

获取pm2.5历史数据,爬虫AQI爬取https://www.aqistudy.cn/historydata/
发布于2019-08-07 10:24 阅读(6634) 评论(3) 点赞(5) 收藏(7)
网站:https://www.aqistudy.cn/historydata/

前言:
pm2.5的数据源比较多,但是历史数据比较少,很多网站不是很全,如图,这个网站的数据在同类网站中是算比较全面的了,界面也很简约清晰。一开始我爬取这个网站的时候看到网页结构很简单以为简单的构造请求就可以爬取数据了。没想到打开开发者工具后,发现其日数据是通过js加密解密加载到页面上的。
对于这样的网站第一反应是通过selenium用浏览器脚本对每个页面进行逐一加载。但是如果爬取的数据量很大,比如全国范围。逐一加载的时间开销比较大。我第一次爬取的时候就是通过开多线程用selenium爬取的,即使是开了多线程,速度还是不尽如人意。前后花了两个小时才把所有数据爬下来。所以这并不是完美的解决方式。
分析过程:
一个网站,要想把数据加载到页面上,无非是通过js 或者一些模板。我们先来逐一分析该网站的数据加载过程,如图
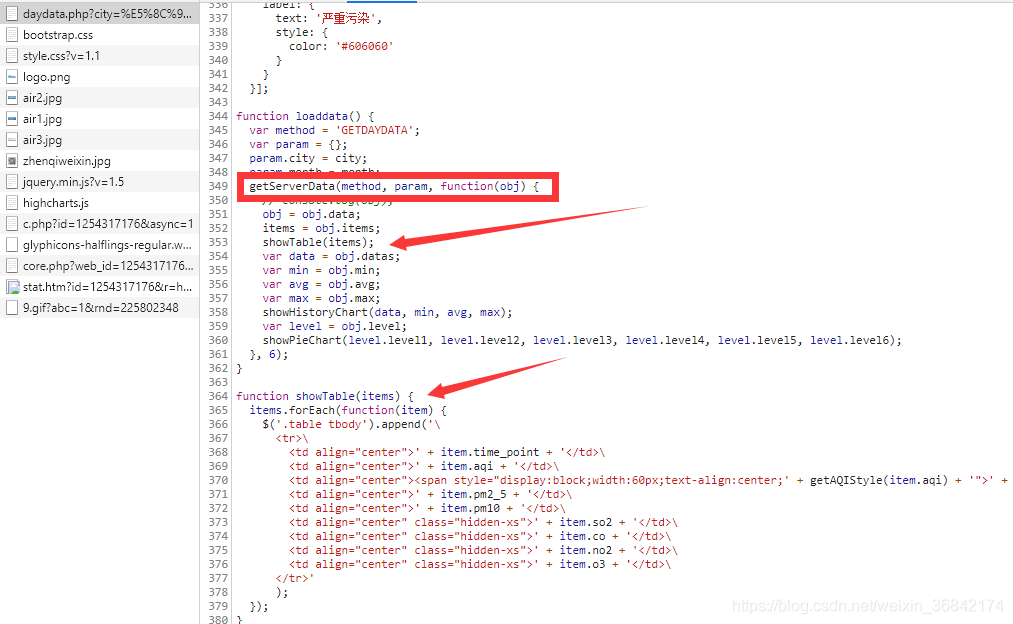
getServerData()获取数据后通过showTable()加载到页面上,整体来说还是比较常规的操作。可是在当前文件是找不到getServerData()的代码具体实现的。我们继续找其他js文件:通过搜索,我们在jquery.min.js中找到了类似的字段。
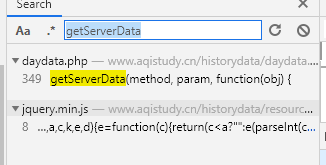
但是不要高兴的太早。我们发现,
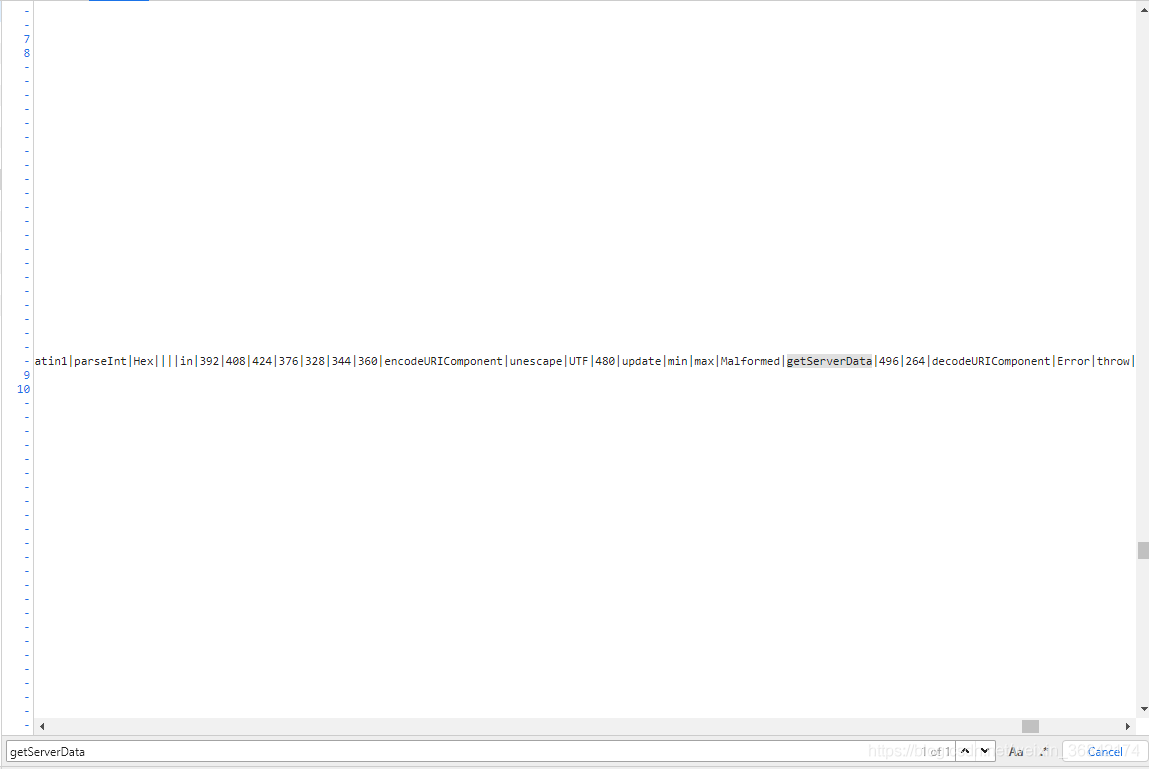
该方法是混淆在js代码中的。现在我要找反混淆工具。把真正的代码找出来。
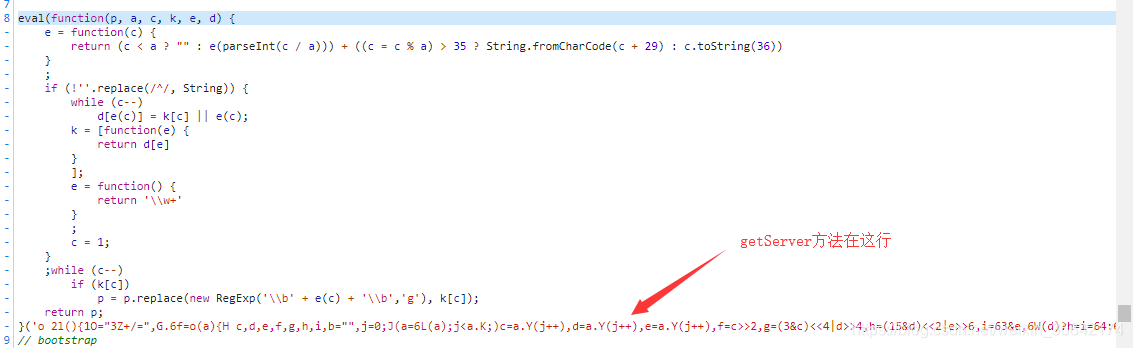
我们把截图中eval到注释部分的代码复制出来。然后找一个反混淆工具。我用的是这个:
http://www.bm8.com.cn/jsConfusion/
然后得到原本的js代码,复制保存到文本文件
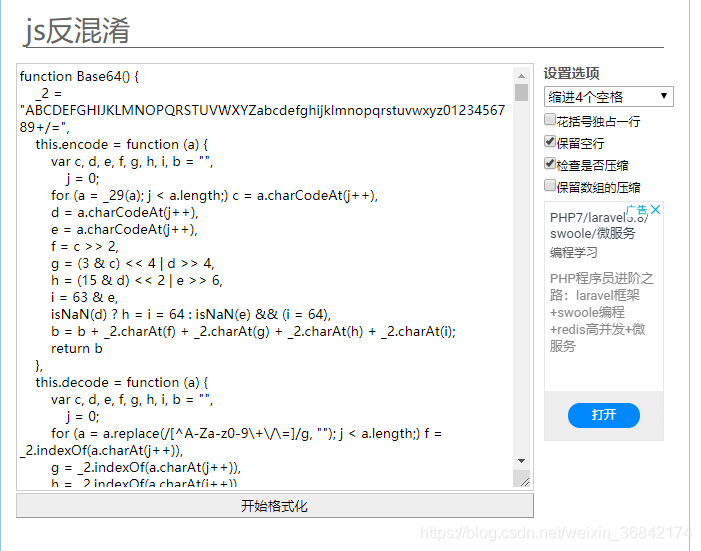
分析该js文件。。。。( 下图是完整的getServerData() )

我们发现该请求的参数和response都经过了加密解密。看到这里我们可以用execjs调用其中的加密解密方法,构造请求。就可以获取到我们需要的数据。
参数加密过程:
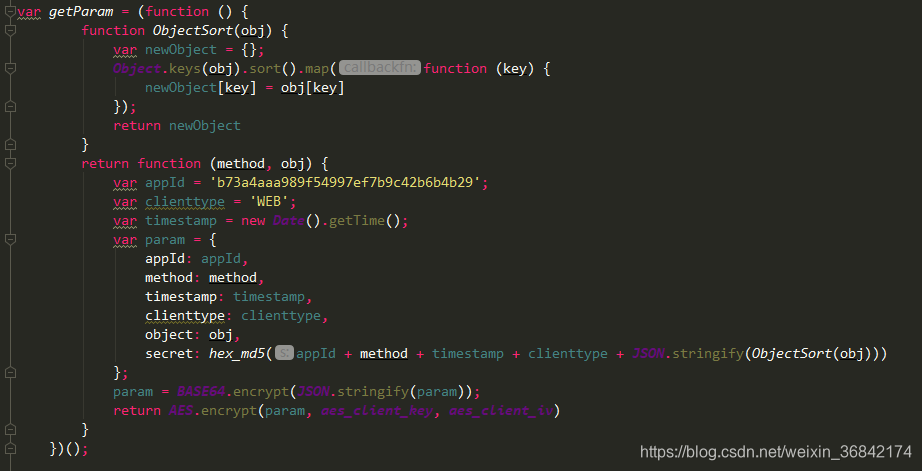
从图中可以看的很明白了,过程比较繁琐,没必要用python去实现一遍不如直接调用js方法。
response解密过程:
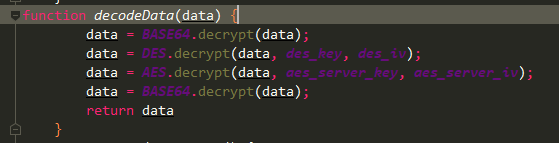
base64解码 》DES解码》AES解码》base64解码
这些方法都可以在该js中找到。有兴趣的可以去慢慢了解下。
下面是完整爬虫,爬取一个城市所有的历史数据:(js代码太多了就放github了)
代码地址:https://github.com/Crack-DanShiFu/apiStudy
- import json
- from lxml import etree
- import execjs
- import requests
-
-
- # 获取一个城市所有的历史数据 by lczCrack qq1124241615
-
- # 加密参数
- def encryption_params(city, date_time, ctx):
- method = 'GETDAYDATA'
- js = 'getEncryptedData("{0}", "{1}", "{2}")'.format(method, city, date_time)
- return ctx.eval(js)
-
-
- # 解码response对象
- def decode_info(info, ctx):
- js = 'decodeData("{0}")'.format(info)
- data = ctx.eval(js)
- data = json.loads(data)
- return data
-
-
- def get_response(params):
- url = 'https://www.aqistudy.cn/historydata/api/historyapi.php'
- headers = {
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
- 'Accept-Encoding': 'gzip, deflate',
- 'Accept-Language': 'zh-CN,zh;q=0.8',
- 'Content-Type': 'application/x-www-form-urlencoded',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'
- }
- data = {
- 'hd': params
- }
- html_info = requests.post(url, data=data)
- return html_info.text
-
-
- def get_city():
- url = 'https://www.aqistudy.cn/historydata/'
- html_info = requests.get(url)
- html = etree.HTML(html_info.text) # 初始化生成一个XPath解析对象
- items = html.xpath('//div[@class="all"]//a/text()')
- return items
-
-
- def get_all_info_by_city(city):
- years = [str(i + 2013) for i in range(7)]
- month = [str(i if i > 9 else '0' + str(i)) for i in range(1, 13)]
- node = execjs.get()
- ctx = node.compile(open('decrypt.js', encoding='utf-8').read())
- for y in years:
- for m in month:
- date_time = y + m # 201805
- html_info = get_response(encryption_params(city, date_time, ctx))
- item = decode_info(html_info, ctx)
- for i in item['result']['data']['items']:
- print(i)
-
-
- if __name__ == '__main__':
- get_all_info_by_city('北京')
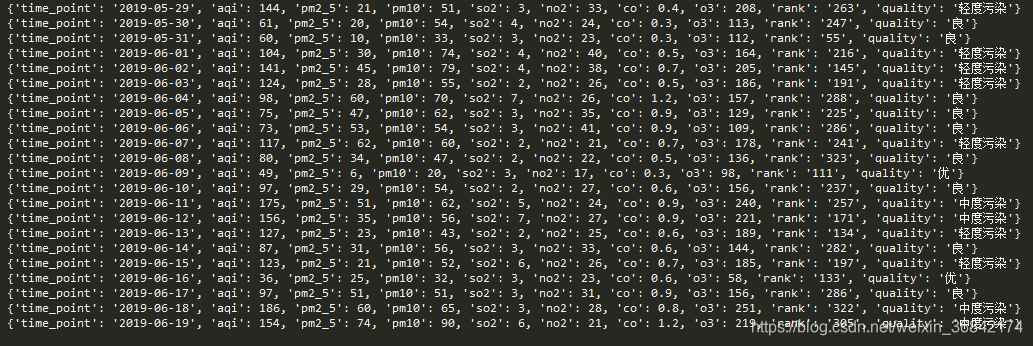
结果:
所属网站分类: 技术文章 > 博客
作者:我不喜欢上班
链接:https://www.pythonheidong.com/blog/article/9801/33bb9b101ee2d6158136/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力