

urllib.parse 库里面的3个函数
发布于2019-08-06 10:23 阅读(661) 评论(0) 点赞(2) 收藏(4)
urllib.parse #这个库里面要了解的3个函数
-
quote url编码函数,将中文进行转化为%xxx(见例题1)
-
unquote url解码函数,将%xxx转化为指定字符串(见例题1)
-
urlencode 给一个字典,将字典拼接为query_string,并且实现了编码的功能(见例题2)
例题1
import urllib.parse
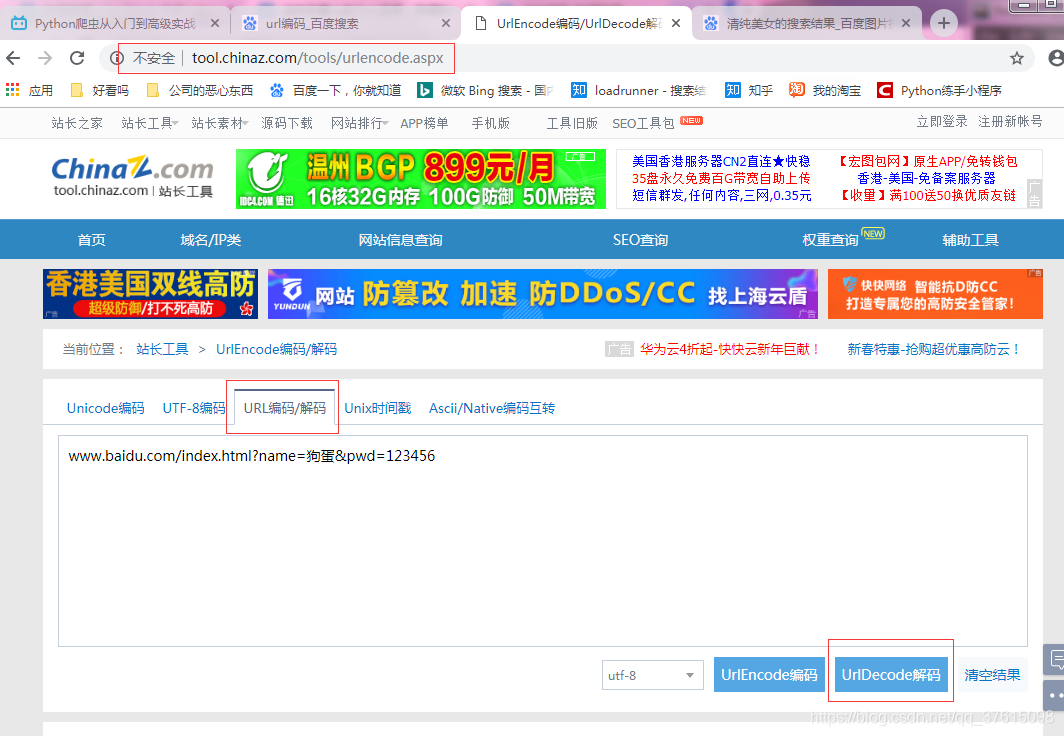
#url只能由特定的字符串组成,字母,数字,下划线。如果出现其他的,比如$ 空格 中文 等,就要对齐进行编码
url = "www.baidu.com/index.html?name=狗蛋&pwd=123456" #非法的url
res = urllib.parse.quote(url)
print(res)
#结果:www.baidu.com/index.html%3Fname%3D%E7%8B%97%E8%9B%8B%26pwd%3D123456
#可以在百度里面收:url编码(第一个)见图1
url = "www.baidu.com/index.html%3Fname%3D%E7%8B%97%E8%9B%8B%26pwd%3D123456"
res = urllib.parse.unquote(url)
print(res)
#结果:www.baidu.com/index.html?name=狗蛋&pwd=123456
例题2
所属网站分类: 技术文章 > 博客
作者:小胖子
链接:https://www.pythonheidong.com/blog/article/7613/955c2b67b937bc52b11c/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力