

python对excel操作获取某一列,某一行的值,对某一列信息筛选
发布于2019-08-06 10:41 阅读(1358) 评论(0) 点赞(0) 收藏(5)
python对excel操作大全详解(获取某一列,某一行的值,对某一列信息筛选)
在此使用的包是pandas,因为其可以同时处理xls和xlsx两种excel文件。
使用pd读取有多个sheet的excel
pandas读取的常用格式pd.read_excel(file, sheet_name),其中sheetname可以使用数字进行替代,从0开始,默认为0
pandas写入的格式为data.to_excel('filename',sheet_name='A')
处理的excel信息如下:
代码如下:
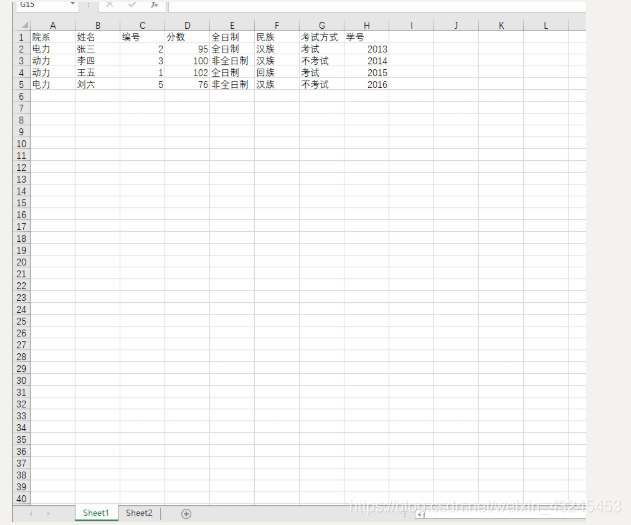
import pandas as pd
path = 'G:\动力系\新建文件夹\什么.xls'
data = pd.read_excel(path,None)#读取数据,设置None可以生成一个字典,字典中的key值即为sheet名字,此时不用使用DataFram,会报错
print(data.keys())#查看sheet的名字
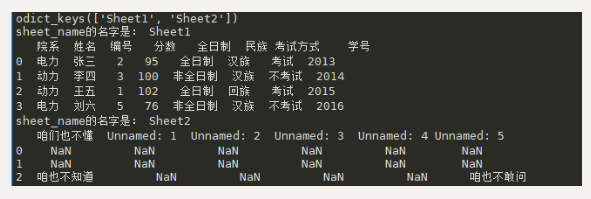
for sh_name in data.keys():
print('sheet_name的名字是:',sh_name)
sh_data = pd.DataFrame(pd.read_excel(path,sh_name))#获得每一个sheet中的内容
print(sh_data)
结果:

获得某一行,某一列的值
pd对excel的相关基本操作看下面的链接
https://blog.csdn.net/weixin_43245453/article/details/90056884
数据使用的是第一个sheet
import pandas as pd
path = 'G:\动力系\新建文件夹\什么.xls'
data = pd.DataFrame(pd.read_excel(path))#读取数据,设置None可以生成一个字典,字典中的key值即为sheet名字,此时不用使用DataFram,会报错
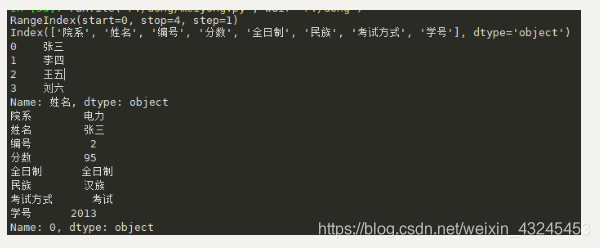
print(data.index)#获取行的索引名称
print(data.columns)#获取列的索引名称
print(data['姓名'])#获取列名为姓名这一列的内容
print(data.loc[0])#获取行名为0这一行的内容
结果:

对某一列的信息进行筛选
筛选使用的是data.loc[列名称 = 提取的信息]
假如我要提取院系下面的动力,代码如下:
import pandas as pd
path = 'G:\动力系\新建文件夹\什么.xls'
data = pd.DataFrame(pd.read_excel(path))#读取数据,设置None可以生成一个字典,字典中的key值即为sheet名字,此时不用使用DataFram,会报错
result = data.loc[data['院系'] == '动力']#获取列明为院系,内容为动力的内容
print(result)
结果如下:


所属网站分类: 技术文章 > 博客
作者:小鬼来了
链接:https://www.pythonheidong.com/blog/article/7821/3519682b94077cbca155/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力