说明:
需要去除图像中的任何噪音。 为此,实验中可以使用形态开放。要删除物体中的任何小孔,我们可以使用形态关闭。 提取需要的主体(房子)的区域,侵蚀去除边界像素。剩下的区域是我们没有任何想法的区域,无论是主体还是背景,流域算法应该找到它。 这些区域通常位于前景和背景相遇的边界。我们称之为边界,可以从sure_bg区域中减去sure_fg区域获得。看到结果,在阈值图像中,我们得到一些房子的区域,这是试验中的主体部分,现在它们已经分离。现在已经把前景和背景分离开, 所以现在创建标记(它是一个与原始图像大小相同的数组,但是使用int32数据类型),并标记它内部的区域。 无论是前景还是背景都被标记为任何正整数,但是不同的整数,不确定的区域只能保持为零。 为此,使用cv2.connectedComponents()。它用0标记图像的背景,然后其他对象用从1开始的整数标记。标记准备好了,现在是最后一步,应用流域算法。然后标记图像将被修改,边界区域将被标记为-1。
(3)利用霍夫变换检测直线 cv2.HoughLines()
霍夫变换 (Hough Transform)是图像处理中的一种特征提取技术,它通过一种投票算法检测具有特定形状的物体。
霍夫变换作用:
创建一个滑动条来控制检测直线的长度阈值,即大于该阈值的检测出来,小于该阈值的忽略。
OpenCV提供了两种用于直线检测的Hough变换形式,分别是cv2.HoughLinesP() 和cv2.HoughLines()。其中基本的版本是cv2.HoughLines。其输入一幅含有点集的二值图(由非0像素表示),其中一些点互相联系组成直线。
编写实验代码:
# -*- coding: utf-8 -*-
import cv2 as cv
import numpy as np
img = cv.imread("Fig0309(a).tif")
cv.imshow('img', img)
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
edges = cv.Canny(gray, 50, 150, apertureSize=3)
cv.imshow('edge', edges)
# 计算直线
lines = cv.HoughLines(edges, 1, np.pi / 180, 180)
tmp = img.copy()
for line in lines:
rho, theta = line[0]
a = np.cos(theta)
b = np.sin(theta)
x0 = a * rho
y0 = b * rho
x1 = int(x0 + 1000 * (-b))
y1 = int(y0 + 1000 * (a))
x2 = int(x0 - 1000 * (-b))
y2 = int(y0 - 1000 * (a))
cv.line(tmp, (x1, y1), (x2, y2), (0, 0, 255), 4)
cv.imshow('line', tmp)
# 直接获取线段
lines = cv.HoughLinesP(edges, 1, np.pi / 180, 100, minLineLength=100, maxLineGap=10)
tmp = img.copy()
for line in lines:
x1, y1, x2, y2 = line[0]
cv.line(tmp, (x1, y1), (x2, y2), (0, 0, 255), 4)
cv.imshow('line2', tmp)
cv.waitKey(0)
cv.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
实验结果:
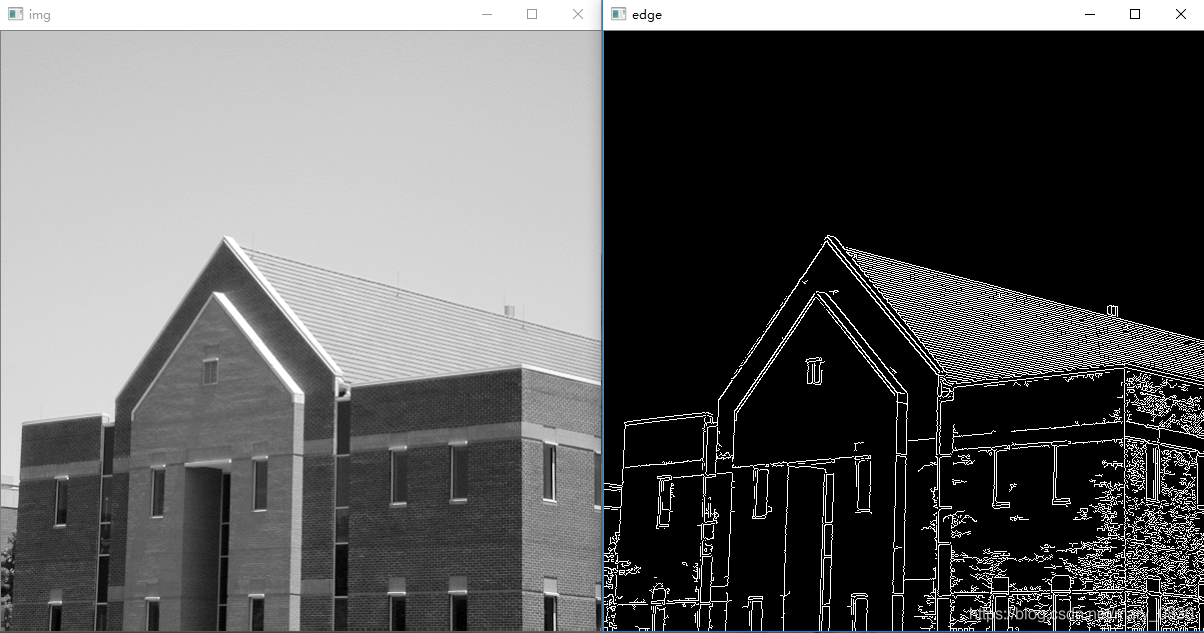

实验说明:
利用霍夫变换检测直线的结果中,第一幅图显示的是灰度的原图像,第二幅图显示的是检测出角点的图像,第三幅图是检测到直线的图像,第四幅图检测到线段的图像。这个算法的不足是:有些直线或者线段并不能完全的检测出来。比如说,窗口上的横线在线段检测或者直线检测都没有能够检测出来。
如果您在阅读之中发现文章错误之处或者出现疑问,欢迎在评论指出。
所属网站分类: 技术文章 > 博客
作者:44344df
链接:https://www.pythonheidong.com/blog/article/52916/37262e77d6473e3a3ab9/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力