

mmdetection
发布于2019-08-22 16:48 阅读(6169) 评论(0) 点赞(20) 收藏(4)
参考:
mmdetection检测训练和源码解读
源码解读
图像目标检测之cascade-rcnn实践
mmdetection添加focal loss
mmdetection,训练自己的数据
训练自定义的dataset
概述
- 训练检测器的主要单元:数据加载、模型、迭代流水线。
- mmdetection检测工具的特点是模块化封装,利用现有模块搭建自己的网络便利,而且提供给用户自己构建模块的通道,自由度高,贡献了很多新的算法,分布式训练,使用了商汤的mcv库。
- 该mmdetection做了封装,build_detector函数搭建模型,inference_detector函数负责推理检测,将不同的模块封装为backbone/neck/head等部分,在config中写入,通过读取配置,注册模块,进行封装,然后高级调用搭建网络。
- 相比FAIR 此前开源的 Detectron,基于 PyTorch 的检测库——mmdetection有以下几大优势:
优势一:Performance 稍高
优势二:训练速度稍快: Mask R-CNN 差距比较大,其余的很小。
优势三:所需显存稍小: 显存方面优势比较明显,会小 30% 左右。
优势四:易用性更好: 基于 PyTorch 和基于 Caffe2 的 code 相比,易用性是有代差的。
python虚拟环境
$ virtualenv myproject
$ source myproject/bin/activate
- 1
- 2
执行第一个命令在myproject文件夹创建一个隔离的virtualenv环境,第二个命令激活这个隔离的环境(virtualenv)。
在创建virtualenv时,你必须做出决定:这个virtualenv是使用系统全局的模块呢?还是只使用这个virtualenv内的模块。
默认情况下,virtualenv不会使用系统全局模块。
如果你想让你的virtualenv使用系统全局模块,请使用–system-site-packages参数创建你的virtualenv,例如:
virtualenv --system-site-packages mycoolproject
- 1
使用以下命令可以退出这个virtualenv:
$ deactivate
- 1
训练自己的数据集(经验总结:自己的数据集在生成相应文本或者转化什么格式之前最好先把命名用脚本按照顺序排列,中间的序号最好是连续的,不要缺空)
因为通过labelImg生成的是xml文件,那么直接就改造成voc数据集的格式即可,这样就能直接利用xml,而不需要数据格式转换这一步。
在程序里面最好使用相对路径,不要使用绝对路径,这样才好移植。
非常重要,在训练自定义数据之前,一定要仔细阅读这个链接,尤其是安装步骤d步,我在进行训练指令时遇到的各种各样的问题都是因为这个文档没有仔细阅读,d步骤也没有按照执行。
mmdetection训练voc格式数据集
- 首先,准备voc格式的数据集,并按照以下目录存储
mmdetection
├── mmdet
├── tools
├── configs
├── data #手动创建data、VOCdevkit、VOC2007、Annotations、JPEGImages、ImageSets、Main这些文件夹
│ ├── VOCdevkit
│ │ ├── VOC2007
│ │ │ ├── Annotations #把test.txt、trainval.txt对应的xml文件放在这
│ │ │ ├── JPEGImages #把test.txt、trainval.txt对应的图片放在这
│ │ │ ├── ImageSets
│ │ │ │ ├── Main
│ │ │ │ │ ├── test.txt (这里面存放的是每张测试图片的图片,不包括后缀,也不要路径)
│ │ │ │ │ ├── trainval.txt(这里面存放的是每张训练图片的图片,不包括后缀,也不要路径)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
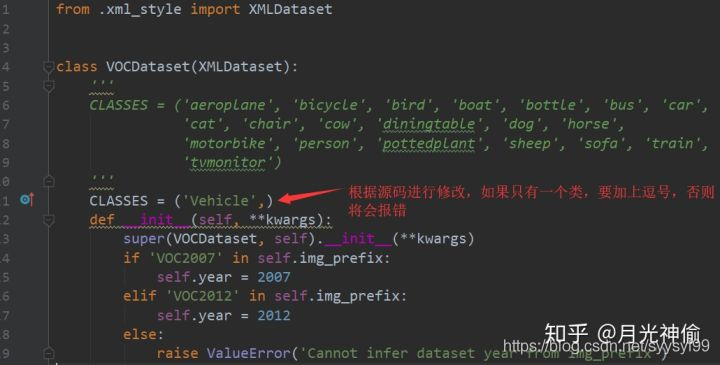
- 修改mmdetection/mmdet/core/evaluation下的class_names.py中的voc_classes,将其改为要训练的数据集的类别名称。注意的是,如果类别只有一个,也是要加上逗号的,否则会报错,如下:

- 修改mmdetection/mmdet/datasets/voc.py 下的类别,如果只有一个类,要加上一个逗号,否则将会报错
- 修改配置文件.
这里的配置文件指的是mmdetection/configs下一堆的名称诸如cascade_rcnn_r50_fpn_1x.py的文件,也就是你要训练的网络,不过mmdetecion已经把模型搭好,直接调用就好。
默认情况下,这些配置文件的使用的是coco格式,只有mmdetection/pascal_voc文件夹下的模型是使用voc格式,不过数量很少,只有三个。
如果要使用其他模型,则需要修改配置文件,这里以cascade_rcnn_r50_fpn_1x.py为例
- 在mmdetection/configs/cascade_rcnn_r50_fpn_1x.py, 首先,全局搜索num_classes,将其值改为: 类别数+1,改了三次。
- 接着修改cascade_rcnn_r50_fpn_1x.py中的dataset settings
- 修改cascade_rcnn_r50_fpn_1x.py的dataset_type和dataroot以及ann_file和img_prefix
下图很重要
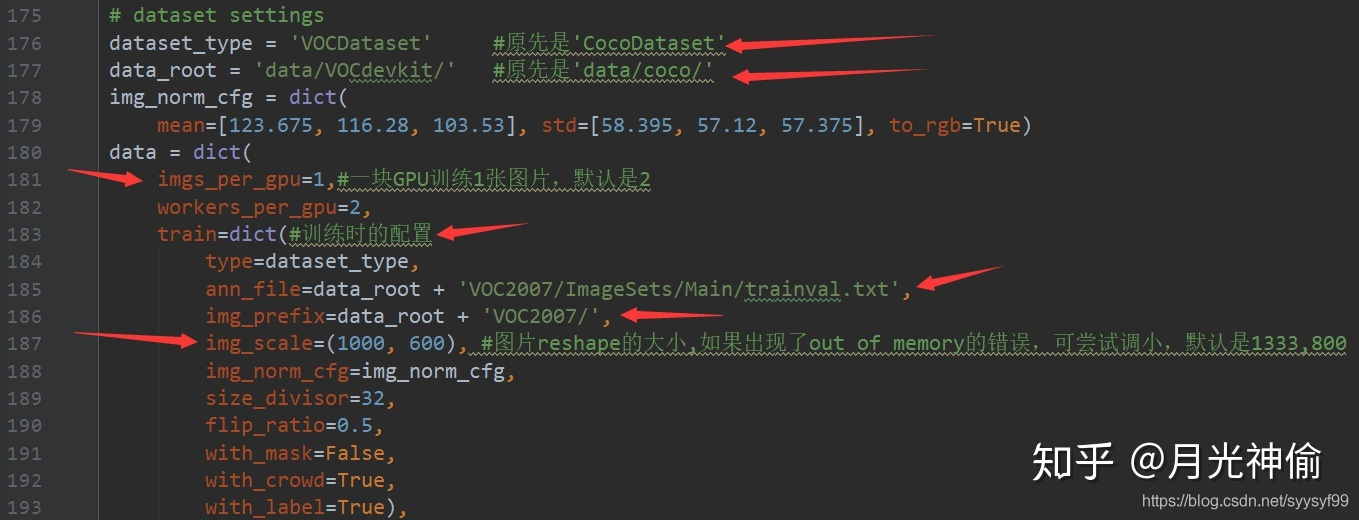
上图中这里train=dict(…)表示训练时的配置,同样的还要对val,test进行配置
这里imgs_per_gpu表示一块gpu训练的图片数量,imgs_per_gpu的值会影响终端输出的显示,比如,如果你有一块GPU,训练集有4000张,imgs_per_gpu设为2的话,终端的输出可能是Epoch [1][50/2000]。另外,也需要根据imgs_per_gpu的值修改学习率,否则可能会出现梯度爆炸的问题。
关于上面这段粗体字的理解,我在实际训练时,因为是一块gpu,且设置了这块gpu只训练一张图片,imgs_per_gpu=1。在训练时终端的一部分输出如下:
Epoch [1][50/4325] lr: 0.00100 s0.acc: 86.8906,s1.acc: 92.4492,s2.acc: 91.5039,loss: 1.6009
Epoch [1][100/4325] lr: 0.00116,s0.acc: 83.5664,s1.acc: 86.8912,s2.acc: 93.6975
Epoch [1][150/4325] lr: 0.00133,
Epoch [1][450/4325] lr: 0.00233
Epoch [1][500/4325] lr: 0.00250,
Epoch [1][550/4325] lr: 0.00250,
Epoch [1][4250/4325] lr: 0.00250,s0.acc: 91.8164,s1.acc: 91.8085,s2.acc: 90.3332,
Epoch [1][4300/4325] lr: 0.00250
Epoch [2][50/4325] lr: 0.00250,s0.acc: 92.3086,s1.acc: 93.0722,s2.acc: 91.9551,
Epoch [2][4250/4325] lr: 0.00250,s0.acc: 93.2656,s1.acc: 94.2887,s2.acc: 92.8941,
Epoch [2][4300/4325] lr: 0.00250
Epoch [3][50/4325] lr: 0.00250,
Epoch [3][4300/4325] lr: 0.00250, s0.acc: 94.0078,s1.acc: 94.5620,s2.acc: 93.4796,
Epoch [8][4300/4325] lr: 0.00250, 第8个epoch学习率没变
Epoch [9][250/4325] lr: 0.00025,第9个epoch学习率降低了
Epoch [10][1900/4325] lr: 0.00025,第9个epoch学习率保持着低值
Epoch [11][950/4325] lr: 0.00025,第11个epoch时学习率保持着低值
Epoch [12][4300/4325] lr: 0.00003, s1.acc: 98.8292,s2.acc: 98.5651,loss: 0.1845最后一个epoch学习率又降低了
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
从输出中可以发现规律,
- 因为我一共是有4325张测试图片,然后在config文件中对log_config有设置interval=50,所以上面输出log中每间隔50张图片迭代一次,把所有图片迭代一个轮回之后,就由epoch1变成了epoch2,一直到epoch12就训练自动停止,这是因为在config文件中设置了total_epochs = 12。
- 在前500次迭代中学习率是逐渐线性增加的,然后后面的学习率就不再变化了。这是因为在config文件里面设置了:
lr_config = dict(
policy='step',#优化策略
warmup='linear',#初始的学习率增加的策略,linear为线性增加,
warmup_iters=500,#在初始的500次迭代中学习率逐渐增加
warmup_ratio=1.0 / 3,#设置的起始学习率
step=[8, 11])#在第9 第10 和第11个epoch时降低学习率
- 1
- 2
- 3
- 4
- 5
- 6
后来学习率一直稳定在0.0025是因为有代码:
optimizer = dict(type='SGD', lr=0.0025, momentum=0.9, weight_decay=0.0001)
- 1
- 在work_dirs下会有以训练的config文件配套的文件夹自动产生,里面有12个权重文件是因为有12个epoch,每一个epoch产生一个权重文件。在config文件里有设置:
checkpoint_config = dict(interval=1)#每一个epoch存储一次模型
- 1
-
摘抄:epoch后面的8684是总图片的数量 ,但是实际训练集有69472的图片,而只显示出8648的原因是mmdetection默认一张gpu训练2张图片,而该作者开启了4个gps,所以一个batch的大小是2*4=8 ,69472/8=8684,所以一共8684个batch。
-
因为我的训练只是目标检测,与分割无关,所以就评估bbox。
-
与我的训练无关,摘抄,是针对coco数据的训练情况的,coco默认AP即mAP,而不是某一类物体的AP。voc格式的数据集在测试后并不会直接输出mAP,需要保存测试结果另外计算mAP。
-
学习率的设置也很重要,
下图很重要

上面图片中提到,
4个GPU,每个处理2张图片,即一个batch 8张图片。学习率为0.01
那么一个GPU,每个处理1张图片,那么一个batch 1张图片。学习率是0.01/8=0.00125
若1个GPU,处理2张图片,则一个batch 2张图片,学习率是0.01/4=0.0025
- 对验证时的配置的修改。依旧是在cascade_rcnn_r50_fpn_1x.py文件内,默认是在每个epoch之后对验证集进行一次测试。如果没有验证集,这个是可以不用修改的。(注意有种说法是非分布式训练不支持验证集)
- 对测试时的配置的修改:在cascade_rcnn_r50_fpn_1x.py文件内。
图片很重要,注意看。还要注意的是不要忘记统一img_scale值。这个值的含义在上面的图片中有提到,这个参数很重要。
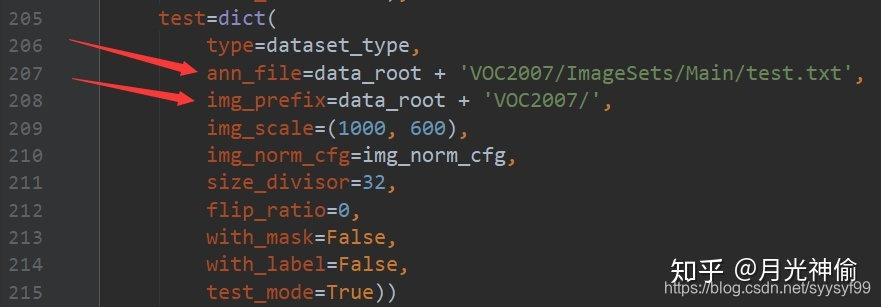
- 到第10步所有的修改操作完成。
- 接下来就是训练:
与下面的输出log对应的实际的训练指令
python3 tools/train.py configs/cascade_rcnn_r50_fpn_1x.py
- 1
- 2
每迭代完一个epoch,会保存一次模型参数(后缀为.pth),位于mmdetection/work_dirs/cascade_rcnn_r50_fpn_1x/。其中work_dirs为自动生成不需要手动创建。
训练产生的输出log如下:
12个epoch共训练了3个小时
(venv) syy@syy1996:~/software/mmdetection$ python3 tools/train.py configs/cascade_rcnn_r50_fpn_1x.py
2019-08-02 16:56:30,801 - INFO - Distributed training: False
2019-08-02 16:56:31,199 - INFO - load model from: modelzoo://resnet50
/home/syy/software/mmdetection2/venv/lib/python3.6/site-packages/mmcv/runner/checkpoint.py:140: UserWarning: The URL scheme of "modelzoo://" is deprecated, please use "torchvision://" instead
2019-08-02 16:56:31,312 - WARNING - unexpected key in source state_dict: fc.weight, fc.bias
missing keys in source state_dict: layer3.0.bn2.num_batches_tracked, layer1.0.bn3.num_batches_tracked, layer3.0.bn1.num_batches_tracked, layer3.1.bn2.num_batches_tracked, layer1.2.bn1.num_batches_tracked, layer2.2.bn2.num_batches_tracked, layer1.2.bn2.num_batches_tracked, layer3.0.downsample.1.num_batches_tracked, layer4.0.bn1.num_batches_tracked, layer2.1.bn3.num_batches_tracked, layer2.3.bn1.num_batches_tracked, layer2.2.bn3.num_batches_tracked, layer2.0.bn3.num_batches_tracked, layer2.0.bn1.num_batches_tracked, layer2.0.bn2.num_batches_tracked, layer3.2.bn3.num_batches_tracked, layer2.1.bn2.num_batches_tracked, layer4.2.bn2.num_batches_tracked, layer3.1.bn1.num_batches_tracked, layer3.4.bn1.num_batches_tracked, layer2.3.bn3.num_batches_tracked, layer4.0.bn2.num_batches_tracked, layer4.2.bn3.num_batches_tracked, layer4.2.bn1.num_batches_tracked, layer3.0.bn3.num_batches_tracked, layer3.3.bn3.num_batches_tracked, layer1.2.bn3.num_batches_tracked, layer3.5.bn2.num_batches_tracked, layer4.0.bn3.num_batches_tracked, layer3.3.bn2.num_batches_tracked, layer3.5.bn3.num_batches_tracked, layer3.3.bn1.num_batches_tracked, layer1.0.bn1.num_batches_tracked, layer1.0.downsample.1.num_batches_tracked, layer1.1.bn3.num_batches_tracked, layer1.1.bn1.num_batches_tracked, layer3.4.bn3.num_batches_tracked, layer3.4.bn2.num_batches_tracked, layer3.1.bn3.num_batches_tracked, layer4.1.bn2.num_batches_tracked, layer2.3.bn2.num_batches_tracked, layer4.1.bn1.num_batches_tracked, layer4.0.downsample.1.num_batches_tracked, layer4.1.bn3.num_batches_tracked, layer3.2.bn1.num_batches_tracked, layer3.5.bn1.num_batches_tracked, layer2.2.bn1.num_batches_tracked, layer2.1.bn1.num_batches_tracked, bn1.num_batches_tracked, layer2.0.downsample.1.num_batches_tracked, layer3.2.bn2.num_batches_tracked, layer1.0.bn2.num_batches_tracked, layer1.1.bn2.num_batches_tracked
**Start running,** INFO - **workflow: [('train', 1)], max: 12 epochs**
THCudaCheck FAIL file=/pytorch/aten/src/THC/THCGeneral.cpp line=383 **error=11 : invalid argument**
**Epoch [1][50/4325**] **lr: 0.00100**, eta: 3:28:16, time: 0.241, data_time: 0.004, memory: 1563, loss_rpn_cls: 0.4341, loss_rpn_bbox: 0.0504, s0.loss_cls: 0.4917, **s0.acc: 86.8906,** s0.loss_bbox: 0.2669, s1.loss_cls: 0.1773, **s1.acc: 92.4492**, s1.loss_bbox: 0.0840, s2.loss_cls: 0.0841, **s2.acc: 91.5039,** s2.loss_bbox: 0.0123, loss: **1.6009**
**Epoch [1][100/4325]** lr: 0.00116, eta: 3:17:24, time: 0.216, data_time: 0.002, memory: 1571, loss_rpn_cls: 0.1258, loss_rpn_bbox: 0.0358, s0.loss_cls: 0.4672, s0.acc: 83.5664, s0.loss_bbox: 0.3891, s1.loss_cls: 0.1946, s1.acc: 86.8912, s1.loss_bbox: 0.2468, s2.loss_cls: 0.0624, s2.acc: 93.6975, s2.loss_bbox: 0.0546, los**s: 1.5763**
Epoch [1][150/4325] lr: 0.00133, eta: 3:13:18, time: 0.215, data_time: 0.002, memory: 1580, loss_rpn_cls: 0.1031, loss_rpn_bbox: 0.0360, s0.loss_cls: 0.4536, s0.acc: 84.0625, s0.loss_bbox: 0.3364, s1.loss_cls: 0.2223, s1.acc: 84.1253, s1.loss_bbox: 0.3252, s2.loss_cls: 0.0901, s2.acc: 87.5991, s2.loss_bbox: 0.1127, loss**: 1.6793**
Epoch [12][4200/4325] lr: 0.00003, eta: 0:00:26, time: 0.213, data_time: 0.002, memory: 1580, loss_rpn_cls: 0.0020, loss_rpn_bbox: 0.0040, s0.loss_cls: 0.0476, s0.acc: 98.0547, s0.loss_bbox: 0.0247, s1.loss_cls: 0.0161, s1.acc: 98.6515, s1.loss_bbox: 0.0298, s2.loss_cls: 0.0081, s2.acc: 98.7081, s2.loss_bbox: 0.0291, loss: 0.1614
Epoch [12][4250/4325] lr: 0.00003, eta: 0:00:15, time: 0.209, data_time: 0.002, memory: 1580, loss_rpn_cls: 0.0014, loss_rpn_bbox: 0.0051, s0.loss_cls: 0.0530, s0.acc: 97.9336, s0.loss_bbox: 0.0276, s1.loss_cls: 0.0157, s1.acc: 98.8566, s1.loss_bbox: 0.0379, s2.loss_cls: 0.0091, s2.acc: 98.7018, s2.loss_bbox: 0.0382, loss: 0.1880
Epoch [12][4300/4325] lr: 0.00003, eta: 0:00:05, time: 0.212, data_time: 0.002, memory: 1580, loss_rpn_cls: 0.0022, loss_rpn_bbox: 0.0057, s0.loss_cls: 0.0495, s0.acc: 97.9922, s0.loss_bbox: 0.0284, s1.loss_cls: 0.0147, s1.acc: 98.8292, s1.loss_bbox: 0.0388, s2.loss_cls: 0.0081, s2.acc: 98.5651, s2.loss_bbox: 0.0371, loss: 0.1845
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
备注:
在成功运行训练指令之前,遇到的一些问题:
python3 tools/train.py configs/faster_rcnn_r50_fpn_1x.py --gpus 1 --validate --work_dir work_dirs
loading annotations into memory...
2019-07-30 19:08:43,571 - INFO - THCudaCheck FAIL file=/pytorch/aten/src/THC/THCGeneral.cpp line=383 error=11 : invalid argument
RuntimeError: CUDA out of memory. Tried to allocate 40.00 MiB (GPU 0; 5.79 GiB total capacity; 4.47 GiB already allocated; 34.56 MiB free; 26.71 MiB cached)
- 1
- 2
- 3
- 4
- 5
python3 tools/train.py configs/pascal_voc/faster_rcnn_r50_fpn_1x_voc0712.py
File "/home/syy/software/mmdetection/mmdet/ops/dcn/functions/deform_conv.py", line 5, in <module>
from .. import deform_conv_cuda
ImportError: libcudart.so.10.1: cannot open shared object file: No such file or directory
- 1
- 2
- 3
- 4
- 5
python3 tools/train.py configs/pascal_voc/faster_rcnn_r50_fpn_1x_voc0712.py
File "tools/train.py", line 8, in <module>
from mmdet import __version__
ModuleNotFoundError: No module named 'mmdet'
- 1
- 2
- 3
- 4
- 5
python3 tools/train.py
File "/home/syy/software/mmdetection2/mmdet/datasets/builder.py", line 20, in _concat_dataset
data_cfg['img_prefix'] = img_prefixes[i]
IndexError: list index out of range
- 1
- 2
- 3
- 4
- 5
python3 tools/train.py configs/cascade_rcnn_r50_fpn_1x.py
FileNotFoundError: [Errno 2] No such file or directory: '/home/syy/data/VOCdevkit/VOC2007/JPEGImages/0005873.xml'
(venv) syy@syy1996:~/software/mmdetection$
- 1
- 2
- 3
- 4
- 训练完成后就是测试:由于 voc格式的数据集在测试后并不会直接输出mAP, 需要保存测试结果另外计算mAP。
很重要的,以前一直理解错了,我以为测试集就是要没有经过标记的陌生图片,当用测试指令去测试单张图片时,是可以这样理解没错的,完全陌生的图片即可。如果是测试整个测试集里的图片的话,测试集和训练集的图片都是在JPEGImages里面,这里面的图片都是经过标记过的,只是按照一定的比例划分测试集和训练集。在test.txt文本中和trainval.txt中,储存的相应的图片的图片名,不包括路径也不包括后缀名。
对原始数据进行三个数据集的划分(训练集、测试集、验证集),也是为了防止模型过拟合。当使用了所有的原始数据去训练模型,得到的结果很可能是该模型最大程度地拟合了原始数据,当新样本出现,再使用该模型去预测,其预测结果可能还不如只使用一部分原始数据训练的模型。
验证集和测试集都没有被训练到,验证集的作用是调整超参数,监控模型是否发生过拟合,来决定是否停止训练。测试集的作用是评估最终模型的泛化能力。验证集多次使用,以调整参数。测试集只使用一次。验证集的缺陷:模型在一次次手动调参并继续训练后一步步逼近验证集,但是这可能只代表一部分非训练集,导致最终训练好的模型泛化能力不够。测试集为了具有泛化代表性,往往数据量很大。一般三个数据集的切分比例是6:2:2,一般验证集可以不用。
对测试集进行测试并保存结果:
#保存的结果为result.pkl
python3 tools/test.py configs/cascade_rcnn_r50_fpn_1x.py work_dirs/cascade_rcnn_r50_fpn_1x/epoch_12.pth --out ./result.pkl
- 1
- 2
- 在mmdetection目录下将出现result.pkl,接着,计算mAP,在终端输入以下命令,可以看到结果
python3 tools/voc_eval.py result.pkl ./configs/cascade_rcnn_r50_fpn_1x.py
- 1
- 备注:如果你出现了 label=self.cat2label的错误,可以参考错误处理
mmdetection训练coco格式数据集
最正确的参考链接:mmdetection训练coco格式数据集
- 如果要训练自己的数据集的话,使用coco格式比较方便,先可以用labelImg标注数据得到xml再转换为coco的json format。数据格式转换工具在这里(备注:这个链接里不仅有数据格式转换的工具还有数据增强的工具)或者这里
- COCO的 全称是Common Objects in Context,是微软团队提供的一个可以用来进行图像识别的数据集。COCO通过在Flickr上搜索80个对象类别和各种场景类型来收集图像。COCO数据集现在有3种标注类型:object instances(目标实例), object keypoints(目标上的关键点), 和image captions(看图说话),使用JSON文件存储。
- 然后创建文件夹,方式如下图,这样的命名与格式是为了避免修改程序麻烦。
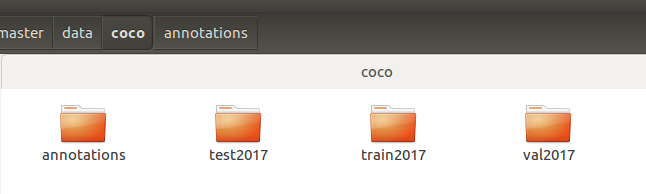
上图中的第一个文件夹annotations存放json文件, - 然后配置configs文件,这里使用的是faster_rcnn_r50_fpn_1x.py,于是可以在其内修改训练测试的数据地址、训练方式存储路径等。
- 注意的是,如果是直接使用coco数据集,就分别将jason和train的图片放进annotations和train2017,不用修改上面第三步中的那些路径,直接运行下面的指令,运行的时候会自动找到model zoo网站下载resnet-50的backbone参数和模型。
python3 tools/train.py configs/faster_rcnn_r50_fpn_1x.py
- 1
- 官方提供的所有代码都默认使用的是coco格式的数据集,所以不想太折腾的话就把自己的数据集转化成coco数据集格式。
正式步骤
- 数据格式的转换工具见上面。
- 制作好数据集之后,官方推荐coco数据集按照以下的目录形式存储:
mmdetection
├── mmdet
├── tools
├── configs
├── checkpoints存放权重文件
├── data
│ ├── coco
│ │ ├── annotations/instances_train2017.json
│ │ ├── train2017
│ │ ├── val2017
│ │ ├── test2017
一定要按照上面的这个格式,包括命名也要一模一样,大小写也要一模一样,这是因为源代码中就是这样命名的
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 推荐以软连接的方式创建data文件夹,下面是创建软连接的步骤
cd mmdetection
mkdir data
ln -s $ COCO_ROOT data
- 1
- 2
- 3
$COCO_ROOT 改为自己数据集的路径(写全)
- 训练前修改相关文件。我的数据集类别共有两个,官方提供的代码中都使用的是coco数据集,虽然我们自定义的数据集也已经转换成coco标准格式了,但是像class_name和class_num这些参数是需要修改的,不然跑出来的模型就不会是你想要的。
- 一些博客所提供的方法是按照官方给的定义coco数据集的相关文件,新建文件重新定义自己的数据集和类等,但是其实这是有风险的,我之前按照他们的方法走到最后发现会出现错误,所以最简单便捷且保险的方法是直接修改coco数据集定义文件(官方也是这样建议的)。
修改相关文件的第一步:
定义数据种类,需要修改的地方在mmdetection/mmdet/datasets/coco.py。把CLASSES的那个tuple改为自己数据集对应的种类tuple即可。
CLASSES = ('WaterBottle', 'Emulsion', )
- 1
修改相关文件的第二步:
在mmdetection/mmdet/core/evaluation/class_names.py修改coco_classes数据集类别,这个关系到后面test的时候结果图中显示的类别名称。例如:
def coco_classes():
return [
'WaterBottle', 'Emulsion'
]
- 1
- 2
- 3
- 4
修改相关文件的第三步:
修改configs/mask_rcnn_r101_fpn_1x.py(因为我的demo1.py中使用的这config)中的model字典中的num_classes、data字典中的img_scale和optimizer中的lr(学习率)。
num_classes=3,#类别数+1
img_scale=(640, 480),#输入图像尺寸的最大边与最小边,train val test这三处都要修改
optimizer = dict(type='SGD', lr=0.0025, momentum=0.9, weight_decay=0.0001) #当gpu数量为8时,lr=0.02;当gpu数量为4时,lr=0.01;我只要一个gpu,所以设置lr=0.0025
- 1
- 2
- 3
修改相关文件的第四步:
在mmdetection的目录下新建work_dirs文件夹
重要:若改动框架源代码后,一定要注意重新编译后再使用。类似这里修改了几个源代码文件后再使用train命令之前,先要编译
sudo python3 setup.py develop
- 1
- 执行上面的指令后才能使修改的mmdetection/mmdet/datasets/coco.py数据集文件生效
然后执行训练指令:
python3 tools/train.py configs/faster_rcnn_r50_fpn_1x.py --gpus 1 --validate --work_dir work_dirs
- 1
上面指令中的–validate表示是否在训练中建立checkpoint的时候对该checkpoint进行评估(evaluate)。如果使用是分布式训练,且设置了–validate,会在训练中建立checkpoint的时候对该checkpoint进行评估。(未采用分布式训练时,–validate无效,因为train_detector中调用的mmdet.apis._non_dist_train函数未对validate参数做任何处理)。
- 训练完之后work_dirs文件夹中会保存下训练过程中的log日志文件、每个epoch的pth文件(这个文件将会用于后面的test测试)
测试
有两个方法可以进行测试。
- 如果只是想看一下效果而不要进行定量指标分析的话,可以运行之前那个demo1.py文件,但是要改一下checkpoint_file的地址路径,使用我们上一步跑出来的work_dirs下的pth文件。例如:
checkpoint_file = 'work_dirs/epoch_100.pth'
- 1
- 使用test命令。例如:
python3 tools/test.py configs/mask_rcnn_r101_fpn_1x.py work_dirs/epoch_100.pth --out ./result/result_100.pkl --eval bbox --show
- 1
但是使用这个测试命令的时候会报错
使用demo.py来测试是可以出结果的,但是会出现”warnings.warn('Class names are not saved in the checkpoint’s ’ "的警告信息。使用这一步的test命令的时候会报错,程序中断,但是其实问题是一致的,应该是训练中保存下来的pth文件中没有CLASSES信息,所以show不了图片结果。因此需要按照下面的步骤修改下官方代码才可以。
修改:
修改mmdetection/mmdet/tools/test.py中的第29行为:
if show:
model.module.show_result(data, result, dataset.img_norm_cfg, dataset='coco')
- 1
- 2
输出log
此处的格式化输出称为检测评价矩阵(detection evaluation metrics)。
Average Precision (AP):
AP % AP at IoU=.50:.05:.95 (primary challenge metric)
APIoU=.50 % AP at IoU=.50 (PASCAL VOC metric)
APIoU=.75 % AP at IoU=.75 (strict metric)
AP Across Scales:
APsmall % AP for small objects: area < 322
APmedium % AP for medium objects: 322 < area < 962
APlarge % AP for large objects: area > 962
Average Recall (AR):
ARmax=1 % AR given 1 detection per image
ARmax=10 % AR given 10 detections per image
ARmax=100 % AR given 100 detections per image
AR Across Scales:
ARsmall % AR for small objects: area < 322
ARmedium % AR for medium objects: 322 < area < 962
ARlarge % AR for large objects: area > 962
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
在底层实现上是在mmdet.core.evaluation.coco_utils.py中,coco_eval方法通过调用微软的COCO API中的pycocotools包实现的。
通过构造COCOeval对象,配置参数,并依次调用evaluate、accumulate、summarize方法实现对数据集的测试评价。
此处摘录COCO数据集文档中对该评价矩阵的简要说明:
Average Precision (AP):
AP % AP at IoU=.50:.05:.95 (primary challenge metric)
APIoU=.50 % AP at IoU=.50 (PASCAL VOC metric)
APIoU=.75 % AP at IoU=.75 (strict metric)
AP Across Scales:
APsmall % AP for small objects: area < 322
APmedium % AP for medium objects: 322 < area < 962
APlarge % AP for large objects: area > 962
Average Recall (AR):
ARmax=1 % AR given 1 detection per image
ARmax=10 % AR given 10 detections per image
ARmax=100 % AR given 100 detections per image
AR Across Scales:
ARsmall % AR for small objects: area < 322
ARmedium % AR for medium objects: 322 < area < 962
ARlarge % AR for large objects: area > 962
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
源码解析
tools/train.py
- –resume_from是指定在某个checkpoint权重文件的基础上继续训练,可以在configs/*.py中配置;
- –validate是指是否在训练中建立checkpoint的时候对该checkpoint进行评估(evaluate);
- –launcher是指分布式训练的任务启动器(job launcher),默认值为none表示不进行分布式训练;
- 源码具体解析见源代码
train_detector方法非常简短,通过是否分布式训练作为分支判断
分别调用:_dist_train方法和_non_dist_train方法
tools/test.py负责对训练好的模型进行测试评估。
test.py的使用说明
- 输出到文件
在数据集上对训练好的模型进行测试,把模型的输出保存到文件:
python3 tools/test.py <CONFIG_FILE> <CHECKPOINT_FILE> --gpus <GPU_NUM> --out <OUT_FILE>
- 1
- 评估bbox等预测指标
把模型输出保存到results.pkl并评估bbox和segm的测试结果:
python3 tools/test.py configs/mask_rcnn_r50_fpn_1x.py <CHECKPOINT_FILE> --gpus 8 --out results.pkl --eval bbox segm
- 1
- 可视化预测结果
如果支持X Server,可以显示图形界面,则可以通过–show选项对测试图片进行显示输出:
python3 tools/test.py <CONFIG_FILE> <CHECKPOINT_FILE> --show
- 1
- tools/test.py源码具体解析见源代码处
single_test单设备测试
在该single_test方法中,实际通过以下的几个主要步骤对模型进行测试输出。
首先,通过torch.nn.Module.eval方法,将该模型设置进入评价模式(evaluation mode):
model.eval()
- 1
随后,通过遍历数据加载器data_loader读取数据,按照PyTorch的标准流程,取消梯度计算,输入数据运行模型,并取得模型输出(同时处理好X Server中图片目标检测结果可视化和Shell中进度条刷新事宜):
for i, data in enumerate(data_loader):
with torch.no_grad():
result = model(return_loss=False, rescale=not show, **data)
results.append(result)
if show:
model.module.show_result(data, result, dataset.img_norm_cfg,
dataset=dataset.CLASSES)
batch_size = data['img'][0].size(0)
for _ in range(batch_size):
prog_bar.update()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
In mmdetection, model components are basically categorized as 4 types:
- backbone: usually a FCN network to extract feature maps, e.g., ResNet.
- neck: the part between backbones and heads, e.g., FPN, ASPP.
- head: the part for specific tasks, e.g., bbox prediction候选框的预测 and mask prediction掩膜的预测.
- roi extractor: the part for extracting features from feature maps特征映射图, e.g., RoI Align.
We also write implement some general detection pipelines with the above components, such as SingleStageDetector and TwoStageDetector.
可以从SingleStageDetector和TwoStageDetector这两个类的实现中来阅读代码理解mmdetection框架中,基本目标检测模型的实现原理。
SingleStageDetector和TwoStageDetector均位于mmdet.models.detectors中,分别在single_stage.py和two_stage.py中实现。
- mmdet/models/detectors/single_stage.py实现了一个通用的基础单Stage目标检测模型,具体源码解析见源码处。
- mmdet/models/detectors/two_stage.py实现了一个通用的基础双Stage目标检测模型,具体源码解析见源码处。
实践中的一些注意事项
- 如果实践中修改了mmcv的相关代码,需要到mmcv文件夹下打开终端,激活mmdetection环境,并运行"pip install ."后才会生效(这样修改的代码才会同步到anaconda的mmdetection环境配置文件中)
- 若想使用tensorboard可视化训练过程,在config文件中修改log_config如下:
log_config = dict(
interval=10, # 每10个batch输出一次信息
hooks=[
dict(type='TextLoggerHook'), # 控制台输出信息的风格
dict(type='TensorboardLoggerHook') # 需要安装tensorflow and tensorboard才可以使用
])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
数据加载
- 遵循典型约定,使用Dataset和Dataloader用于多个工作人员的数据加载。Dataset返回与模型的forward方法的参数对应的数据项的字典dict。由于对象检测中的数据可能不是相同的大小(图像大小,gt bbox大小等),所以引入一种新的DataContainer类型mmcv来帮助收集和分发不同大小的数据。
模型
- mmdetection中,模型主要由四部分组成:
(1)backbone骨干网:通常是一个全卷积网络FCN用于提取feature map,比如ResNet网络。
(2)neck:连接backbone和head之间的部分,比如FPN。
(3)head:用于特定任务的部分,比如bbox预测,mask预测即掩码预测。
(4)ROI extractor提取器:用于从feature map即特征映射中提取特征的部分。比如ROI Align
mmdetection使用上述组件编写了一些通用检测流水线,如SingleStageDetector和TwoStageDetector。
使用基本组件构建模型
- 在一些基本流水线(例如:两级探测器)之后,可以通过配置文件定制模型结构。
- 如果想要实现一些新组件,例如路径聚合网络中的路径聚合FPN结构,用于实例分段,有如下两步:
第一步:创建一个新文件mmdet/models/necks/pafpn.py
from ..registry import NECKS
@NECKS.register
class PAFPN(nn.Module):
def __init__(self,
in_channels,
out_channels,
num_outs,
start_level=0,
end_level=-1,
add_extra_convs=False):
pass
def forward(self, inputs):
# implementation is ignored
pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
第二步:修改配置文件
原本的:
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5)
- 1
- 2
- 3
- 4
- 5
修改为:
neck=dict(
type='PAFPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5)
- 1
- 2
- 3
- 4
- 5
写一个新模型
- 要编写新的检测管道,需要继承BaseDetector。它定义了以下抽象方法:
extract_feat():给定图像批量形状(n,c,h,w),提取特征图。
forward_train():训练模式的前进方法。
simple_test():无需增强的单一规模测试。
aug_test():使用增强测试(多尺度,翻转)
迭代流水线(迭代管道)
- 对单机和多机采用分布式培训。若服务器有8个GPU。将启动8个进程,每个进程在单个GPU上运行。
- 每个进程都保持一个独立的模型、数据加载器和优化器,模型参数仅在开始时同步一次,在前向和后向传递之后,梯度将在所有GPU之间全部减少,优化器将更新模型参数,由于梯度全部减小,因此迭代后模型参数对所有过程保持相同。
源码解析
参考:
源码阅读笔记(2)–Loss
训练过程中具体的loss分为一下三类:
RPN_loss
bbox_loss
mask_loss
RPN_loss
rpn_loss的实现具体定义在mmdet/models/anchor_head/rpn_head.py
如下:
def loss(self,
cls_scores,
bbox_preds,
gt_bboxes,
img_metas,
cfg,
gt_bboxes_ignore=None):
losses = super(RPNHead, self).loss(
cls_scores,
bbox_preds,
gt_bboxes,
None,
img_metas,
cfg,
gt_bboxes_ignore=gt_bboxes_ignore)
return dict(
loss_rpn_cls=losses['loss_cls'], loss_rpn_bbox=losses['loss_bbox'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
具体的计算方式定义在其父类mmdet/models/anchor_heads/anchor_head.py,主要是loss和loss_single两个函数。
loss函数如下
def loss(self,
cls_scores,
bbox_preds,
gt_bboxes,
gt_labels,
img_metas,
cfg,
gt_bboxes_ignore=None):
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
assert len(featmap_sizes) == len(self.anchor_generators)
anchor_list, valid_flag_list = self.get_anchors(
featmap_sizes, img_metas)#通过这步获取到所有的anchor以及一个是否有效的flag(根据bbox是否超出图像边界来计算)。
label_channels = self.cls_out_channels if self.use_sigmoid_cls else 1
cls_reg_targets = anchor_target(
anchor_list,
valid_flag_list,
gt_bboxes,
img_metas,
self.target_means,
self.target_stds,
cfg,
gt_bboxes_ignore_list=gt_bboxes_ignore,
gt_labels_list=gt_labels,
label_channels=label_channels,
sampling=self.sampling)
if cls_reg_targets is None:
return None
(labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
num_total_pos, num_total_neg) = cls_reg_targets
num_total_samples = (
num_total_pos + num_total_neg if self.sampling else num_total_pos)
losses_cls, losses_bbox = multi_apply(
self.loss_single,
cls_scores,
bbox_preds,
labels_list,
label_weights_list,
bbox_targets_list,
bbox_weights_list,
num_total_samples=num_total_samples,
cfg=cfg)
return dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- loss函数主要做了两件事:一是生成anchor和对应的target。二是计算loss。
- 首先在此时rpn的输出为feature map中每个位置的anchor分类的score以及该anchor的bbox的修正值。要通过和gt计算loss来优化网络,gt是一堆人工标注的bbox,无法直接计算loss。所以要先获取到anchor然后将这些anchor和gt对比再分别得到正负样本以及对应的target,之后才能计算得到loss。
- 拿到了所有anchor之后就是和gt对比来区分正负样本以及生成label。通过定义在mmdet/core/anchor/anchor_target.py的anchor_target()实现。在这个函数中调用assigner将anchor 和gt关联起来,得到正样本和负样本,并用sampler将这些结果封装,方便之后使用,得到target之后,就是计算loss了。在mmdet/models/anchor_heads/anchor_head.py的loss_single中。如下:
def loss_single(self, cls_score, bbox_pred, labels, label_weights,
bbox_targets, bbox_weights, num_total_samples, cfg):
# classification loss
labels = labels.reshape(-1)
label_weights = label_weights.reshape(-1)
cls_score = cls_score.permute(0, 2, 3,
1).reshape(-1, self.cls_out_channels)
loss_cls = self.loss_cls(
cls_score, labels, label_weights, avg_factor=num_total_samples)
# regression loss
bbox_targets = bbox_targets.reshape(-1, 4)
bbox_weights = bbox_weights.reshape(-1, 4)
bbox_pred = bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
loss_bbox = self.loss_bbox(
bbox_pred,
bbox_targets,
bbox_weights,
avg_factor=num_total_samples)
return loss_cls, loss_bbox
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这里使用的loss就是CrossEntropyLoss交叉熵损失函数和SmoothL1Loss
bbox_loss
- 之前的rpn_loss是对候选框的第一次修正,这里的bbox_loss是第二次修正,两者的实际差别体现在分类上,在rpn阶段只分为两类(前景和背景),这里的分类是为N+1(包括真实类别+背景)。
- 具体定义在mmdet/models/bbox_heads/bbox_head.py
def loss(self,
cls_score,
bbox_pred,
labels,
label_weights,
bbox_targets,
bbox_weights,
reduce=True):
losses = dict()
if cls_score is not None:
losses['loss_cls'] = self.loss_cls(
cls_score, labels, label_weights, reduce=reduce)
losses['acc'] = accuracy(cls_score, labels)
if bbox_pred is not None:
pos_inds = labels > 0
if self.reg_class_agnostic:
pos_bbox_pred = bbox_pred.view(bbox_pred.size(0), 4)[pos_inds]
else:
pos_bbox_pred = bbox_pred.view(bbox_pred.size(0), -1,
4)[pos_inds, labels[pos_inds]]
losses['loss_bbox'] = self.loss_bbox(
pos_bbox_pred,
bbox_targets[pos_inds],
bbox_weights[pos_inds],
avg_factor=bbox_targets.size(0))
return losses
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 上面的代码可以看出和rpn loss相比,这里的loss定义要简单很多,因为这里只包含了rpn loss中实际计算loss的部分,但是这里也同样需要rpn中的assign和sample操作,两者的区别只是assign的输入不同,rpn的assign输入是该图所有的anchor,bbox部分assign的输入是rpn的输出,这里的loss和rpn中的计算方式一样。
mask loss
- mask计算loss之前也有一个获取target的步骤。如下:mmdet/models/mask_heads/fcn_mask_head.py
def get_target(self, sampling_results, gt_masks, rcnn_train_cfg):
pos_proposals = [res.pos_bboxes for res in sampling_results]
pos_assigned_gt_inds = [
res.pos_assigned_gt_inds for res in sampling_results
]
mask_targets = mask_target(pos_proposals, pos_assigned_gt_inds,
gt_masks, rcnn_train_cfg)
return mask_targets
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 上面的代码可以看出这里获取target就更简单,通过定义在mmdet/core/mask/mask_target.py的mask_target()(如下代码)取到和proposals相同大小的mask即可。
def mask_target(pos_proposals_list, pos_assigned_gt_inds_list, gt_masks_list,
cfg):
cfg_list = [cfg for _ in range(len(pos_proposals_list))]
mask_targets = map(mask_target_single, pos_proposals_list,
pos_assigned_gt_inds_list, gt_masks_list, cfg_list)
mask_targets = torch.cat(list(mask_targets))
return mask_targets
def mask_target_single(pos_proposals, pos_assigned_gt_inds, gt_masks, cfg):
mask_size = cfg.mask_size
num_pos = pos_proposals.size(0)
mask_targets = []
if num_pos > 0:
proposals_np = pos_proposals.cpu().numpy()
pos_assigned_gt_inds = pos_assigned_gt_inds.cpu().numpy()
for i in range(num_pos):
gt_mask = gt_masks[pos_assigned_gt_inds[i]]
bbox = proposals_np[i, :].astype(np.int32)
x1, y1, x2, y2 = bbox
w = np.maximum(x2 - x1 + 1, 1)
h = np.maximum(y2 - y1 + 1, 1)
# mask is uint8 both before and after resizing
target = mmcv.imresize(gt_mask[y1:y1 + h, x1:x1 + w],
(mask_size, mask_size))
mask_targets.append(target)
mask_targets = torch.from_numpy(np.stack(mask_targets)).float().to(
pos_proposals.device)
else:
mask_targets = pos_proposals.new_zeros((0, mask_size, mask_size))
return mask_targets
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 这部分的loss定义如下代码,也很简单,也是使用的交叉熵损失函数CrossEntropyLoss。
def loss(self, mask_pred, mask_targets, labels):
loss = dict()
if self.class_agnostic:
loss_mask = self.loss_mask(mask_pred, mask_targets,
torch.zeros_like(labels))
else:
loss_mask = self.loss_mask(mask_pred, mask_targets, labels)
loss['loss_mask'] = loss_mask
return loss
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如上,虽然是有三部分的loss,分别为rpn loss和bbox loss和mask loss。但可以发现这三部分loss都差不多。
cascade-rcnn
mmdetection集成了很多的目标检测模型,表现好的模型有cascade rcnn。
cascade rcnn模型原理
在two-satge模型中,会预测一些目标对象的候选框,这个候选框与真实值之间一般通过交叉面积iou的计算来判断该框是否为正样本,即要保留的候选框。常见的iou参数设置是0.5。但是0.5参数的设置也会导致很多无效的对象。如下作图所示,当值为0.5时是左边的图,值为0.7时是右边的图,明显可以看出,值为0.5时图中有很多无效对象,值为0.7时图会更清晰些。但是设置为0.7的缺点是不可避免会漏掉一些候选框,特别是微小目标,同时由于正样本数目过少,会导致容易出现过拟合的现象。
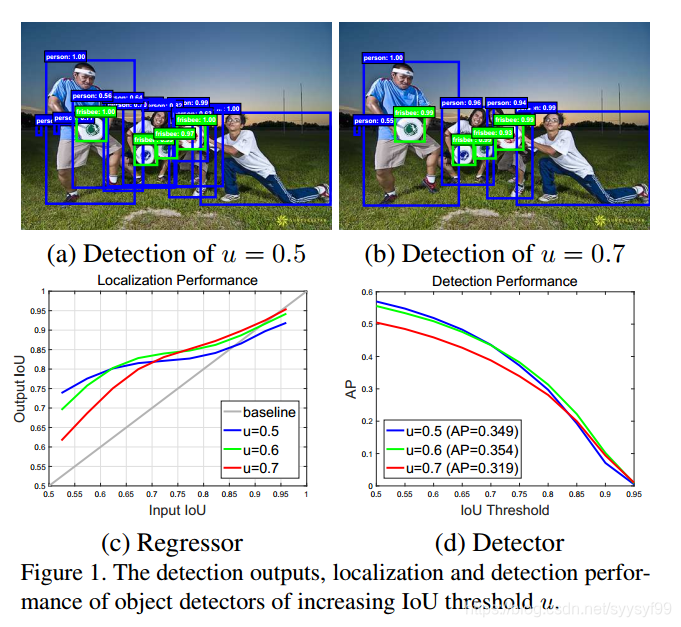
cascade rcnn的重点就是解决这个iou参数设置为问题。它设置了一个级联检测的方法来实现。如下图d如所示
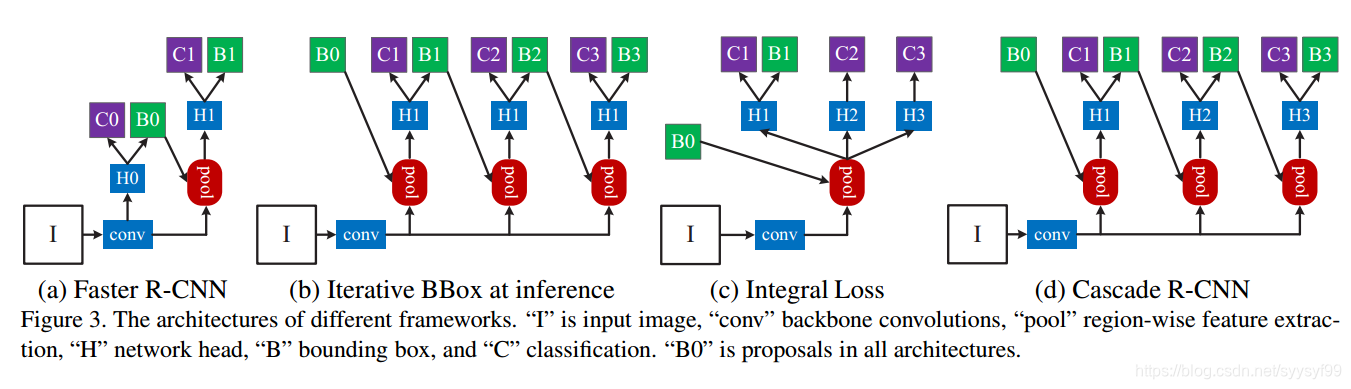
上图中的d图具有级联特性,与b图相比,其每次的iou参数都是不一样的,正常设置为0.5 /0.6 /0.7。通过级联特性可以实现对候选框的级联优化检测。
cascade rcnn的使用
- 在mmdetection中,cascade rcnn是已经配置好了的,可以看到存在cascae rcnn的配置代码。
- 如果要在mmdetaction中使用cascade rcnn,如下,创建一个demo.py,几行代码即可实现。
'''
执行该脚本就可以查看单张检测图片的检测效果和一个目录下所有图片的检测效果
只要更换congig和weights文件就能用不同的网络检测。
该mmdetection做了封装,build_detector函数搭建模型,
inference_detector函数负责推理检测
将不同的模块封装为backbone/neck/head等部分,
在config中写入,通过读取配置,注册模块,进行封装,然后高级调用搭建网络
如果要训练自己的数据集的话,使用coco格式比较方便,先可以用labelImg标注数据得到xml再转换为coco的json format
'''
#ipdb库是为了debug时使用,导入库后就通过设置breakpoint即使用方法ipdb.set_trace()来debug,ipdb是需要安装的
import ipdb
import sys,os,torch,mmcv
from mmcv.runner import load_checkpoint
#下面这句import执行时定位且调用Registry执行了五个模块的注册
'''
registry
功能:注册模块占位符,在程序运行之前先注册相应的模块占位,便于在config文件直接对相应的模块进行配置填充.
五大类:
BACKBONES = Registry('backbone')
NECKS = Registry('neck')
ROI_EXTRACTORS = Registry('roi_extractor')
HEADS = Registry('head')
DETECTORS = Registry('detector')
'''
from mmdet.models import build_detector
from mmdet.apis import inference_detector,show_result
if __name__=='__main__':
#debug语句
#ipdb.set_trace()
'''
mmcv.Config.fromfile
封装方法:配置cfg方式不是直接实例化Config类,而是用其fromfile方法
该函数返回的是Config类:Config(cfg_dict, filename=filename);
传入的参数cfg_dict是将配置文件(如mask_rcnn_r101_fpn_1x.py)用一个大字典进行封装,
内嵌套小字典就是py文件的dict,
最后是k-v,对应每个选项;filename就是py配置文件的路径名
'''
# 下面的模型配置文件设置为自己需要的,在configs文件夹下提供了很多
cfg=mmcv.Config.fromfile('configs/cascade_rcnn_r101_fpn_1x.py')
#inference不设置预训练模型
cfg.model.pretrained=None
#inference只传入cfg的model和test配置,其他的都是训练参数
model=build_detector(cfg.model,test_cfg=cfg.test_cfg)
'''
下面的路径改为下载好的权重文件存放的路径,权重文件要和config路径文件名相匹配
权重文件下载的链接:
https://github.com/open-mmlab/mmdetection/blob/master/MODEL_ZOO.md
load_checkpoint(model,filename,map_location=None,strict=False,logger=None)
这个函数实现的功能是从url链接中或者文件中加载模型,实现过程是:
第一步先用torch.load将path文件加载到变量checkpoint,
第二步从中提取权值参数存为state_dict,因为还有可能pth中存在模型后者优化器数据
第三步load_state_dict将数据加载
'''
_ = load_checkpoint(model, 'weights/cascade_rcnn_r101_fpn_1x_…….pth')#名称没有写全
#print(model)#展开模型
#测试单张图片,路径要按照实际修改
img=mmcv.imread('/py/pic/2.jpg')
result=inference_detector(model,img,cfg)
show_result(img,result)
#test a list of folder,路径按照实际修改
path='your_path'
imgs=os.listdir(path)
for i in range(len(ings)):
imgs[i]=os.path.join(path,imgs[i])
for i,result in enumerate(inference_detector(model,imgs,cfg,device='cuda:0')):
print(i,imgs[i])
show_result(imgs[i],result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- cascade rcnn的检测效果没有faster rcnn的检测效果好。
focal loss
mmdetection提供的config文件里只在retinanet中打开了focal loss的功能,原因是one stage算法使用密集anchor一步回归的方法,其中正负样本非常不均衡,所以focal loss损失函数主要正负样本不均衡以及难分易分样本权值一样的问题(这里与OHEM的区别在于OHEM主要在于主要集中在难分样本上,不考虑易分样本)
解锁mmdetection中所有模型的focal loss
- 这里只激活RPN阶段的focal loss。因为rcnn阶段,rpn已经初步过滤了样本,可以采用OHEM策略。
- 在mmdet/models/anchor_heads/anchor_head.py的AnchorHead类中第44行use_focal_loss设置为True即可激活所有模型的focal loss。然后再在config训练文件中的train_cfg的rpn的最后加入如下代码:
smoothl1_beta=0.11,
gamma=2.0,
alpha=0.25,
allowed_border=-1,
pos_weight=-1,
debug=False
- 1
- 2
- 3
- 4
- 5
- 6
- 现在anchor_head.py若没有use_focal_loss这个语句,使用focal loss的方法是直接添加loss_cls = dict(type=‘FocalLoss’…)即可
所属网站分类: 技术文章 > 博客
作者:集天地之正气
链接:https://www.pythonheidong.com/blog/article/53032/db33b5a4e8675433d660/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力