

文本分类综合(rnn,cnn,word2vec,TfidfVectorizer)
发布于2019-08-06 11:19 阅读(1790) 评论(0) 点赞(3) 收藏(2)
中文评论情感分析(keras+rnn)
0.需要的库
# 首先加载必用的库,jieba和gensim专门中文
# %matplotlib inline功能是可以内嵌绘图,并且可以省略掉plt.show()这一步
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import re #正则化用
import jieba # 中文必须用【结巴分词】,因为计算机不会断句
# gensim用来加载预训练word vector
from gensim.models import KeyedVectors
#KeyedVectors实现实体(单词、文档、图片都可以)和向量之间的映射,实体都用string id表示
#有时候运行代码时会有很多warning输出,如提醒新版本之类的,如果不想乱糟糟的输出可以这样
import warnings
warnings.filterwarnings("ignore")
1.预训练词向量
词袋cn_model:北京师范大学中文信息处理研究所与中国人民大学 DBIIR 实验室的研究者开源的"chinese-word-vectors" github链接为:https://github.com/Embedding/Chinese-Word-Vectors 。这里我们使用了"chinese-word-vectors"知乎Word + Ngram的词向量,可以从上面github链接下载,作者本人下载好放入网盘和其他语料需自己建立读取路径,链接:https://pan.baidu.com/s/1RCrNNAagOjLqj0BP8cA9EQ 提取码:fgux
# 使用gensim加载预训练中文分词embedding
cn_model = KeyedVectors.load_word2vec_format('chinese_word_vectors/sgns.zhihu.bigram',
binary=False)
2.词向量模型
在这个词向量模型里,每一个词是一个索引,对应的是一个长度为300的向量,我们今天需要构建的LSTM神经网络模型并不能直接处理汉字文本,需要先进行分次并把词汇转换为词向量,步骤请参考: 1.原始文本:我喜欢文学 2.分词:我,喜欢,文学 3.Tokenize(索引化):[2,345,4564] 4.Embedding(词向量化):用一个300维的词向量,上面的tokens成为一个[3,300]的矩阵 5.RNN:1DCONV,GRU,LSTM等 6.经过激活函数输出分类:如sigmoid输出在0到1间
# 由此可见每一个词都对应一个长度为300的向量
embedding_dim = cn_model['山东大学'].shape[0] #一词山东大学,shape[0]返回行数
print('词向量的长度为{}'.format(embedding_dim))
cn_model['山东大学']
输出如下:
词向量的长度为300
Out[3]:
array([-2.603470e-01, 3.677500e-01, -2.379650e-01, 5.301700e-02,
-3.628220e-01, -3.212010e-01, -1.903330e-01, 1.587220e-01,
.
dtype=float32)
# 计算相似度
cn_model.similarity('橘子', '橙子')
输出
0.66128117
# dot('橘子'/|'橘子'|, '橙子'/|'橙子'| ),余弦相似度
np.dot(cn_model['橘子']/np.linalg.norm(cn_model['橘子']),
cn_model['橙子']/np.linalg.norm(cn_model['橙子']))
输出
0.66128117
# 找出最相近的词,余弦相似度
cn_model.most_similar(positive=['大学'], topn=10)
输出
[(‘高中’, 0.7247823476791382),
(‘本科’, 0.6768535375595093),
(‘研究生’, 0.6244412660598755),
(‘中学’, 0.6088204979896545),
(‘大学本科’, 0.595908522605896),
(‘初中’, 0.5883588790893555),
(‘读研’, 0.5778335332870483),
(‘职高’, 0.5767995119094849),
(‘大学毕业’, 0.5767451524734497),
(‘师范大学’, 0.5708829760551453)]
# 找出不同的词
test_words = '老师 会计师 程序员 律师 医生 老人'
test_words_result = cn_model.doesnt_match(test_words.split())
print('在 '+test_words+' 中:\n不是同一类别的词为: %s' %test_words_result)
输出
在 老师 会计师 程序员 律师 医生 老人 中:
不是同一类别的词为: 老人
cn_model.most_similar(positive=['女人','出轨'], negative=['男人'], topn=1)
输出
[(‘劈腿’, 0.5849199295043945)]
3.训练语料 (数据集)
本教程使用了酒店评论语料,训练样本分别被放置在两个文件夹里: 分别的pos和neg,每个文件夹里有2000个txt文件,每个文件内有一段评语,共有4000个训练样本,这样大小的样本数据在NLP中属于非常迷你的
# 获得样本的索引,样本存放于两个文件夹中,
# 分别为 正面评价'pos'文件夹 和 负面评价'neg'文件夹
# 每个文件夹中有2000个txt文件,每个文件中是一例评价,一个对一个
import os #读入读出通道
pos_txts = os.listdir('pos')
neg_txts = os.listdir('neg')
print( '样本总共: '+ str(len(pos_txts) + len(neg_txts)) )
样本总共: 4000
# 现在我们将所有的评价内容放置到一个list里
train_texts_orig = [] # 存储所有评价,每例评价为一条string,原始评论
# 添加完所有样本之后,train_texts_orig为一个含有4000条文本的list
# 其中前2000条文本为正面评价,后2000条为负面评价
#以下为读入.txt文件过程
for i in range(len(pos_txts)):
with open('pos/'+pos_txts[i], 'r', errors='ignore') as f:
text = f.read().strip()
train_texts_orig.append(text)
f.close()
for i in range(len(neg_txts)):
with open('neg/'+neg_txts[i], 'r', errors='ignore') as f:
text = f.read().strip()
train_texts_orig.append(text)
f.close()
len(train_texts_orig)
4000
# 我们使用tensorflow的keras接口来建模
from keras.models import Sequential
from keras.layers import Dense, GRU, Embedding, LSTM, Bidirectional#Dense全连接
#Bidirectional双向LSTM callbacks用来调参
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.optimizers import RMSprop
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard, ReduceLROnPlateau
4.分词和tokenize
首先我们去掉每个样本的标点符号,然后用jieba分词,jieba分词返回一个生成器,没法直接进行tokenize,所以我们将分词结果转换成一个list,并将它索引化,这样每一例评价的文本变成一段索引数字,对应着预训练词向量模型中的词。
# 进行分词和tokenize
# train_tokens是一个长长的list,其中含有4000个小list,对应每一条评价
train_tokens = []
for text in train_texts_orig:
# 去掉标点
text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "",text)
# 结巴分词
cut = jieba.cut(text)
# 结巴分词的输出结果为一个生成器
# 把生成器转换为list
cut_list = [ i for i in cut ]
for i, word in enumerate(cut_list):
try:
# 将词转换为索引index
cut_list[i] = cn_model.vocab[word].index
except KeyError:
# 如果词不在字典中,则输出0
cut_list[i] = 0
train_tokens.append(cut_list)
5.索引长度标准化
因为每段评语的长度是不一样的,我们如果单纯取最长的一个评语,并把其他评填充成同样的长度,这样十分浪费计算资源,所以我们取一个折衷的长度。
# 获得所有tokens的长度
num_tokens = [ len(tokens) for tokens in train_tokens ]
num_tokens = np.array(num_tokens)
# 平均tokens的长度
np.mean(num_tokens)
71.4495
# 最长的评价tokens的长度
np.max(num_tokens)
1540
plt.hist(np.log(num_tokens), bins = 100)#有大有小取对数
plt.xlim((0,20))
plt.ylabel('number of tokens')
plt.xlabel('length of tokens')
plt.title('Distribution of tokens length')
plt.show()
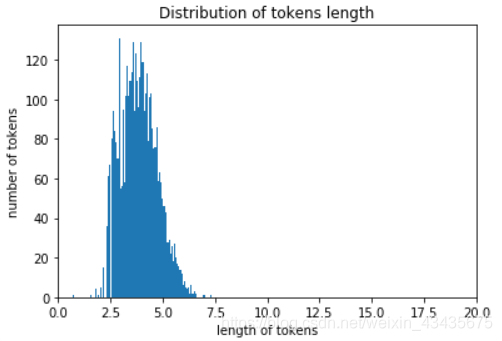
# 取tokens平均值并加上两个tokens的标准差,
# 假设tokens长度的分布为正态分布,则max_tokens这个值可以涵盖95%左右的样本
max_tokens = np.mean(num_tokens) + 2 * np.std(num_tokens)
max_tokens = int(max_tokens)
max_tokens
236
# 取tokens的长度为236时,大约95%的样本被涵盖
# 我们对长度不足的进行padding,超长的进行修剪
np.sum( num_tokens < max_tokens ) / len(num_tokens)
0.9565
6.反向tokenize
为了之后来验证 我们定义一个function,用来把索引转换成可阅读的文本,这对于debug很重要。
# 用来将tokens转换为文本
def reverse_tokens(tokens):
text = ''
for i in tokens:
if i != 0:
text = text + cn_model.index2word[i]
else:
text = text + ' '
return text
reverse = reverse_tokens(train_tokens[0])
# 经过tokenize再恢复成文本
# 可见标点符号都没有了
reverse
‘早餐太差无论去多少人那边也不加食品的酒店应该重视一下这个问题了房间本身很好’
# 原始文本
train_texts_orig[0]
‘早餐太差,无论去多少人,那边也不加食品的。酒店应该重视一下这个问题了。\n\n房间本身很好。’
7.构建embedding matrix
现在我们来为模型准备embedding matrix(词向量矩阵),根据keras的要求,我们需要准备一个维度为(numwords, embeddingdim)的矩阵【num words代表我们使用的词汇的数量,emdedding dimension在我们现在使用的预训练词向量模型中是300,每一个词汇都用一个长度为300的向量表示】注意我们只选择使用前50k个使用频率最高的词,在这个预训练词向量模型中,一共有260万词汇量,如果全部使用在分类问题上会很浪费计算资源,因为我们的训练样本很小,一共只有4k,如果我们有100k,200k甚至更多的训练样本时,在分类问题上可以考虑减少使用的词汇量。
embedding_dim
300
# 只使用大库前50000个词
num_words = 50000
# 初始化embedding_matrix,之后在keras上进行应用
embedding_matrix = np.zeros((num_words, embedding_dim))
# embedding_matrix为一个 [num_words,embedding_dim] 的矩阵
# 维度为 50000 * 300
for i in range(num_words):
embedding_matrix[i,:] = cn_model[cn_model.index2word[i]]
embedding_matrix = embedding_matrix.astype('float32')
# 检查index是否对应,
# 输出300意义为长度为300的embedding向量一一对应
np.sum( cn_model[cn_model.index2word[333]] == embedding_matrix[333] )
300
# embedding_matrix的维度,
# 这个维度为keras的要求,后续会在模型中用到
embedding_matrix.shape
(50000, 300)
8.padding(填充)和truncating(修剪)
我们把文本转换为tokens(索引)之后,每一串索引的长度并不相等,所以为了方便模型的训练我们需要把索引的长度标准化,上面我们选择了236这个可以涵盖95%训练样本的长度,接下来我们进行padding和truncating,我们一般采用’pre’的方法,这会在文本索引的前面填充0,因为根据一些研究资料中的实践,如果在文本索引后面填充0的话,会对模型造成一些不良影响。
# 进行padding和truncating, 输入的train_tokens是一个list
# 返回的train_pad是一个numpy array
train_pad = pad_sequences(train_tokens, maxlen=max_tokens,
padding='pre', truncating='pre')
# 超出五万个词向量的词用0代替
train_pad[ train_pad>=num_words ] = 0
# 可见padding之后前面的tokens全变成0,文本在最后面
train_pad[33]
array([ 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
290, 3053, 57, 169, 73, 1, 25, 11216, 49,
163, 15985, 0, 0, 30, 8, 0, 1, 228,
223, 40, 35, 653, 0, 5, 1642, 29, 11216,
2751, 500, 98, 30, 3159, 2225, 2146, 371, 6285,
169, 27396, 1, 1191, 5432, 1080, 20055, 57, 562,
1, 22671, 40, 35, 169, 2567, 0, 42665, 7761,
110, 0, 0, 41281, 0, 110, 0, 35891, 110,
0, 28781, 57, 169, 1419, 1, 11670, 0, 19470,
1, 0, 0, 169, 35071, 40, 562, 35, 12398,
657, 4857])
# 准备target向量,前2000样本为1,后2000为0
train_target = np.concatenate( (np.ones(2000),np.zeros(2000)) )
# 进行训练和测试样本的分割
from sklearn.model_selection import train_test_split
train_target.shape
train_pad.shape
(4000, 236)
# 90%的样本用来训练,剩余10%用来测试
#因为前2000个文件夹都是neg一类,所以打乱顺序来训练 random_state
X_train, X_test, y_train, y_test = train_test_split(train_pad,
train_target,
test_size=0.1,
random_state=12
)
# 查看训练样本,确认无误
print(reverse_tokens(X_train[35]))
print('class: ',y_train[35])
房间很大还有海景阳台走出酒店就是沙滩非常不错唯一遗憾的就是不能刷 不方便
class: 1.0
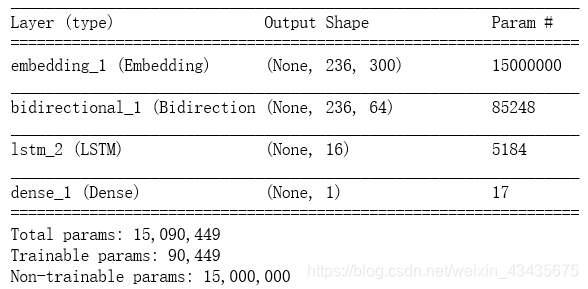
9.用keras搭建LSTM模型
模型的第一层是Embedding层,只有当我们把tokens索引转换为词向量矩阵之后,才可以用神经网络对文本进行处理。keras提供了Embedding接口,避免了繁琐的稀疏矩阵操作。在Embedding层我们输入的矩阵为:(batchsize, maxtokens),输出矩阵为:(batchsize, maxtokens, embeddingdim)
# 用LSTM对样本进行分类
model = Sequential()
# 模型第一层为embedding,trainable=False因为embedding_matrix下载后已经训练好了
model.add(Embedding(num_words,
embedding_dim,
weights=[embedding_matrix],
input_length=max_tokens,
trainable=False))
model.add(Bidirectional(LSTM(units=32, return_sequences=True)))#双向LSTM考虑前后词
model.add(LSTM(units=16, return_sequences=False))#units=16神经元个数
GRU:如果使用GRU,测试样本可以达到87%的准确率,但我测试自己的文本内容时发现,GRU最后一层激活函数的输出都在0.5左右,说明模型的判断不是很明确,信心比较低,而且经过测试发现模型对于否定句的判断有时会失误,我们期望对于负面样本输出接近0,正面样本接近1而不是都徘徊于0.5之间。
BILSTM:测试了LSTM和BiLSTM,发现BiLSTM的表现最好,LSTM的表现略好于GRU,因为BiLSTM对于比较长的句子结构有更好的记忆。Embedding之后第,一层我们用BiLSTM返回sequences,然后第二层16个单元的LSTM不返回sequences,只返回最终结果,最后是一个全链接层,用sigmoid激活函数输出结果
# GRU的代码
# model.add(GRU(units=32, return_sequences=True))
# model.add(GRU(units=16, return_sequences=True))
# model.add(GRU(units=4, return_sequences=False))
#加入全连接层
model.add(Dense(1, activation='sigmoid'))
# 我们使用adam以0.001的learning rate进行优化
optimizer = Adam(lr=1e-3)
model.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# 我们来看一下模型的结构,一共90k左右可训练的变量,None表示batchsize,一个batch有236词输入
#15000000为50000*300,因为train=false,所以不训练这些参数
#17=16*1+1(bias为一参数)
model.summary()
# 建立一个权重的存储点,verbose=1可以是打印信息更加详细,方面查找问题
path_checkpoint = 'sentiment_checkpoint.keras'
checkpoint = ModelCheckpoint(filepath=path_checkpoint, monitor='val_loss',
verbose=1, save_weights_only=True,
save_best_only=True)
# 尝试加载已训练模型
try:
model.load_weights(path_checkpoint)
except Exception as e:
print(e)
# 定义early stoping如果3个epoch内validation loss没有改善则停止训练
earlystopping = EarlyStopping(monitor='val_loss', patience=3, verbose=1)
# 自动降低learning rate
lr_reduction = ReduceLROnPlateau(monitor='val_loss',
factor=0.1, min_lr=1e-5, patience=0,
verbose=1)
# 定义callback函数
callbacks = [
earlystopping,
checkpoint,
lr_reduction
]
# 开始训练,4000*0.1=400为test,validation_split=0.1为3600*0.1
model.fit(X_train, y_train,
validation_split=0.1,
epochs=4,
batch_size=128,
callbacks=callbacks)
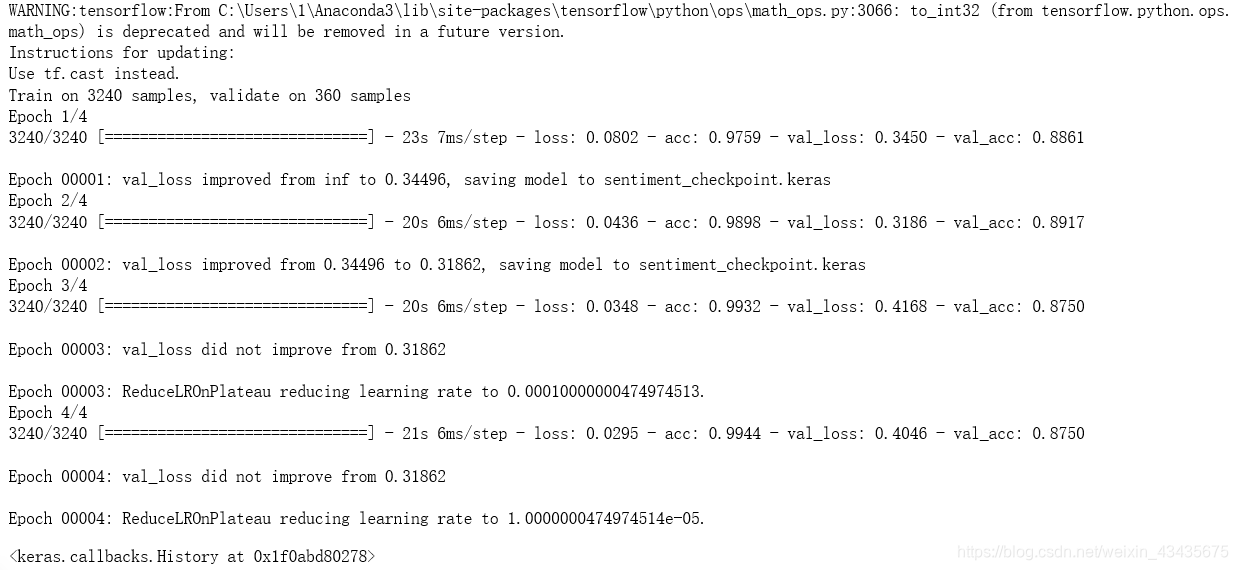
10.结论
我们定义一个预测函数(将输入文本按模型要求处理再输入),来预测输入的文本的极性,可见模型对于否定句和一些简单的逻辑结构都可以进行准确的判断。
result = model.evaluate(X_test, y_test)
print('Accuracy:{0:.2%}'.format(result[1]))
def predict_sentiment(text):
print(text)
# 去标点
text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "",text)
# 分词
cut = jieba.cut(text)
cut_list = [ i for i in cut ]
# tokenize
for i, word in enumerate(cut_list):
try:
cut_list[i] = cn_model.vocab[word].index
except KeyError:
cut_list[i] = 0
# padding
tokens_pad = pad_sequences([cut_list], maxlen=max_tokens,
padding='pre', truncating='pre')
# 预测
result = model.predict(x=tokens_pad)
coef = result[0][0]
if coef >= 0.5:
print('是一例正面评价','output=%.2f'%coef)
else:
print('是一例负面评价','output=%.2f'%coef)
test_list = [
'酒店设施不是新的,服务态度不好',
'房间很凉爽,空调冷气很足',
'酒店环境不好,住宿体验很不好',
'房间隔音不到位' ,
'晚上回来发现没有打扫卫生'
]
for text in test_list:
predict_sentiment(text)
酒店设施不是新的,服务态度不好
是一例负面评价 output=0.01
房间很凉爽,空调冷气很足
是一例正面评价 output=0.94
酒店环境不好,住宿体验很不好
是一例负面评价 output=0.01
房间隔音不到位
是一例负面评价 output=0.02
晚上回来发现没有打扫卫生
是一例负面评价 output=0.40
11.错误分类
y_pred = model.predict(X_test)
y_pred = y_pred.T[0]
y_pred = [1 if p>= 0.5 else 0 for p in y_pred]
y_pred = np.array(y_pred)
y_actual = np.array(y_test)
# 找出错误分类的索引
misclassified = np.where( y_pred != y_actual )[0]
# 输出所有错误分类的索引,在test400条中有48条分错
len(misclassified)
print(len(misclassified))
55
# 我们来找出错误分类的样本看看,misclassified[1]打出第二条分错的
idx=misclassified[1]
print(reverse_tokens(X_test[idx]))
print('预测的分类', y_pred[idx])
print('实际的分类', y_actual[idx])
地理位置还不错到哪里都比较方便但是服务不象是 集团管理的比较差下午睡了 并洗了一个澡本来想让酒店再来打扫一下所以打开了请打扫的服务灯可是到晚上回酒店发现打扫得服务灯被关掉了而房间还是没有打扫过
预测的分类 1
实际的分类 0.0
新浪新闻分类(tensorflow+cnn)
数据集采用清华数据集作者本人截取了一部分,数据集百度云下载链接:
链接:https://pan.baidu.com/s/1-Rm9PU7ekU3zx_7gTB9ibw 提取码:3d3o
#以下为获取文件
import os
def getFilePathList(rootDir):
filePath_list = []
for walk in os.walk(rootDir):
part_filePath_list = [os.path.join(walk[0], file) for file in walk[2]]
filePath_list.extend(part_filePath_list)
return filePath_list
filePath_list = getFilePathList('part_cnews')
len(filePath_list)#一共有1400个.txt文件组成一个list
运行结果:
filePath_list[5]
运行结果:

#所有样本标签的值汇总成一个列表,赋给标签列表label_list
#windows和Linux系统路径字符串的间隔符有区别
label_list = []
for filePath in filePath_list:
label = filePath.split('\\')[1]
label_list.append(label)
len(label_list)
运行结果:

#标签统计计数
import pandas as pd
pd.value_counts(label_list)
运行结果:

#用pickle库保存label_list
import pickle
with open('label_list.pickle','wb') as file:
pickle.dump(label_list,file)
#获取所有样本内容,保存content_list
#pickle.dump可以将python中对象持久化为二进制文件,二进制文件的加载速度非常快。避免内存溢出,每读取一定数量的文件就利用pickle库的dump方法保存
import time
import pickle
import re
def getFile(filePath):
with open(filePath, encoding='utf8') as file:
fileStr = ''.join(file.readlines(1000))
return fileStr
interval = 100
n_samples = len(label_list)
startTime = time.time()
directory_name = 'content_list'
if not os.path.isdir(directory_name):
os.mkdir(directory_name)
for i in range(0, n_samples, interval):
startIndex = i
endIndex = i + interval
content_list = []
print('%06d-%06d start' %(startIndex, endIndex))
for filePath in filePath_list[startIndex:endIndex]:
fileStr = getFile(filePath)
content = re.sub('\s+', ' ', fileStr)
content_list.append(content)
save_fileName = directory_name + '/%06d-%06d.pickle' %(startIndex, endIndex)
with open(save_fileName, 'wb') as file:
pickle.dump(content_list, file)
used_time = time.time() - startTime
print('%06d-%06d used time: %.2f seconds' %(startIndex, endIndex, used_time))
运行结果:
#前面为获取数据,拿到原始数据进行处理过程,【content_list文件夹、label_list文件、代码文件】这三者处于相同路径
#加载数据
import time
import pickle
import os
def getFilePathList(rootDir):
filePath_list = []
for walk in os.walk(rootDir):
part_filePath_list = [os.path.join(walk[0], file) for file in walk[2]]
filePath_list.extend(part_filePath_list)
return filePath_list
startTime = time.time()
contentListPath_list = getFilePathList('content_list')
content_list = []
for filePath in contentListPath_list:
with open(filePath, 'rb') as file:
part_content_list = pickle.load(file)
content_list.extend(part_content_list)
with open('label_list.pickle', 'rb') as file:
label_list = pickle.load(file)
used_time = time.time() - startTime
print('used time: %.2f seconds' %used_time)
sample_size = len(content_list)
print('length of content_list,mean sample size: %d' %sample_size)
运行结果:
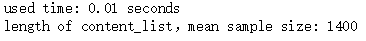
len(content_list)
运行结果:
#制作词汇表:内容列表content_list中的元素是每篇文章内容,数据类型为字符串。
#对所有文章内容中的字做统计计数,出现次数排名前5000的字赋值给变量vocabulary_list。
from collections import Counter
def getVocabularyList(content_list, vocabulary_size):
allContent_str = ''.join(content_list)
counter = Counter(allContent_str)
vocabulary_list = [k[0] for k in counter.most_common(vocabulary_size)]
return ['PAD'] + vocabulary_list
startTime = time.time()
vocabulary_list = getVocabularyList(content_list, 5000)
used_time = time.time() - startTime
print('used time: %.2f seconds' %used_time)
运行结果:
#保存词汇表
import pickle
with open('vocabulary_list.pickle', 'wb') as file:
pickle.dump(vocabulary_list, file)
#加载词汇表:完成制作词汇表后,将其保存。之后再运行代码则直接加载保存的词汇表,节省了复制作词汇表花费的时间。
import pickle
with open('vocabulary_list.pickle', 'rb') as file:
vocabulary_list = pickle.load(file)
#数据准备
#在代码块中按Esc键,进入命令模式,代码块左边的竖线会显示蓝色。在命令模式下,点击L键,会显示代码行数
import time
startTime = time.time()#记录本段代码运行开始时间,赋值给变量startTime
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(content_list, label_list)
train_content_list = train_X
train_label_list = train_y
test_content_list = test_X
test_label_list = test_y
used_time = time.time() - startTime #打印提示信息,表示程序运行至此步花费时间
print('train_test_split used time : %.2f seconds' %used_time)
vocabulary_size = 10000 # 词汇表达小
sequence_length = 600 # 序列长度
embedding_size = 64 # 词向量维度
num_filters = 256 # 卷积核数目
filter_size = 5 # 卷积核尺寸
num_fc_units = 128 # 全连接层神经元
dropout_keep_probability = 0.5 # dropout保留比例
learning_rate = 1e-3 # 学习率
batch_size = 64 # 每批训练大小
word2id_dict = dict([(b, a) for a, b in enumerate(vocabulary_list)])#使用列表推导式得到词汇及其id对应的列表,并调用dict方法将列表强制转换为字典
content2idList = lambda content : [word2id_dict[word] for word in content if word in word2id_dict]#使用列表推导式和匿名函数定义函数content2idlist,函数作用是将文章中的每个字转换为id
train_idlist_list = [content2idList(content) for content in train_content_list]#使用列表推导式得到的结果是列表的列表,总列表train_idlist_list中的元素是每篇文章中的字对应的id列表
used_time = time.time() - startTime#代码打印提示信息,表示程序运行至此步花费时间
print('content2idList used time : %.2f seconds' %used_time)
import numpy as np
num_classes = np.unique(label_list).shape[0]#获取标签的类别数量,例如本文类别数量为14,即变量num_classes的值为14
#以下6行为获得能够用于模型训练的特征矩阵和预测目标值
import tensorflow.contrib.keras as kr
train_X = kr.preprocessing.sequence.pad_sequences(train_idlist_list, sequence_length)#将每个样本统一长度为seq_length,即600上面超参数已设定600
from sklearn.preprocessing import LabelEncoder#导入sklearn.preprocessing库的labelEncoder方法
labelEncoder = LabelEncoder()#实例化LabelEncoder对象
train_y = labelEncoder.fit_transform(train_label_list)#调用LabelEncoder对象的fit_transform方法做标签编码
train_Y = kr.utils.to_categorical(train_y, num_classes)#调用keras.untils库的to_categorical方法将标签编码的结果再做Ont-Hot编码
import tensorflow as tf
tf.reset_default_graph()#重置tensorflow图,加强代码的健壮性
X_holder = tf.placeholder(tf.int32, [None, sequence_length])
Y_holder = tf.placeholder(tf.float32, [None, num_classes])
used_time = time.time() - startTime
print('data preparation used time : %.2f seconds' %used_time)
运行结果:

list(word2id_dict.items())[:20]
运行结果:

#搭建神经网络
embedding = tf.get_variable('embedding',
[vocabulary_size, embedding_size])#调用tf库的get_variable方法实例化可以更新的模型参数embedding,矩阵形状为vocabulary_size*embedding_size,即10000*64
embedding_inputs = tf.nn.embedding_lookup(embedding,#将输入数据做词嵌入,得到新变量embedding_inputs的形状为batch_size*sequence_length*embedding_size,即64*600*64
X_holder)
conv = tf.layers.conv1d(embedding_inputs, #调用tf.layers.conv1d方法,方法需要3个参数,第1个参数是输入数据,第2个参数是卷积核数量num_filters,第3个参数是卷积核大小filter_size
num_filters, #方法结果赋值给变量conv,形状为batch_size*596*num_filters,596是600-5+1的结果
filter_size)
max_pooling = tf.reduce_max(conv, #对变量conv的第1个维度做求最大值操作。方法结果赋值给变量max_pooling,形状为batch_size*num_filters,即64*256
[1])
full_connect = tf.layers.dense(max_pooling, #添加全连接层,tf.layers.dense方法结果赋值给变量full_connect,形状为batch_size*num_fc_units,即64*128
num_fc_units)
full_connect_dropout = tf.contrib.layers.dropout(full_connect, #代码调用tf.contrib.layers.dropout方法,方法需要2个参数,第1个参数是输入数据,第2个参数是保留比例
keep_prob=dropout_keep_probability)
full_connect_activate = tf.nn.relu(full_connect_dropout) #激活函数
softmax_before = tf.layers.dense(full_connect_activate, #添加全连接层,tf.layers.dense方法结果赋值给变量softmax_before,形状为batch_size*num_classes,即64*14
num_classes)
predict_Y = tf.nn.softmax(softmax_before) #tf.nn.softmax方法,方法结果是预测概率值
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(labels=Y_holder,
logits=softmax_before)
loss = tf.reduce_mean(cross_entropy)
optimizer = tf.train.AdamOptimizer(learning_rate)
train = optimizer.minimize(loss)
isCorrect = tf.equal(tf.argmax(Y_holder, 1), tf.argmax(predict_Y, 1))
accuracy = tf.reduce_mean(tf.cast(isCorrect, tf.float32))
#参数初始化,对于神经网络模型,重要是其中的参数。开始神经网络模型训练之前,需要做参数初始化
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
#模型训练
test_idlist_list = [content2idList(content) for content in test_content_list] #获取测试集中的数据
test_X = kr.preprocessing.sequence.pad_sequences(test_idlist_list, sequence_length)
test_y = labelEncoder.transform(test_label_list)
test_Y = kr.utils.to_categorical(test_y, num_classes)
import random
for i in range(100): #模型迭代训练100次
selected_index = random.sample(list(range(len(train_y))), k=batch_size)#从训练集中选取batch_size大小,即64个样本做批量梯度下降
batch_X = train_X[selected_index]
batch_Y = train_Y[selected_index]
session.run(train, {X_holder:batch_X, Y_holder:batch_Y}) #每运行1次,表示模型训练1次
step = i + 1
if step % 10 == 0:#每间隔10步打印
selected_index = random.sample(list(range(len(test_y))), k=100)#从测试集中随机选取100个样本
batch_X = test_X[selected_index]
batch_Y = test_Y[selected_index]
loss_value, accuracy_value = session.run([loss, accuracy], {X_holder:batch_X, Y_holder:batch_Y})
print('step:%d loss:%.4f accuracy:%.4f' %(step, loss_value, accuracy_value))
运行结果:

import warnings
warnings.filterwarnings("ignore")
def predict(input_content):
#idList的数据类型必须是列表list,
#否则调用kr.preprocessing.sequence.pad_sequences方法会报错
idList = [content2idList(input_content)]
X = kr.preprocessing.sequence.pad_sequences(idList, sequence_length)
Y = session.run(predict_Y, {X_holder:X})
y = np.argmax(Y, axis=1)
label = labelEncoder.inverse_transform(y)[0]
return label
selected_index = random.sample(range(len(test_content_list)), k=1)[0]
selected_sample = test_content_list[selected_index]
true_label = test_label_list[selected_index]
predict_label = predict(selected_sample)
print('selected_sample :', selected_sample)
print('true_label :', true_label)
print('predict_label :', predict_label, '\n')
print('predict whatever you want, for example:')
input_content = "足球裁判打人"
print('predict("%s") :' %input_content, predict(input_content))
运行结果:

#混淆矩阵
import numpy as np
import pandas as pd
from sklearn.metrics import confusion_matrix
def predictAll(test_X, batch_size=100):
predict_value_list = []
for i in range(0, len(test_X), batch_size):
selected_X = test_X[i: i + batch_size]
predict_value = session.run(predict_Y, {X_holder:selected_X})
predict_value_list.extend(predict_value)
return np.array(predict_value_list)
Y = predictAll(test_X)
y = np.argmax(Y, axis=1)
predict_label_list = labelEncoder.inverse_transform(y)
pd.DataFrame(confusion_matrix(test_label_list, predict_label_list),
columns=labelEncoder.classes_,
index=labelEncoder.classes_ )
运行结果:
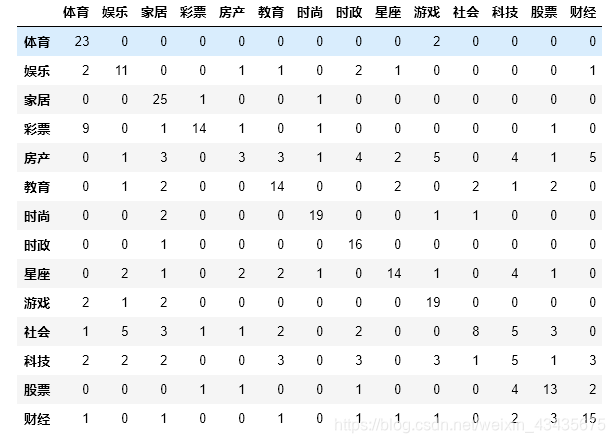
#报告表
import numpy as np
from sklearn.metrics import precision_recall_fscore_support
def eval_model(y_true, y_pred, labels):
# 计算每个分类的Precision, Recall, f1, support
p, r, f1, s = precision_recall_fscore_support(y_true, y_pred)
# 计算总体的平均Precision, Recall, f1, support
tot_p = np.average(p, weights=s)
tot_r = np.average(r, weights=s)
tot_f1 = np.average(f1, weights=s)
tot_s = np.sum(s)
res1 = pd.DataFrame({
u'Label': labels,
u'Precision': p,
u'Recall': r,
u'F1': f1,
u'Support': s
})
res2 = pd.DataFrame({
u'Label': ['总体'],
u'Precision': [tot_p],
u'Recall': [tot_r],
u'F1': [tot_f1],
u'Support': [tot_s]
})
res2.index = [999]
res = pd.concat([res1, res2])
return res[['Label', 'Precision', 'Recall', 'F1', 'Support']]
eval_model(test_label_list, predict_label_list, labelEncoder.classes_)
运行结果:
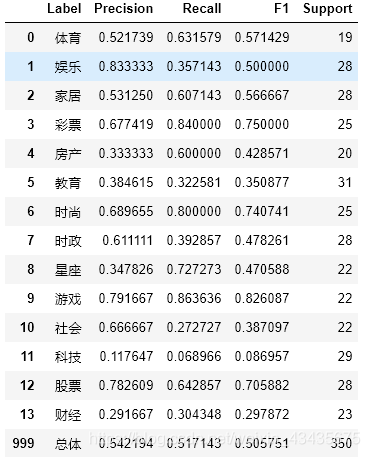
搜狐新闻文本分类(word2vec)
在桌面新建基于word2vec文本分类文件夹,文件夹中输入cmd:

新建一个word2vec_test.ipynb:
rename为:word2vec_test
此时文件夹多了以下两个文件:
0.数据的准备
训练集共有24000条样本,12个分类,每个分类2000条样本。
测试集共有12000条样本,12个分类,每个分类1000条样本。
链接:https://pan.baidu.com/s/1UbPjMpcp3kqvdd0HMAgMfQ 提取码:b53e
下图红色框里为压缩包解压的文件:
加载训练集到变量train_df中,并打印训练集前5行,代码如下:
#训练集数据共有24000条,测试集数据共有12000条
import pandas as pd
#加载训练集到变量train_df中,并打印训练集前5行,代码如下。
#read_csv方法中有3个参数,第1个参数是加载文本文件的路径,第2个关键字参数sep是分隔符,第3个关键字参数header是文本文件的第1行是否为字段名。
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
train_df.head()

#查看训练集每个分类的名字以及样本数量
for name, group in train_df.groupby(0):
print(name,len(group))

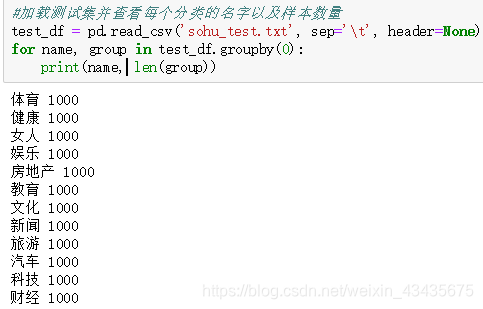
#加载测试集并查看每个分类的名字以及样本数量
test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
for name, group in test_df.groupby(0):
print(name, len(group))
#对训练集的24000条样本循环遍历,使用jieba库的cut方法获得分词列表赋值给变量cutWords
#判断分词是否为停顿词,如果不为停顿词,则添加进变量cutWords中
import jieba
import time
train_df.columns = ['分类', '文章']
stopword_list = [k.strip() for k in open('stopwords.txt', encoding='utf8').readlines() if k.strip() != '']
cutWords_list = []
i = 0
startTime = time.time()
for article in train_df['文章']:
cutWords = [k for k in jieba.cut(article) if k not in stopword_list]
i += 1
if i % 1000 == 0:
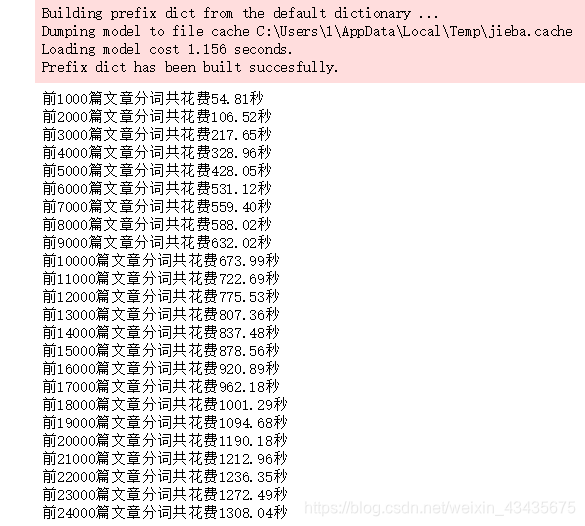
print('前%d篇文章分词共花费%.2f秒' %(i, time.time()-startTime))
cutWords_list.append(cutWords)
运行结果:
#将分词结果保存为本地文件cutWords_list.txt
with open('cutWords_list.txt', 'w') as file:
for cutWords in cutWords_list:
file.write(' '.join(cutWords) + '\n')
作者提供已经分词完成的文本文件链接:https://pan.baidu.com/s/1oKjLZjSkqE0LfLEvLxkBNw 提取码:oh3u
#载入分词文件
with open('cutWords_list.txt') as file:
cutWords_list = [k.split() for k in file.readlines()]
1.word2vec模型
完成此步骤需要先安装gensim库,安装命令:pip install gensim
#调用gensim.models.word2vec库中的LineSentence方法实例化模型对象
from gensim.models import Word2Vec
word2vec_model = Word2Vec(cutWords_list, size=100, iter=10, min_count=20)
#调用模型对象的方法时,一直提示警告信息,避免出现警告信息
import warnings
warnings.filterwarnings('ignore')
#调用Word2Vec模型对象的wv.most_similar方法查看与摄影含义最相近的词。
#wv.most_similar方法有2个参数,第1个参数是要搜索的词,第2个关键字参数topn数据类型为正整数,是指需要列出多少个最相关的词汇,默认为10,即列出10个最相关的词汇。
#wv.most_similar方法返回值的数据类型为列表,列表中的每个元素的数据类型为元组,元组有2个元素,第1个元素为相关词汇,第2个元素为相关程度,数据类型为浮点型。
word2vec_model.wv.most_similar('摄影')
运行结果:

wv.most_similar方法使用positive和negative这2个关键字参数的简单示例:查看女人+先生-男人的结果:
word2vec_model.most_similar(positive=['女人', '先生'], negative=['男人'], topn=1)
运行结果:
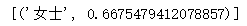
查看两个词的相关性,如下图所示:

保存Word2Vec模型为word2vec_model.w2v文件,代码如下:
word2vec_model.save('word2vec_model.w2v')
2.特征工程:
#对于每一篇文章,获取文章的每一个分词在word2vec模型的相关性向量
#然后把一篇文章的所有分词在word2vec模型中的相关性向量求和取平均数,即此篇文章在word2vec模型中的相关性向量
#实例化Word2Vec对象时,关键字参数size定义为100,则相关性矩阵都为100维
#定义getVector函数获取每个文章的词向量,传入2个参数,第1个参数是文章分词的结果,第2个参数是word2vec模型对象
#变量vector_list是通过列表推导式得出单篇文章所有分词的词向量,通过np.array方法转成ndarray对象再对每一列求平均值
#第1种方法,用for循环常规计算
''''import numpy as np
import time
def getVector_v1(cutWords, word2vec_model):
count = 0
article_vector = np.zeros(word2vec_model.layer1_size)
for cutWord in cutWords:
if cutWord in word2vec_model:
article_vector += word2vec_model[cutWord]
count += 1
return article_vector / count
startTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list[:5000]:
i += 1
if i % 1000 ==0:
print('前%d篇文章形成词向量花费%.2f秒' %(i, time.time()-startTime))
vector_list.append(getVector_v1(cutWords, word2vec_model))
X = np.array(vector_list)
#第2种方法,用pandas的mean方法计算
''''import time
import pandas as pd
def getVector_v2(cutWords, word2vec_model):
vector_list = [word2vec_model[k] for k in cutWords if k in word2vec_model]
vector_df = pd.DataFrame(vector_list)
cutWord_vector = vector_df.mean(axis=0).values
return cutWord_vector
startTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list[:5000]:
i += 1
if i % 1000 ==0:
print('前%d篇文章形成词向量花费%.2f秒' %(i, time.time()-startTime))
vector_list.append(getVector_v2(cutWords, word2vec_model))
X = np.array(vector_list)
#第3种方法,用numpy的mean方法计算
import time
import numpy as np
def getVector_v3(cutWords, word2vec_model):
vector_list = [word2vec_model[k] for k in cutWords if k in word2vec_model]
cutWord_vector = np.array(vector_list).mean(axis=0)
return cutWord_vector
startTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list:
i += 1
if i % 1000 ==0:
print('前%d篇文章形成词向量花费%.2f秒' %(i, time.time()-startTime))
vector_list.append(getVector_v3(cutWords, word2vec_model))
X = np.array(vector_list)
运行结果:

#第4种方法,用numpy的add、divide方法计算
''''import time
import numpy as np
def getVector_v4(cutWords, word2vec_model):
i = 0
index2word_set = set(word2vec_model.wv.index2word)
article_vector = np.zeros((word2vec_model.layer1_size))
for cutWord in cutWords:
if cutWord in index2word_set:
article_vector = np.add(article_vector, word2vec_model.wv[cutWord])
i += 1
cutWord_vector = np.divide(article_vector, i)
return cutWord_vector
startTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list[:5000]:
i += 1
if i % 1000 ==0:
print('前%d篇文章形成词向量花费%.2f秒' %(i, time.time()-startTime))
vector_list.append(getVector_v4(cutWords, word2vec_model))
X = np.array(vector_list)
#因为形成特征矩阵的花费时间较长,为了避免以后重复花费时间,把特征矩阵保存为文件。
#使用ndarray对象的dump方法,需要1个参数,数据类型为字符串,为保存文件的文件名
X.dump('articles_vector.txt')
#加载此文件中的内容赋值给变量X
X = np.load('articles_vector.txt')
3.模型训练,模型评估
3.1 标签编码:
#标签编码
#调用sklearn.preprocessing库的LabelEncoder方法对文章分类做标签编码
from sklearn.preprocessing import LabelEncoder
import pandas as pd
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
train_df.columns = ['分类', '文章']
labelEncoder = LabelEncoder()
y = labelEncoder.fit_transform(train_df['分类'])
3.2 逻辑回归模型
#调用sklearn.linear_model库的LogisticRegression方法实例化模型对象。
#调用sklearn.model_selection库的train_test_split方法划分训练集和测试集
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2)
logistic_model = LogisticRegression()
logistic_model.fit(train_X, train_y)
logistic_model.score(test_X, test_y)
运行结果:
0.789375
3.3 保存模型
#调用sklearn.externals库中的joblib方法保存模型为logistic.model文件
from sklearn.externals import joblib
joblib.dump(logistic_model, 'logistic.model')
#加载模型
from sklearn.externals import joblib
logistic_model = joblib.load('logistic.model')
3.4 交叉验证
#交叉验证的结果更具有说服力。
#调用sklearn.model_selection库的ShuffleSplit方法实例化交叉验证对象。
#调用sklearn.model_selection库的cross_val_score方法获得交叉验证每一次的得分
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import cross_val_score
cv_split = ShuffleSplit(n_splits=5, train_size=0.7, test_size=0.2)
logistic_model = LogisticRegression()
score_ndarray = cross_val_score(logistic_model, X, y, cv=cv_split)
print(score_ndarray)
print(score_ndarray.mean())
运行结果:
[0.79104167 0.77375 0.78875 0.77979167 0.78958333]
0.7845833333333333
3.5 模型测试
#模型测试
#调用sklearn.externals库的joblib对象的load方法加载模型赋值给变量logistic_model。
#调用pandas库read_csv方法读取测试集数据。
#调用DataFrame对象的groupby方法对每个分类分组,从而每种文章类别的分类准确性。
#调用自定义的getVector方法将文章转换为相关性向量。
#自定义getVectorMatrix方法获得测试集的特征矩阵。
#调用labelEncoder对象的transform方法将预测标签做标签编码,从而获得预测目标值
import pandas as pd
import numpy as np
from sklearn.externals import joblib
import jieba
def getVectorMatrix(article_series):
return np.array([getVector_v3(jieba.cut(k), word2vec_model) for k in article_series])
logistic_model = joblib.load('logistic.model')
test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
test_df.columns = ['分类', '文章']
for name, group in test_df.groupby('分类'):
featureMatrix = getVectorMatrix(group['文章'])
target = labelEncoder.transform(group['分类'])
print(name, logistic_model.score(featureMatrix, target))
上段代码运行结果:
体育 0.968
健康 0.814
女人 0.772
娱乐 0.765
房地产 0.879
教育 0.886
文化 0.563
新闻 0.575
旅游 0.82
汽车 0.934
科技 0.817
财经 0.7
4.总结
word2vec模型应用,训练集数据共有24000条,测试集数据共有12000条。经过交叉验证,模型平均得分为0.78左右。(测试集的验证效果中,体育、教育、健康、文化、旅游、汽车、娱乐这7个分类得分较高,即容易被正确分类。女人、娱乐、新闻、科技、财经这5个分类得分较低,即难以被正确分类。)
搜狐新闻文本分类(TfidfVectorizer)
import pandas as pd
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
train_df.head()

for name, group in train_df.groupby(0):
print(name,len(group))
运行结果:

test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
for name, group in test_df.groupby(0):
print(name, len(group))
运行结果:

with open('stopwords.txt', encoding='utf8') as file:
stopWord_list = [k.strip() for k in file.readlines()]
运行结果:

with open('stopwords.txt', encoding='utf8') as file:
stopWord_list = [k.strip() for k in file.readlines()]
import jieba
import time
train_df.columns = ['分类', '文章']
stopword_list = [k.strip() for k in open('stopwords.txt', encoding='utf8').readlines() if k.strip() != '']
cutWords_list = []
i = 0
startTime = time.time()
for article in train_df['文章']:
cutWords = [k for k in jieba.cut(article) if k not in stopword_list]
i += 1
if i % 1000 == 0:
print('前%d篇文章分词共花费%.2f秒' %(i, time.time()-startTime))
cutWords_list.append(cutWords)

with open('cutWords_list.txt', 'w') as file:
for cutWords in cutWords_list:
file.write(' '.join(cutWords) + '\n')
with open('cutWords_list.txt') as file:
cutWords_list = [k.split() for k in file.readlines()]
#特征工程
X = tfidf.fit_transform(train_df[1])
print('词表大小:', len(tfidf.vocabulary_))
print(X.shape)
运行结果:
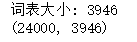
#调用sklearn.preprocessing库的LabelEncoder方法对文章分类做标签编码。
#最后一行代码查看预测目标的形状。
from sklearn.preprocessing import LabelEncoder
import pandas as pd
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
labelEncoder = LabelEncoder()
y = labelEncoder.fit_transform(train_df[0])
y.shape
运行结果:
#调用sklearn.linear_model库的LogisticRegression方法实例化模型对象。
#调用sklearn.model_selection库的train_test_split方法划分训练集和测试集。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2)
logistic_model = LogisticRegression(multi_class='multinomial', solver='lbfgs')
logistic_model.fit(train_X, train_y)
logistic_model.score(test_X, test_y)
运行结果:
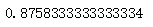
#保存模型需要先安装pickle库,安装命令:pip install pickle
#调用pickle库的dump方法保存模型,需要2个参数。
#第1个参数是保存的对象,可以为任意数据类型,因为有3个模型需要保存,所以下面代码第1个参数是字典。
#第2个参数是保存的文件对象,数据类型为_io.BufferedWriter
import pickle
with open('tfidf.model', 'wb') as file:
save = {
'labelEncoder' : labelEncoder,
'tfidfVectorizer' : tfidf,
'logistic_model' : logistic_model
}
pickle.dump(save, file)
#调用pickle库的load方法加载保存的模型对象
import pickle
with open('tfidf.model', 'rb') as file:
tfidf_model = pickle.load(file)
tfidfVectorizer = tfidf_model['tfidfVectorizer']
labelEncoder = tfidf_model['labelEncoder']
logistic_model = tfidf_model['logistic_model']
#调用pandas的read_csv方法加载训练集数据。
#调用TfidfVectorizer对象的transform方法获得特征矩阵。
#调用LabelEncoder对象的transform方法获得预测目标值。
import pandas as pd
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
X = tfidfVectorizer.transform(train_df[1])
y = labelEncoder.transform(train_df[0])
```python
#调用sklearn.linear_model库的LogisticRegression方法实例化逻辑回归模型对象。
#调用sklearn.model_selection库的ShuffleSplit方法实例化交叉验证对象。
#调用sklearn.model_selection库的cross_val_score方法获得交叉验证每一次的得分。
#最后打印每一次的得分以及平均分
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import cross_val_score
logistic_model = LogisticRegression(multi_class='multinomial', solver='lbfgs')
cv_split = ShuffleSplit(n_splits=5, test_size=0.3)
score_ndarray = cross_val_score(logistic_model, X, y, cv=cv_split)
print(score_ndarray)
print(score_ndarray.mean())
运行结果:
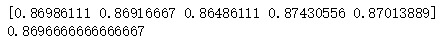
#绘制混淆矩阵
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegressionCV
from sklearn.metrics import confusion_matrix
import pandas as pd
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2)
logistic_model = LogisticRegressionCV(multi_class='multinomial', solver='lbfgs')
logistic_model.fit(train_X, train_y)
predict_y = logistic_model.predict(test_X)
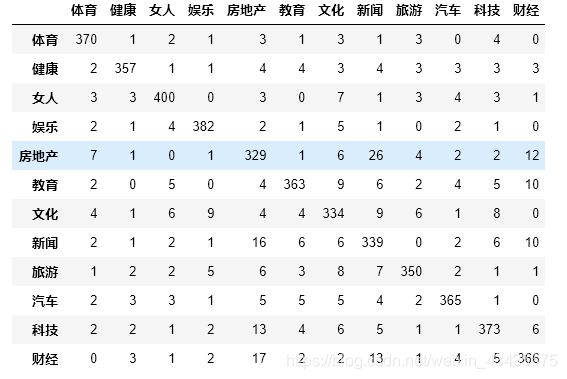
pd.DataFrame(confusion_matrix(test_y, predict_y),
columns=labelEncoder.classes_,
index=labelEncoder.classes_)
运行结果:
#绘制precision、recall、f1-score、support报告表
import numpy as np
from sklearn.metrics import precision_recall_fscore_support
def eval_model(y_true, y_pred, labels):
# 计算每个分类的Precision, Recall, f1, support
p, r, f1, s = precision_recall_fscore_support(y_true, y_pred)
# 计算总体的平均Precision, Recall, f1, support
tot_p = np.average(p, weights=s)
tot_r = np.average(r, weights=s)
tot_f1 = np.average(f1, weights=s)
tot_s = np.sum(s)
res1 = pd.DataFrame({
u'Label': labels,
u'Precision': p,
u'Recall': r,
u'F1': f1,
u'Support': s
})
res2 = pd.DataFrame({
u'Label': ['总体'],
u'Precision': [tot_p],
u'Recall': [tot_r],
u'F1': [tot_f1],
u'Support': [tot_s]
})
res2.index = [999]
res = pd.concat([res1, res2])
return res[['Label', 'Precision', 'Recall', 'F1', 'Support']]
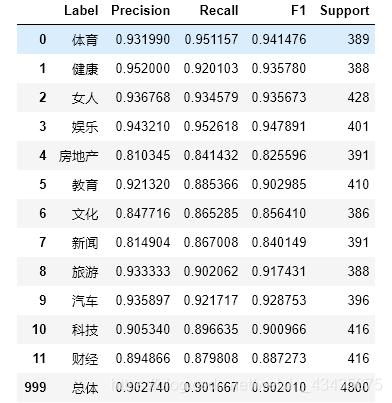
predict_y = logistic_model.predict(test_X)
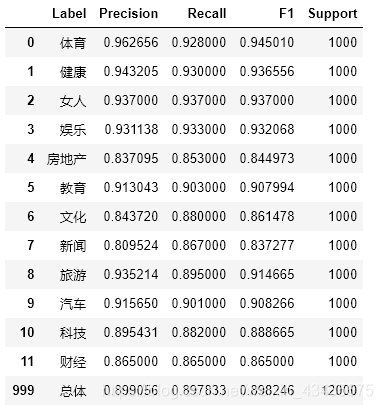
eval_model(test_y, predict_y, labelEncoder.classes_)
运行结果:
#模型测试,即对一个全新的测试集进行预测。
#调用pandas库的read_csv方法读取测试集文件。
#调用TfidfVectorizer对象的transform方法获得特征矩阵。
#调用LabelEncoder对象的transform方法获得预测目标值
import pandas as pd
test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
test_X = tfidfVectorizer.transform(test_df[1])
test_y = labelEncoder.transform(test_df[0])
predict_y = logistic_model.predict(test_X)
eval_model(test_y, predict_y, labelEncoder.classes_)
运行结果:
所属网站分类: 技术文章 > 博客
作者:vike
链接:https://www.pythonheidong.com/blog/article/8291/ec1506a55fc5fa1c9137/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力