

四、【机器学习作业】多元分类与神经网络(python版ex3)
发布于2019-08-22 16:51 阅读(1904) 评论(0) 点赞(21) 收藏(3)
学习完了机器学习的神经网络的课程,现在来将所学记录下来。
(一)多元分类问题
在上一篇博客中学习了逻辑回归,并使用它解决了简单的 0/1 分类问题。在这篇博客中,首先尝试使用 逻辑回归 来解决 多分类问题( 手写字符识别 )。在学习完神经网络后,再用神经网络的知识来解决手写字符识别的问题。
利用逻辑回归算法进行手写字符识别
在这个实验中用到的是吴恩达机器学习课程提供的数据集,共有5000个数据,从0到9每个数字有500个数据组成,每个数据都是一张20×20像素的灰度图,因此每张图具有400个像素点。数据集用一个矩阵表示,是5000×400的规模。
首先,载入需要的库:
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
import scipy.io as scio #引入读取.mat文件的库
- 1
- 2
- 3
- 4
载入数据集,并可视化随机的100个训练样本:
plt.ion() # 打开交互模式
#输入特征的维度,每张数字图片20*20=400
input_layer_size=400
#10个标签,注意“0”对应第十个标签, 1-9一次对应第1-9个标签
num_labels=10
#读取训练集:包括两部分,输入特征和标签
data=scio.loadmat('ex3data1.mat')
#提取输入特征 5000*400的矩阵,5000个训练样本,每个样本特征维度为400,一行代表一个训练样本
X=data['X']
#提取标签 data['y']是一个5000*1的2维数组,利用flatten()将其转换为有5000个元素的一维数组
y=data['y'].flatten()
#训练样本的数量
m = y.size
# 随机抽取100个训练样本 进行可视化
rand_indices = np.random.permutation(range(m)) #获取0-4999 5000个无序随机索引
selected = X[rand_indices[0:100], :] #获取前100个随机索引对应的整条数据的输入特征
#调用可视化函数 进行可视化
display_data(selected)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
其中,Matplotlib的显示模式默认为阻塞(block)模式,因此若想动态显示图像,则需要使用交互(interactive)模式。阻塞模式是指在程序中遇到plt.show()程序即停止,交互模式则会继续运行下去。
在交互模式下:
1、plt.plot(x)或plt.imshow(x)是直接出图像,不需要plt.show()
2、如果在脚本中使用ion()命令开启了交互模式,没有使用ioff()关闭的话,则图像会一闪而过,并不会常留。要想防止这种情况,需要在plt.show()之前加上ioff()命令。
在阻塞模式下:
1、打开一个窗口以后必须关掉才能打开下一个新的窗口。这种情况下,默认是不能像Matlab一样同时开很多窗口进行对比的。
2、plt.plot(x)或plt.imshow(x)是直接出图像,需要plt.show()后才能显示图像。
可视化函数的程序:
#可视化数据集
def display_data(x):
(m, n) = x.shape #100*400
example_width = np.round(np.sqrt(n)).astype(int) #每个样本显示宽度:round()四舍五入到个位,并转换为int
example_height = (n / example_width).astype(int) #每个样本显示高度:并转换为int
#设置显示格式 100个样本 分10行 10列显示
display_rows = np.floor(np.sqrt(m)).astype(int)#floor(x),其功能是“向下取整”,下取整是直接去掉小数部分。
display_cols = np.ceil(m / display_rows).astype(int)#ceil(x),其功能是向上取整。
# 待显示的每张图片之间的间隔
pad = 1
# 显示的布局矩阵 初始化值为-1
display_array = - np.ones((pad + display_rows * (example_height + pad),
pad + display_rows * (example_height + pad)))
# Copy each example into a patch on the display array
curr_ex = 0
for j in range(display_rows):
for i in range(display_cols):
if curr_ex > m:
break
# Copy the patch
# Get the max value of the patch
max_val = np.max(np.abs(x[curr_ex]))
display_array[pad + j * (example_height + pad) + np.arange(example_height),
pad + i * (example_width + pad) + np.arange(example_width)[:, np.newaxis]] = \
x[curr_ex].reshape((example_height, example_width)) / max_val
curr_ex += 1
if curr_ex > m:
break
# 显示图片
plt.figure()
plt.imshow(display_array, cmap='gray', extent=[-1, 1, -1, 1])
plt.axis('off')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
可视化数据集的结果:
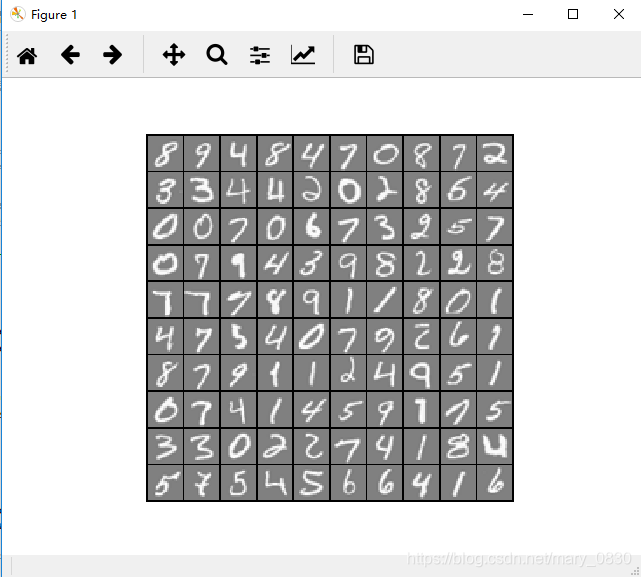
逻辑函数的代价函数以及梯度下降的代码:
#sigmoid函数
def sigmoid(z):
return 1/(1+np.exp(-z))
#逻辑回归的假设函数
def h(X,theta):
return sigmoid(np.dot(X,theta))##X: m*(n+1) theta:(n+1,) 内积返回结果(m*1,)
#计算代价函数
def compute_cost(theta,X,y,lmd):
m=y.size#样本数
cost=0
myh=h(X,theta)#得到假设函数
term1=-y.dot(np.log(myh))#y:(m*1,) log(myh):(m*1,) 得到一个数值
term2=(1-y).dot(np.log(1-myh))#1-y:(m*1,) log(1-myh):(m*1,) 得到一个数值
term3=theta[1:].dot(theta[1:])*lmd #正则化项 注意不惩罚theta0 得到一个数值 thrta[1:] (n,)
cost=(1/m)*(term1-term2)+(1/(2*m))*term3
return cost
#计算梯度值
def compute_grad(theta,X,y,lmd):
m=y.size#样本数
grad=np.zeros(theta.shape)#梯度是与参数同维的向量
myh=h(X,theta)#得到假设函数值
reg=(lmd/m)*theta[1:] #reg(n,)
grad=(myh-y).dot(X)/m # grad:(n+1,)
grad[1:]+=reg
return grad
def Ir_cost_function(theta,X,y,lmd):
cost=compute_cost(theta,X,y,lmd)
grad=compute_grad(theta,X,y,lmd)
return cost,grad
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
编写代码做正则化逻辑回归算法的简单测试:
theta_t=np.array([-2,-1,1,2])#初始化假设函数的参数 假设有4个参数
X_t=np.c_[np.ones(5),np.arange(1,16).reshape(3,5).T/10]#输入特征矩阵 5个训练样本
y_t=np.array([1,0,1,0,1])#标签 做2分类
lmda_t=3#正规化惩罚性系数
cost,grad=Ir_cost_function(theta_t,X_t,y_t,lmda_t) #传入代价函数
np.set_printoptions(formatter={'float':'{:0.6f}'.format})
print('Cost:{:0.7f}'.format(cost))
print('Gradients:\n{}'.format(grad))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
实验结果:

训练逻辑回归的多分类器的训练过程:
用逻辑回归做多分类,相当于做多次2分类,每一次把其中一个类别当作正类,其余全是负类。手写字符识别属于10分类,则需要做10次2分类。
import scipy.optimize as opt #高级优化函数的包
#定义一个优化函数 实际上调用的是Python内置的高级优化函数
#可以把它想象成梯度下降法 但是不用手动设置学习率
''' fmin_cg优化函数 第一个参数是计算代价的函数 第二个参数是计算梯度的函数 参数x0传入初始化的theta值
args传入训练样本的输入特征矩阵X,对应的2分类新标签y,正则化惩罚项系数lmd
maxiter设置最大迭代优化次数
'''
def optimizeTheta(theta,X,y,lmd):
res=opt.fmin_cg(compute_cost,fprime=compute_grad,x0=theta,\
args=(X,y,lmd),maxiter=50,disp=False,full_output=True)
return res[0],res[1]
def one_vs_all(X,y,num_labels,lmd):
(m,n)=X.shape#m为训练样本数 n为原始输入特征数
all_theta=np.zeros((num_labels,n+1)) #存放十次2分类的 最优化参数
initial_theta=np.zeros(n+1) #每一次2分类的初始化参数值
X=np.c_[np.ones(m),X]#添加一列特征值为1
for i in range(num_labels):
print('Optimizing for handwritten number {}...'.format(i))
iclass=i if i else 10#数字0属于第十个类别
logic_Y=np.array([1 if x==iclass else 0 for x in y])#设置每次2分类的新标签
itheta,imincost=optimizeTheta(initial_theta,X,logic_Y,lmd)
all_theta[i,:]=itheta
print('Done')
return all_theta #返回十次2分类的 最优化参数
lmd=0.1#正则化惩罚项系数
all_theta=one_vs_all(X,y,num_labels,lmd)#返回训练好的参数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
实验结果:

编写代码做分类器的准确性测试:
def predict_one_vs_all(all_theta, X):
m = X.shape[0] #shape[0]返回2维数组的行数,即样本数。
p = np.zeros(m) #存储分类器预测的类别标签
X = np.c_[np.ones(m), X] #增加一列1 X:5000*401
Y=h(X,all_theta.T) #all_theta:10*401 Y:5000*10 每一行是每一个样本属于10个类别的概率
p=np.argmax(Y,axis=1) #找出每一行最大概率所在的位置
p[p==0]=10 #如果是数字0的话 他属于的类别应该是10
return p
pred = predict_one_vs_all(all_theta, X) #分类器的预测类别
print('Training set accuracy: {}'.format(np.mean(pred == y)*100))#与真实类别进行比较,得到准确率
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
预测出的准确性的实验结果:

(二)神经网络模型(初识)
(1) 简单模型 vs 复杂模型
简单模型—— 线性回归模型、逻辑回归模型,其优点是容易理解、可解释性较强,但是为了达到相对好的预测效果,我们通常会考虑对原始特征进一步抽象,增加更多的特征项来弥补模型在处理非线性问题上的缺陷。

假设现在有一个预测房价的任务,首先抽取出100个不相关的特征属性(比如,房子大小、房间个数、使用年限等),然后想要尝试使用逻辑回归(LR)模型。我们知道LR是一种广义的线性模型,为了提高LR对非线性问题的处理能力,要引入多项式特征,为了充分考虑特征关联,通常也会执行特征之间交叉组合。若仅考虑二次项,也就是只考虑特征两两组合,这样也会得到接近5000个组合特征,若再考虑三次项,四此项呢?组合特征的数量会越来越庞大,空间会膨胀,项数过多可能会带来的问题:模型容易过度拟合、在处理这些项时计算量过大。
所以逻辑回归问题不是解决包含大量特征的数据分类问题好办法,则引入了神经网络。
复杂模型—— 神经网络,其缺点就是相对难理解、可解释性不强;优点是这种模型一般不需要像LR那样在特征获取上下这么大的功夫,它可以通过隐层神经元对特征不断抽象,从而自动发觉特征关联,进而使得模型达到良好的表型。
(2)介绍神经网络模型(前馈)
神经网络模型是参考生物神经网络处理问题的模式而建立的一种复杂网络结构。在神经网络中,神经元又称激活单元,每个激活单元都会采纳大量的特征作为输入,然后根据自身特点提供一个输出,供下层神经元使用。logistic神经元的图示如下:
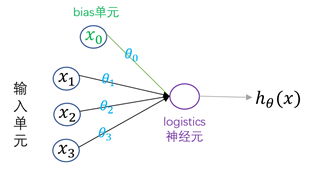
其中,表示偏置项,它通常作为模型(单元)的固有属性而被添加到模型中,一般取值为1;是模型参数,也称为权重,起到放大或缩小输入信息的作用;而logistics神经元会将输入信息进行汇总并添加一个非线性变换,从而获得神经元输出。神经网络就是由多个这样的logistics神经元按照不同层次组织起来的网络,每一层的输出都作为下一层的输入,如下图:
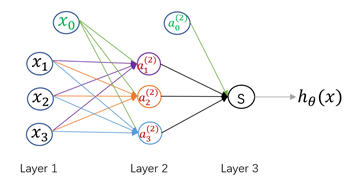
这是一个包含一个隐藏层的神经网络结构。其中,Layer1为输入层,Layer2为隐藏层,Layer3为输出层。
(3)神经网络模型的建立
下面用数学符号来描述上述的神经网络模型。首先进行符号的约定,如下:
:表示第层第个神经元的激活值
:表示完成从第层向第层映射,所使用的权重矩阵。即层数为。
该式子中,:表示第层第个神经元,:表示第层第个神经元。
所以, 从该计算过程可以看出,神经网络在对样本进行预测时,是从第一层(输入层)开始,层层向前计算激活值,直观上看这是一种层层向前传播特征或者说层层向前激活的过程,最终计算出,这个过程称之为前向传播(forward propagation)。激活函数的作用可以看作是从原始特征学习出新特征,或者说是将原始特征从低维空间映射到高维空间。
使用向量化的方式,可以表示成:
这也是前馈神经网络从输入变量获得输出结果的数学表达式。
(4)神经网络模型的理解
为了更加清晰的认识神经网络,我们可以将上图中的Layer1遮住,那么剩下的Layer2和Layer3就像是一个LR(逻辑回归)模型,其与真正LR的不同在于输入向量的差异:普通LR的输入向量是原始特征向量,而该模型的输入是(经过学习后得到的特征属性)。
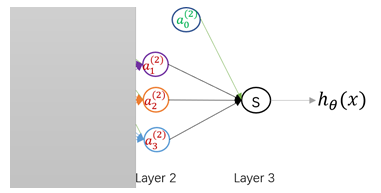
因此,对神经网络更直观的理解就是,它通过大量的隐藏层网络将输入向量进行一步又一步的抽象(加权求和+非线性变换),生成能够更加容易解释模型的复杂新特征,最后将这些强大的新特征传入输出层获得预测结果。就像,单层神经元(无隐藏层)无法表示逻辑同或运算,但是若加上一个隐藏层结构就可以轻松表示出逻辑同或运算!
对于一张输入图片,需要识别其属于行人、轿车、摩托车或者卡车中的一个类型,就是一个多类分类的问题。神经网络模型也可以处理多分类任务。与二分类不同的是,多分类模型最后的输出层将是一个K维的向量,K表示类别数。用神经网络表示如下:
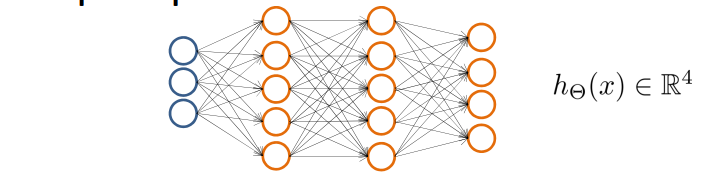
可以说,神经网络就是由一个个逻辑回归模型连接而成的,它们彼此作为输入和输出。输出结果可表示为:
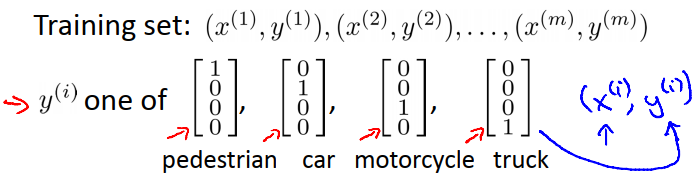
用0与1的组合成的向量代替1,2,3,4:
神经网络比直接使用Logistic回归的优势在于:
如果给定基础特征的数量为100,那么在利用Logistic回归解决复杂分类问题时会遇到特征项爆炸增长,造成过拟合以及运算量过大问题。而对于神经网络,可以通过隐藏层数量和隐藏单元数量来控制假设函数的复杂程度,并且在计算时只计算一次项特征变量。其实本质上来说,神经网络是通过这样一个网络结构隐含地找到了所需要的高次特征项,从而化简了繁重的计算。
(5)常见的神经网络架构
神经网络看起来复杂多样,但是这么多架构可以分为三类:前馈神经网络,循环神经网络,对称连接网络。
- 前馈神经网络:
这是实际应用中最常见的神经网络类型。第一层是输入层,最后一层是输出层。如果有多个隐藏层,我们称之为“深度”神经网络。他们计算出一系列改变样本相似性的变换。各层神经元的活动是前一层活动的非线性函数。 - 循环神经网络:
循环网络在他们的连接图中定向了循环,这意味着你可以按照箭头回到你开始的地方。他们可以有复杂的动态,使其很难训练。他们更具有生物真实性。循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。 - 对称连接网络:
对称连接网络有点像循环网络,但是单元之间的连接是对称的(它们在两个方向上权重相同)。比起循环网络,对称连接网络更容易分析。这个网络中有更多的限制,因为它们遵守能量函数定律。没有隐藏单元的对称连接网络被称为“Hopfield 网络”。有隐藏单元的对称连接的网络被称为玻尔兹曼机。
(三)神经网络模型(进阶)
神经网络的学习与其他模型的学习一样,首先需要确定其代价函数,然后对参数进行估计,最后确定模型用于预测。
(1)代价函数
在分类问题,我们知道使用交叉熵误差函数而不是平方和误差函数,会使得训练速度更快,同时也提升了泛化能力。对于二元分类问题来说,神经网络可以使用单一的logistics神经元作为输出,同时也可以使用两个softmax神经元作为输出。对于多分类问题,同样有两方面的思考:
- 对于类别之间有交集的多分类问题,我们可以将多分类看成多个相互独立的二元分类问题,这时我们使用logistics输出神经元,而误差函数采用交叉熵误差函数。
- 对于类别之间互斥的多分类问题,通常使用softmax输出神经元,误差函数同样采用交叉熵误差函数。
首先假设神经网络的输出单元有个,而网络的第个神经元的输出我们用表示,同时其目标用表示,基于两种不同的考量角度,代价函数由下面给出:
- 类别之间有交集的多分类问题
对于此类问题,可以将多分类看成多个相互独立的二元分类问题,每个输出神经元都有两种取值,并且输出神经元之间相互独立,故给定输入向量时,目标向量的条件概率分布为:取似然函数的负对数,可以得到下面的误差函数: - 类别之间互斥的多分类问题
对于该问题,我们通常用 “1-of-K” 的表示方式来表示类别,从而网络的输出可以表示为:,因此误差函数为:而网络输出的计算通常使用Softmax函数:这里,表示第个样本第个输出单元的输出值,是一个概率值。对于正则化项,依然采用正则项,将所有参数(不包含bias项的参数)的平方和相加,也就是不把时的参数加进来。
(2)反向传播算法
绝大部分的训练算法都会涉及到用迭代的方式最小化代价函数和一系列的权值更新操作。具体来说,一般的训练算法可以分为两个阶段:
第一阶段:求解代价函数关于权值(参数)的导数。(bp)
第二阶段:用得到的导数进一步计算权值的调整量。(梯度下降等优化算法)
反向传播(bp)算法主要应用第一阶段,它能非常高效的计算这些导数。
- 代价函数数学公式推导:
未正则化的代价函数公式:
正则化的代价函数公式:
k:输出单元个数即classes个数
L:神经网络总层数
:第L层的单元数(不包括偏置单元)
:表示第L层边上的权重即参数
我们的目标是找出,使得的值最小。最先想到的方法便是求偏导(其中),可以由公式直接给出,关键就是如何计算其偏导。
- 代价函数导数的计算:
使用之前提到的神经网络结构图,在这部分通过详细的讲解来推导出代价函数导数的计算公式。
首先进行符号的约定:
| 符号 | 含义 |
|---|---|
| 第个输出神经元的输出 | |
| 第个输出神经元的目标 | |
| 第个神经元输入的加权求和 | |
| 第个神经元的激活 |
首先考虑一个简单的线性模型,其中输出是输入变量的线性组合:给定一个特定的输入模式,则其代价函数为:则这个代价函数关于参数的梯度为:此时代价函数的梯度可以表示为与链接的输出端相关联"误差信号"和与链接输入端相关联的变量的乘积。
接下来计算神经网络中代价函数关于参数的梯度。首先,因为代价函数中只有加权求和项与参数,故可以通过链式求导法则得到: 同上面线性函数的表示方式,我们通常引入新的符号: 用其来表示与链接的输出端相关联"误差(cost)信号",此时代价函数关于参数的梯度可以写成: 这个式子得出结论:要求的导数 = 权值输出端单元的误差项 * 权值输入端单元的激活值。因为每个结点的激活值在前馈阶段已经得出,因此,为了计算导数,只需要计算网络中每个隐藏层结点和输出结点的"误差(cost)信号"即可。
那么,每个隐藏层结点和输出结点的"误差(cost)信号"怎么计算?
对于输出结点来说,第k个结点的误差等于该结点的输出值与目标值之间的差:
- 输出结点(线性激活函数)误差 :
- 为了计算隐藏层结点的误差值,再次使用链式法则:
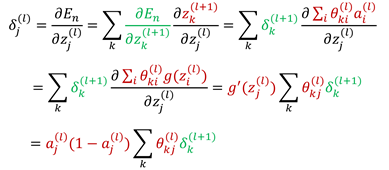
可见,层第个结点的误差取决于当前结点的激活值、层结点的误差、以及层结点于当前结点的链接权值。这种从输出到输入推导误差的方式叫做误差的反向传播。
首先,通过正向传播,找到所有隐层神经元和输出单元的激活;使用(7)式得到所有输出单元的误差;
然后,利用误差的反向传播公式(8),获得网络中所有隐层神经元的误差;
最后,使用公式(6)计算得到误差函数相对于所有权值的导数。
需要注意的是,上述得到的导数只是对于单个样本而言的,因为开始时设定了训练样本只有一个 (x,t);若使用多个训练样本,可以通过加和的形式求的导数:
在上面的推导中,我们隐式地假设网络中的每个隐含单元或输入单元都有相同的激活函数。
详细的推导过程请参考 https://blog.csdn.net/mary_0830/article/details/99182023
(四)用python实现神经网络
知道神经网络的工作原理,现在可以着手实现一个神经网络。
根据sigmoid 函数以及其求导得到对应的python代码:
# coding: utf-8
import numpy as np
def tanh(x):#双曲函数
return np.tanh(x)
def tanh_deriv(x):
"""tanh的导数"""
return 1.0 - np.tanh(x) * np.tanh(x)
def logistic(x):
return 1.0 / (1 + np.exp(-x))
def logistic_deriv(x):
"""逻辑函数的导数"""
fx = logistic(x)
return fx * (1 - fx)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
设计神经网络的类结构:
class NeuralNetwork(object):
def __init__(self, layers, activation='tanh'):
pass
def fit(self, X, Y, learning_rate=0.2, epochs=10000):
pass
def predict(self, x);
pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在构造函数中,需要确定神经网络的层数,每层的个数,从而确定单元间的权重规格和单元的偏向:
def __init__(self, layers, activation='logistic'):
"""
:param layers: 层数,如[4, 3, 2] 表示两层len(list)-1,(因为第一层是输入层,有4个单元),
第一层有3个单元,第二层有2个单元
:param activation:
"""
if activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
elif activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_deriv
# 初始化随机权重
self.weights = []
for i in range(len(layers) - 1):
tmp = (np.random.random([layers[i], layers[i + 1]]) * 2 - 1) * 0.25
self.weights.append(tmp)
# 偏向随机初始化
self.bias = []
for i in range(1, len(layers)):
self.bias.append((np.random.random(layers[i]) * 2 - 1) * 0.25)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
利用 np.random.random([m, n]) 来创建一个 m x n 的矩阵。在这个神经网络的类中,初始化都随机 -0.25 到 0.25 之间的数。
在神经网络的训练中,需要先设定一个训练的终止条件,即达到预设一定的循环次数就停止训练。每次训练是从样本中随机挑选一个实例进行训练,将这个实例的预测结果和真实结果进行对比,再进行反向传播得到各层的误差,然后再更新权重和偏向:
def fit(self, X, y, learning_rate=0.2, epochs=10000):
X = np.atleast_2d(X)
y = np.array(y)
# 随即梯度
for k in range(epochs):
i = np.random.randint(X.shape[0])
a = [X[i]] # 随即取某一条实例
for j in range(len(self.weights)):
a.append(self.activation(np.dot(a[j], self.weights[j]) + self.bias[j] ))
errors = y[i] - a[-1]
deltas = [errors * self.activation_deriv(a[-1]) ,] # 输出层的误差
# 反向传播,对于隐藏层的误差
for j in range(len(a) - 2, 0, -1):
tmp = np.dot(deltas[-1], self.weights[j].T) * self.activation_deriv(a[j])
deltas.append(tmp)
deltas.reverse()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
参数 learning_rate 表示学习率, epochs 表示设定的循环次数。
预测,就是将测试实例从输入层传入,通过正向传播,最后返回输出层的值即可:
def predict(self, row):
a = np.array(row) # 确保是 ndarray 对象
for i in range(len(self.weights)):
a = self.activation(np.dot(a, self.weights[i]) + self.bias[i])
return a
- 1
- 2
- 3
- 4
- 5
下面编写手写数字识别的代码:
首先,构造神经网络,并载入数据集:
nn = NeuralNetwork(layers=[64, 100, 10])
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
- 1
- 2
- 3
- 4
- 5
- 6
数据集来自 sklearn ,其中由1797个图像组成。神经网络的输入层将有 64 个输入单元,分类结果是 0~9 ,因此输出层有10个单元。
拆分成训练集和数据集,分类结果离散化:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
# 拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 分类结果离散化
labels_train = LabelBinarizer().fit_transform(y_train)
labels_test = LabelBinarizer().fit_transform(y_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
获取训练集进行训练:
nn.fit(X_train, labels_train)
- 1
获取测试结果,并打印对比的结果:
from sklearn.metrics import confusion_matrix, classification_report
# 收集测试结果
predictions = []
for i in range(X_test.shape[0]):
o = nn.predict(X_test[i] )
predictions.append(np.argmax(o))
# 打印对比结果
print (confusion_matrix(y_test, predictions) )
print (classification_report(y_test, predictions))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
利用训练集对模型进行测试,得到 confusion_matrix 的打印结果:
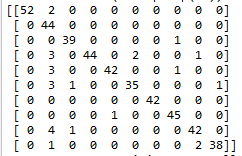
行列中,表示预测值与真实值的情况。当预测值为0,真实值也为0,那么就在 [0][0] 计数 1。因此这个对角线计数越大表示预测越准确。
分类报告打印结果:
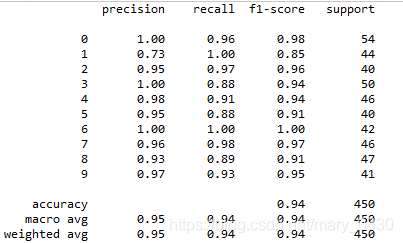
正确率在 94% ,相当不错的。
(五)用神经网络实现手写字符识别
首先,载入需要的库:
# -*- coding: utf-8 -*-
#载入所需要的包
import matplotlib.pyplot as plt
import numpy as np
import scipy.io as scio #读取.mat文件
- 1
- 2
- 3
- 4
- 5
- 6
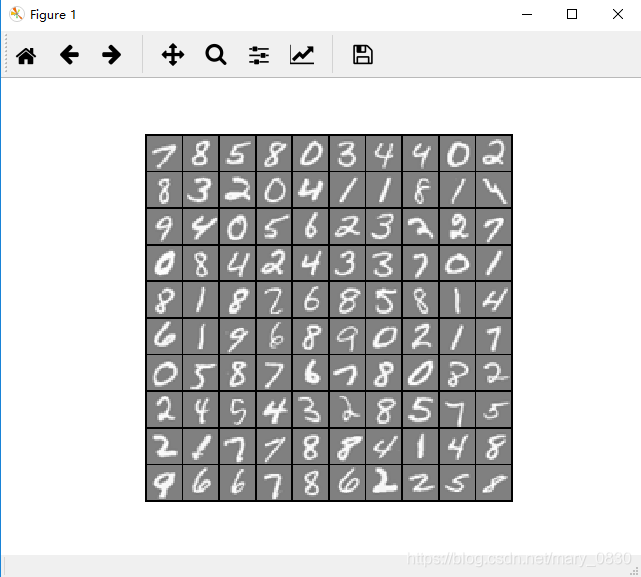
载入数据集,以及可视化随机100个数据:
input_layer_size=400 #输入层的单元数 原始输入特征数 20*20=400
hidden_layer_size=25 #隐藏层 25个神经元
num_labels=10 # 10个标签 数字0对应类别10 数字1-9对应类别1-9
def display_data(x):
(m, n) = x.shape #100*400
example_width = np.round(np.sqrt(n)).astype(int) #每个样本显示宽度 round()四舍五入到个位 并转换为int
example_height = (n / example_width).astype(int) #每个样本显示高度 并转换为int
#设置显示格式 100个样本 分10行 10列显示
display_rows = np.floor(np.sqrt(m)).astype(int)
display_cols = np.ceil(m / display_rows).astype(int)
# 待显示的每张图片之间的间隔
pad = 1
# 显示的布局矩阵 初始化值为-1
display_array = - np.ones((pad + display_rows * (example_height + pad),
pad + display_rows * (example_height + pad)))
# Copy each example into a patch on the display array
curr_ex = 0
for j in range(display_rows):
for i in range(display_cols):
if curr_ex > m:
break
# Copy the patch
# Get the max value of the patch
max_val = np.max(np.abs(x[curr_ex]))
display_array[pad + j * (example_height + pad) + np.arange(example_height),
pad + i * (example_width + pad) + np.arange(example_width)[:, np.newaxis]] = \
x[curr_ex].reshape((example_height, example_width)) / max_val
curr_ex += 1
if curr_ex > m:
break
# 显示图片
plt.figure()
plt.imshow(display_array, cmap='gray', extent=[-1, 1, -1, 1])
plt.axis('off')
print('>>Loading and Visualizing Data ')
data = scio.loadmat('ex3data1.mat') #读取数据
X = data['X'] #获取输入特征矩阵 5000*400
y = data['y'].flatten() #获取5000个样本的标签 用flatten()函数 将5000*1的2维数组 转换成包含5000个元素的一维数组
m = y.size #样本数 5000
# 随机选100个样本 可视化
rand_indices = np.random.permutation(range(m))
selected = X[rand_indices[0:100], :]
display_data(selected)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
结果如下:
加载训练好的神经网络参数:
data=scio.loadmat('ex3weights.mat')#读取参数数据
#本实验神经网络结构只有3层 输入层,隐藏层 输出层
theta1 = data['Theta1'] #输入层和隐藏层之间的参数矩阵
theta2 = data['Theta2'] #隐藏层和输出层之间的参数矩阵
- 1
- 2
- 3
- 4
利用训练好的参数,完成神经网络的前向传播,实现预测过程:
#sigmoid函数
def sigmoid(z):
return 1/(1+np.exp(-z))
def predict(theta1,theta2,x):
#theta1:25*401 输入层多一个偏置项
#theta2:10*26 隐藏层多一个偏置项
m=x.shape[0]#样本数
num_labels=theta2.shape[0]#类别数
x=np.c_[np.ones(m),x] #增加一列1 x:5000*401
p=np.zeros(m)
z1=x.dot(theta1.T)#z1:5000*25
a1=sigmoid(z1) #a1:5000*25
a1=np.c_[np.ones(m),a1]#增加一列1 a1:5000*26
z2=a1.dot(theta2.T)#z2:5000*10
a2=sigmoid(z2)#a2:5000*10
p=np.argmax(a2,axis=1)#输出层的10个单元 第一个对应数字1...第十个对应数字0
p+=1 #最大位置+1 即为预测的标签
return p
pred = predict(theta1, theta2, X)
print('>>Training set accuracy: {}'.format(np.mean(pred == y)*100))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
预测出的准确性的实验结果:

所属网站分类: 技术文章 > 博客
作者:短发越来越短
链接:https://www.pythonheidong.com/blog/article/53057/88a81fa819685f7515cf/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力