

python常用的一些技巧
发布于2019-09-06 12:39 阅读(660) 评论(0) 点赞(11) 收藏(1)
1、三目操作符
2、鸭子类型(duck typing)
首先Python不支持多态,也不用支持多态,python是一种多态语言,崇尚鸭子类型。以下是维基百科中对鸭子类型得论述:
在程序设计中,鸭子类型(英语:duck typing)是动态类型的一种风格。在这种风格中,一个对象有效的语义,不是由继承自特定的类或实现特定的接口,而是由当前方法和属性的集合决定。这个概念的名字来源于由James Whitcomb Riley提出的鸭子测试,“鸭子测试”可以这样表述:
“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
在鸭子类型中,关注的不是对象的类型本身,而是它是如何使用的。
例如,在不使用鸭子类型的语言中,我们可以编写一个函数,它接受一个类型为鸭的对象,并调用它的走和叫方法。在使用鸭子类型的语言中,这样的一个函数可以接受一个任意类型的对象,并调用它的走和叫方法。如果这些需要被调用的方法不存在,那么将引发一个运行时错误。任何拥有这样的正确的走和叫方法的对象都可被函数接受的这种行为引出了以上表述,这种决定类型的方式因此得名。
鸭子类型通常得益于不测试方法和函数中参数的类型,而是依赖文档、清晰的代码和测试来确保正确使用。从静态类型语言转向动态类型语言的用户通常试图添加一些静态的(在运行之前的)类型检查,从而影响了鸭子类型的益处和可伸缩性,并约束了语言的动态特性(鸭子类型应避免使用type()或isinstance()等测试类型是否合法)。正在上传...
in_the_forest()函数对参数duck只有一个要求:就是可以实现quack()和feathers()方法。然而Duck类和Person类都实现了quack()和feathers()方法,因此它们的实例对象donald和john都可以用作in_the_forest()的参数,这就是鸭子类型。
可以看出,鸭子类型给予Python这样的动态语言以多态。但是这种多态的实现完全由程序员来约束强制实现(文档、清晰的代码和测试),并没有语言上的约束(如C++继承和虚函数)。因此这种方法既灵活,又提高了对程序员的要求。
3、内建函数和lamda
需求:将一个字符串列表中所有满足包含“result"字段的字符串筛选出来。
4、iterator和generator
generator返回不用return,而用yield。
iterator实现了next()方法和__iter__,__iter__方法返回它自己。而当你调用next()方法时,会返回一个值。通常,这个next值会由generator产生。
换种说法,generator是用来生成iterator的。
那么iterator呢?generator就是用来生成iterator的:
应用的场景:下一次返回的结果依赖于上一次返回的结果。因为yield的作用是每次函数调用执行到这里就停止了,下次调用从yield后面的语句开始。比如说树的遍历之类的。
5、bind
bind应用的场景:你写一个好多参数的函数,先bind一个参数,变成函数A,然后换种方式bind,又变成了函数B。
介绍一个库是functools,这里只介绍跟bind相似的partial方法。
6、修饰器
1)decorator
修饰器的本质就是对函数做些修饰,然后返回一个函数(callable object)。也就是所谓的高阶函数。因此上面的式子直白的写出来就是:
foo = log(foo)
foo其实就是一个log返回的callable object wrap的别名。
如果需要这样的修饰器,我们应该怎么写呢?
先把(1,2)传给decro,然后把foo传给decro;然后你返回给我一个能接受(*args,**kargs)参数的函数:
一定要记住,foo是一个callable object。
2)wraps
试试打印下foo函数: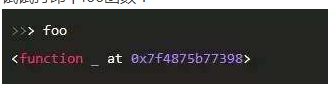
不是foo么,怎么变成"_"了?
这个时候需要前一节提到的functools,然后对你的decorator做一点小小的改动:
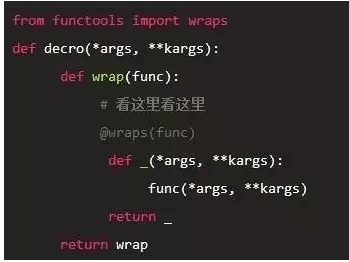
7、description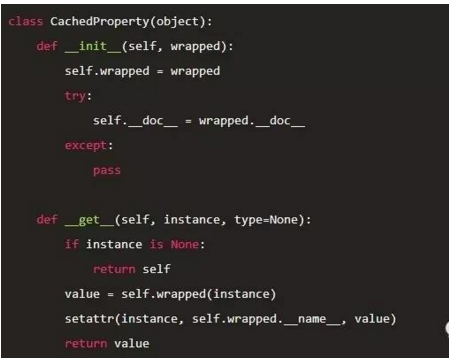
包含内置方法:
1. python有三个内置函数,__set__、__get__、__delete__;
2. 只定义__get__方法,非数据描述器(non-data descriptor);
3. 定义了__delete__ 或者 __set__ 方法的叫做数据描述器(data descriptor);
以字典为例: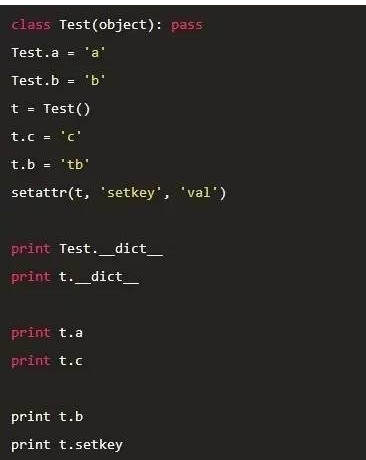
输出如下: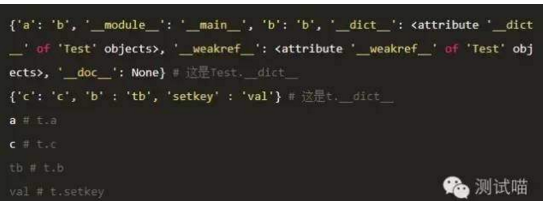
这个例子说明几点:
1. 对象和类都有个字典:__dict__
2. 在对象中查找不到的属性,会从类中查找 (t.a)
3. 对象中属性的优先级高于类中的优先级 (t.b)
4. 设置属性(set)的时候,会在对应的dict里增加元素 (Test.a =xxx, t.b = xxx)
5. setattr 跟 '=' 操作符,操作对象的属性时,看起来作用是一样的。
通常的情况下,属性查找如此简单:先找对象的__dict__,然后再找类的__dict__;都找不到就抛异常;
当加入所谓的descriptor的时,事情变得稍微复杂了一点点。对于一个对象的属性,新的顺序是:
1. python自动属性 (python自动生成的属性,比如__doc__等)
2. 在类(及其祖先类)的__dict__中查找data descriptor,如果存在,返回data descriptor中__get__方法调用的结果
3. 在对象的__dict__中查找
4. 在类(及其祖先类)的__dict__中查找non-data descriptor,存在则返回对应__get__调用的结果
5. 在类(及其祖先类)的__dict__中查找普通属性
这样,在原来的属性查找顺序上,我们加上了non-data descriptor和data descriptor,分别插在2、4的位置上。
回到1)中的例子,然后再看看2)中的定义,有木有发现,这其实就是一个descriptor。这个CacheProperty有什么作用呢? 看下面一个使用场景(这个栗子也来自clang python binding):
Config定了一个lib方法,这个方法做一些相对耗时的操作才能获得我们想要的lib对象。比如说加载配置文件:有没有办法可以做到只在第一次调用的时候加载配置文件,其他的时候都从缓存里读呢?
看CacheProperty 的实现:
1 首先它是一个non-data descriptor;
2. 第一次的时候,按照4)所述的查找顺序,
2.1 由于Config和其对象的__dict__中没有lib,它会走到第4步;
2.2 然后开始执行__get__方法,该方法调用lib方法,计算出lib的值value=self.wrapped(instance) (这个wrap方法在CacheProperty __init__方法中被设置self.wrapped = wrapped, 此时wrapped就是lib方法);
2.3 随后调用setattr方法,将计算到的值set到对象的__dict__中
3. 之后调用的时候,由于对象的__dict__中已经有这个key了。直接返回对应的值就可以了。
这只是个non-data descriptor的例子,它验证了属性查找中non-data descriptor顺序的正确性。
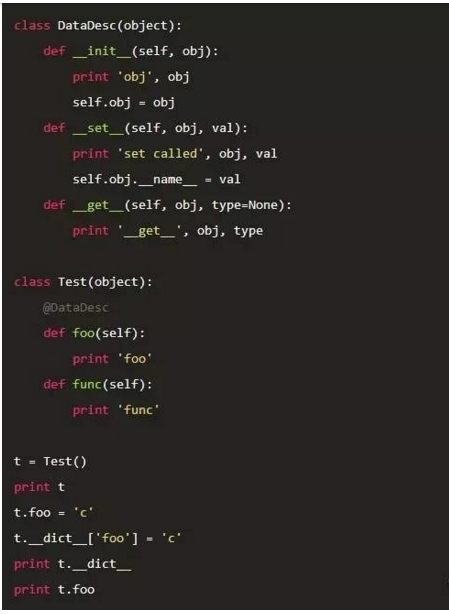
对于data descriptor属性查找,可以参看下面一个例子:
学好python你需要一个良好的环境,一个优质的开发交流群,群里都是那种相互帮助的人才是可以的,我有建立一个python学习交流群,在群里我们相互帮助,相互关心,相互分享内容,这样出问题帮助你的人就比较多,群号是301,还有056,最后是069,这样就可以找到大神聚合的群,如果你只愿意别人帮助你,不愿意分享或者帮助别人,那就请不要加了,你把你会的告诉别人这是一种分享。如果你看了觉得还可以的麻烦给我点个赞谢谢
所属网站分类: 技术文章 > 博客
作者:python是我的菜
链接:https://www.pythonheidong.com/blog/article/98789/a756a0d8b5416c50f6c7/
来源:python黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力